
A Beginner’s Guide to Observability
Download this e-book for a complete introduction to Observability.
Key takeaways
Your organization is complicated. Knowing how your technology and solutions support your users doesn't have to be.
Monitoring applications and ensuring they're performing as expected is crucial for business and mission-critical success. This is where application performance monitoring (APM) comes in.
APM technology monitors business applications to make sure all services are available with minimal downtime. This is all to ensure your customers, and internal employees and stakeholders, have a positive experience.
In this comprehensive article, we're going to learn what application performance monitoring is, how it works, and how it benefits businesses today.
Application performance monitoring (APM) is a technology approach that provides real-time information about how your software applications are performing. With a comprehensive view into application health and availability, APM can do things like:
Both the importance and the usage of APM has grown in recent years. That’s because companies rely on increasingly complex applications to run their businesses. The more complex the systems, the more opportunities for things to go wrong.
Application performance monitoring and application performance management are often used interchangeably, but there's a slight difference between the two.
Monitoring is actually a component of management. And with one eye on certain measurements and metrics, management is really about managing and improving your overall application performance strategy.

A comprehensive term, application performance monitoring looks at a variety of factors that can help or hurt how a given app or system is performing. Managing all that complexity isn’t easy on your own, which is where APM solutions come into play. Organizations rely on APM for a variety of reasons:
This support is crucial, particularly for organizations working across distributed systems and deploying software via modern, agile frameworks. With near-constant changes, APM software helps to ensure that your software meets business objectives and user expectations.
(Learn about Splunk APM and achieve end-to-end visibility.)
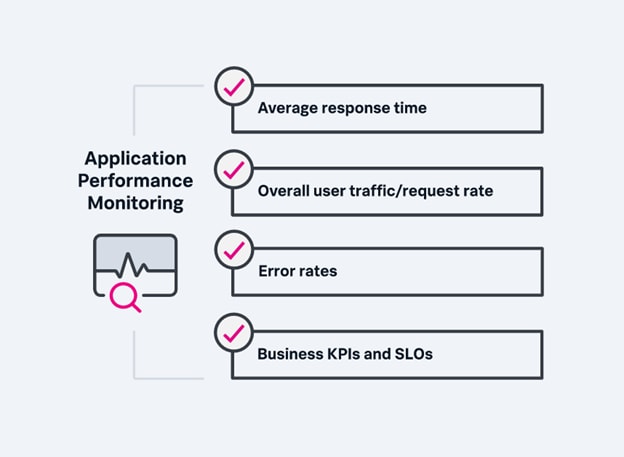
APM involves tracking key metrics and diagnosing issues within an application by monitoring performance in real time, usually using a combination of analytics platforms, agents, and instrumentation. Let's take a closer look at the mechanics, exactly how APM can do this.
APM systems and tools traditionally rely on small software components ("agents") installed within an application or its environments. These agents collect performance data from different parts of the application. Useful performance data can include:
This data helps your IT teams to understand how different parts of an application interact and to identify bottlenecks.
(Related reading: monitoring for rate, error, duration aka RED monitoring.)
APM systems aggregate the collected data into a dashboard, where you can see performance metrics like service availability, throughput, error rates, and response times.
Here, you can also set thresholds for each metric, so when those are breached, alerts get triggered. Appropriate alerts, without too much noise, mean teams can take action to resolve the issue before it escalates widely.
APM tools also capture traces and logs.
This data is then analyzed to identify the root cause of performance issues.
(Related reading: metrics, events, logs and traces, aka MELT.)
Traditional monitoring relied on agents. Today's modern APM solutions, however, use agentless monitoring.
Agentless monitoring is a non-intrusive method of collecting metrics and monitoring the application's health and performance. It relies on network traffic analysis to collect performance data.
Agentless monitors are easy to deploy since you don't need to install and manage agents across different environments. Plus, they're ideal for monitoring external services and third-party APIs where installing agents isn't possible.
Synthetic monitoring is another aspect of APM. Synthetic monitoring simulates (pretends) user interactions to test the application's performance.
By running predefined tests, synthetic monitoring helps detect problems like broken links and slow page load times. This complements real user monitoring, since it can help identify issues that weren't triggered during actual, normal user activity.
(Related reading: synthetic monitoring vs. RUM.)
APM brings a slew of benefits that can profoundly impact the technical and business facets of operations. Let's explore these pluses!
Instead of reacting to issues after they’ve occurred, APM allows organizations to be proactive. With modern APM, you can identify and address potential problems before they impact users or business operations.
APM tools detect real-time anomalies by setting performance baselines and continuously monitoring application health. Automated alerts notify relevant teams of potential issues, enabling rapid response. This proactive approach reduces downtime and ensures consistent application availability.
(Explore incident response metrics.)
At its core, APM aims to ensure the application provides an optimal end-user experience. APM tools gauge user satisfaction and identify improvement areas by tracking information like:
Any lag, error, or bottleneck can be promptly addressed, ensuring users have a seamless and efficient experience, increasing customer retention and positive brand perception. After all, satisfied customers have no reason to stop using your products and services.
APM provides insights into how resources — like cloud services, servers, and databases — are leveraged by applications, which helps you better manage your IT resources.
With good APM tooling, you can get insights into which parts of an application are resource-intensive or underutilized. This information can help you make smart decisions about load balancing, scaling, and infrastructure investments. Of course, this right-sizing ensures that resources are neither wasted nor stretched thin, leading to cost savings and optimized application performance.
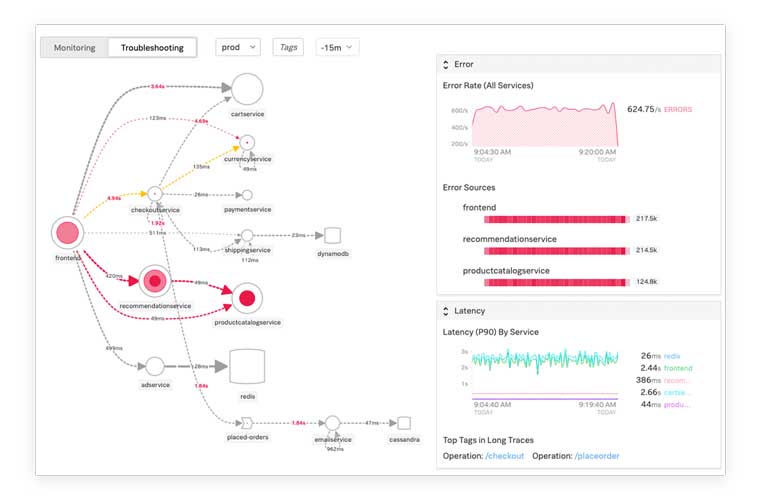
APM tools aggregate vast amounts of data, offering actionable insights that drive strategic decisions.
Through APM's comprehensive analytics and reporting, companies understand application performance trends, user behavior patterns, and infrastructure health. These data points form the basis for making informed decisions about software updates, infrastructure changes, or business strategies.
SLAs are the formally required level of service that the client and IT service provider agree upon. APM tools monitor performance metrics like response time and service availability in SLA frameworks, allowing providers to make sure that they meet expectations.
APM can also highlight areas that need to be improved in order to stay above/inside the agreed SLA standards.
It’s important to point this out: APM offers much more than merely a technical perspective — APM provides a holistic view that intertwines technical performance with business outcomes.
The benefits of proactive problem resolution, enhanced user experience, optimized resource allocation, and data-driven decision-making ensure that organizations can leverage their applications effectively to meet both user expectations and business goals.
The world of APM is vast, and its utility is structured around several core components. Let’s delve into these components in detail.
The EUEM component gauges real users' experience when interacting with an application, ensuring that the software meets or exceeds user expectations. Techniques inside APM offer different views. For example:
The primary goal is to understand how users perceive the application and where bottlenecks or lags might affect their experience.
Discovery and modeling are about understanding and visualizing how different parts of an application communicate and depend on each other.
APM tools dynamically map out application components and their interactions, highlighting dependencies. This provides clear visualization, like topology graphs and dependency maps, aiding teams in understanding the intricate workings of the application and how changes in one component might impact others.
Transaction profiling allows organizations to tailor monitoring to specific transactions or interactions they deem critical. Instead of general IT monitoring, user-defined transaction profiling offers granular insights into specific transactions as they flow through various application components. This detailed view aids in understanding the behavior of essential features or functions, ensuring they perform optimally.
This component offers a granular view of individual application components at the code level. When performance issues arise, it’s critical to identify the root cause quickly. This component allows teams to delve into application elements, including:
This way, teams can implement targeted solutions without affecting unrelated parts of the application — after all, they now know exactly where the bottleneck or error occurred.
A core function of APM tools, this component aggregates the vast amount of data captured and presents it in a digestible, actionable format.
APM tools consolidate data from various monitoring touchpoints, producing comprehensive reports, dashboards, and visualizations. This provides a holistic view of application health and aids in: spotting trends, predicting potential future issues, and making informed decisions based on historical and real-time data.
Even the most effective monitoring methods require foundational knowledge to increase the likelihood of success. APM is no different. Keep the following in mind when developing your app and infrastructure monitoring strategy.
There are many options available in the APM market, and each has their own set of features for monitoring performance. Focus on a solution that will allow you to get a total picture of the IT environment while connecting key business transactions to business outcomes. Cover the basics with an APM solution that:
Relying on end users for quality assurance leads to issues like customer dissatisfaction and high mean-time-to-resolution (MTTR). A proactive approach to performance monitoring saves time and money. Tracking availability, response time, errors, and downtime provide insights into user experience and service quality. Application Performance Monitoring (APM) helps assess application health continuously and automatically, without disrupting users.
The best performing APM solutions are configured to address the unique challenges and obstacles faced by your business. Create rules regarding normal app behavior or what deviates from an SLA, prioritizing business-critical applications, or for monitoring problems in specific areas or against certain benchmarks.
The key players involved with deploying APM should know your app from end to end and should be able to identify and mitigate problems efficiently and effectively. End-user experience monitoring is a core component of future growth and success. A well-trained team who understands the nuanced IT environment and the importance of performance monitoring is one of the most valuable investments your business can make.
With the vast array of APM tools available today, picking the right one for your business can be overwhelming. It’s critical to find a comprehensive, unbiased comparison that weighs various organizations' challenges, goals, and needs.
Gartner® Magic Quadrant™ research methodology and graphical representation offers a visual snapshot of a variety of technologies and industry tools, including the given market's participants, maturity, and direction. Designed to provide a clear and unbiased evaluation of software vendors within the APM space, this quadrant aids business leaders in selecting the best suited APM solution for their unique needs.
For our purposes here, there's a Magic Quadrant that aligns perfectly with APM solutions. Formally known as the Magic Quadrant for APM, Gartner renamed this category in 2024 to the Gartner® Magic Quadrant™ for Observability Platforms. As in all Magic Quadrants, there are four categories: Leaders, Challengers, Visionaries, and Niche Players. These categories assess vendors based on two primary criteria:
The resulting quadrant, available for free download, gives organizations a comprehensive view of the APM landscape, highlighting both industry stalwarts and emerging contenders.
Some APM tools use machine learning and artificial intellgience to:
AI and ML can also be used to forecast future bottlenecks based on historical trends and filter out irrelevant alerts.
Cloud-native applications are more challenging to monitor because of their unique architecture and highly dynamic environments, where services are scaled up or down based on demand. They often use a microservices architecture where the application is broken down into smaller, independent services.
Since there are so many services to track, each with its own failure points and performance metrics, monitoring becomes difficult. Plus, the services might be distributed across multiple regions or nodes, which further complicates monitoring.
Fortunately, modern APM solutions like those from Splunk are purpose-built to handle exactly the complexity of large, international enterprises.
Application performance monitoring stands at the crossroads of technology excellence and optimal user experience. Today, where digital interactions define business success and customer loyalty, ensuring seamless application performance is non-negotiable.
APM tools provide organizations with the insights, proactive problem-solving, and data-driven strategies they need to meet and exceed user expectations consistently.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.