
splunk observability
Splunk IT Service Intelligence
Turn alert noise into actionable event intelligence, connecting technical performance to the business impact of service health.
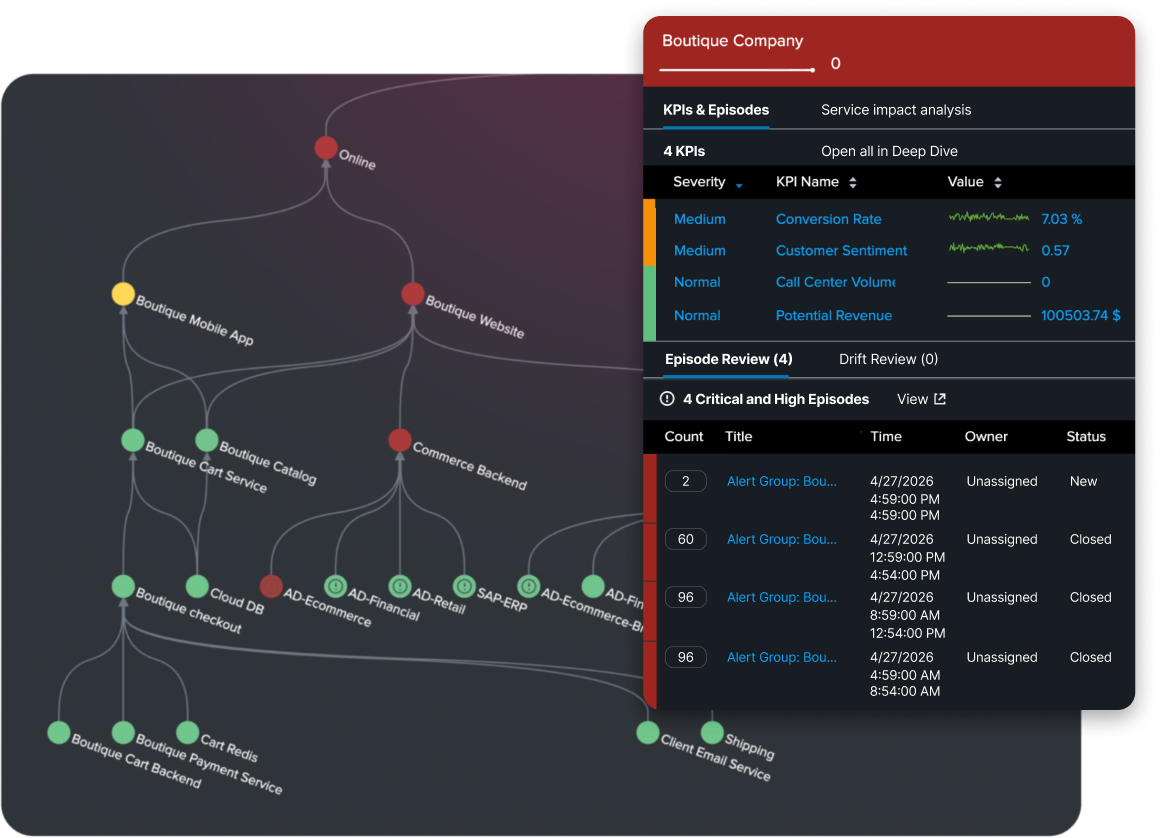
Turn alert noise into insights and connect performance to business impact
Correlate networks with apps and infrastructure in one operational view
Bring network telemetry together with application and infrastructure data already in Splunk and across your monitoring stack. Teams get one cross-domain view to reduce blind spots, speed fault isolation, and spend less time switching between tools.
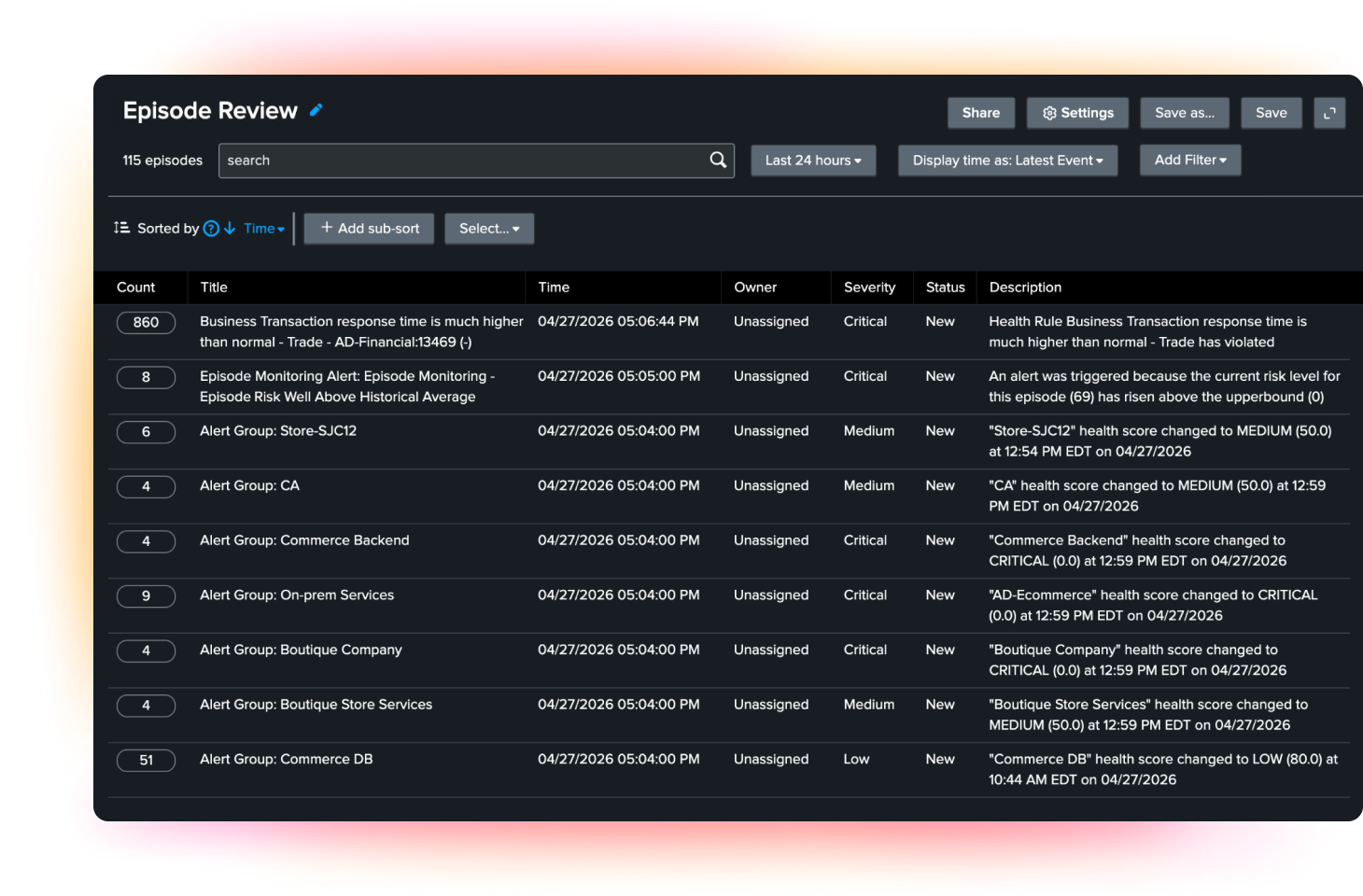
Onboard alerts in minutes with zero-touch event analytics
Zero-touch event analytics uses built-in integrations and AI-driven field discovery to onboard, map, and enrich alerts in minutes. Teams spend less time normalizing raw events and more time working from consistent, actionable data across their monitoring ecosystem.
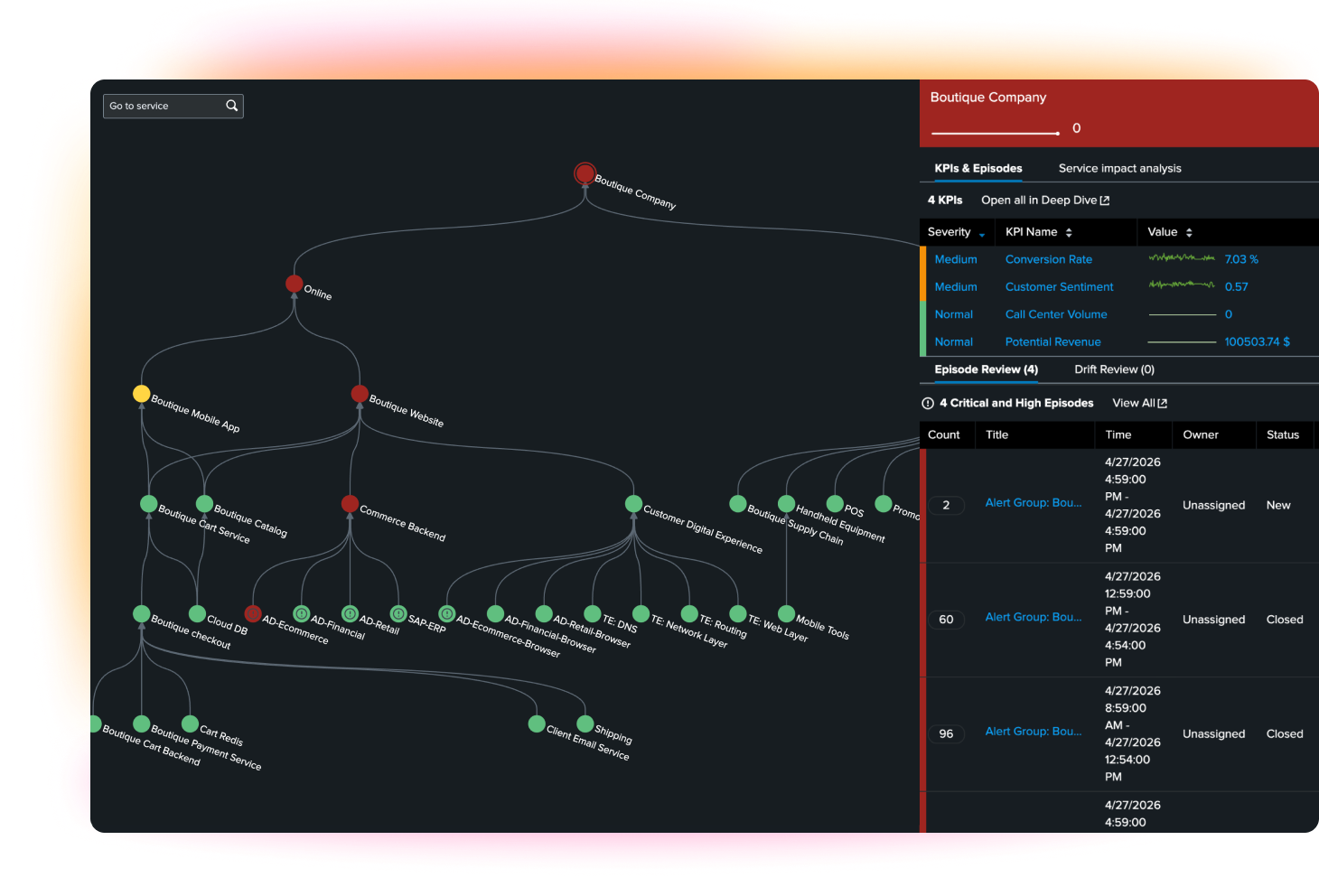
Turn related alerts into actionable episodes with AIOps event correlation
Event iQ applies AIOps-driven event correlation, topology, and fuzzy matching to group related alerts into episodes. Instead of chasing dozens of disconnected notifications, operators can focus on a smaller set of incidents with stronger context, clearer priority, and faster paths to resolution.
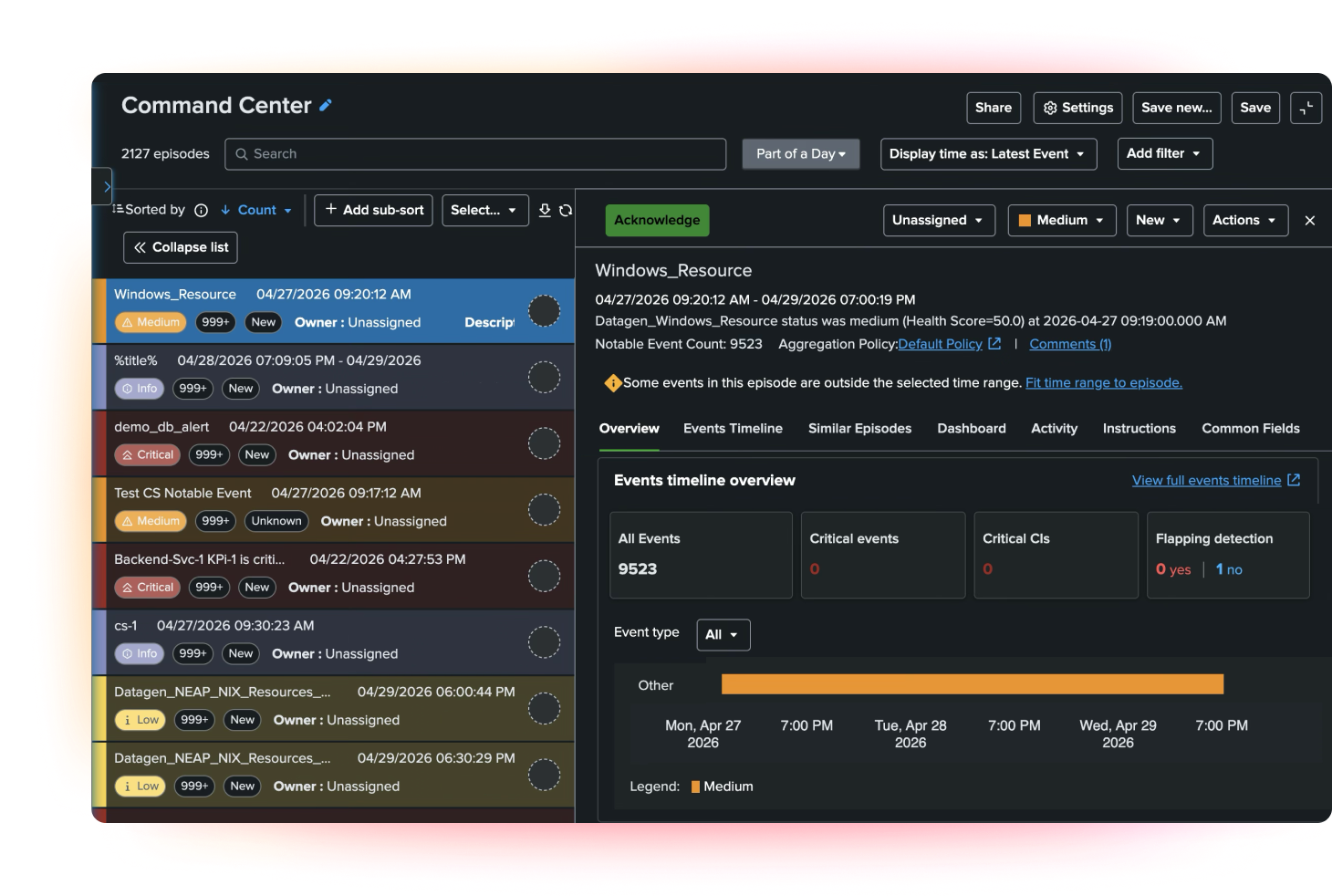
Speed root cause analysis with AI and change context
Cause iQ adds AI-generated episode summaries, confidence-based root cause guidance, and change context from tools like ServiceNow and Jira. Teams can quickly understand what changed, where to investigate next, and how to move from triage to resolution with less guesswork.
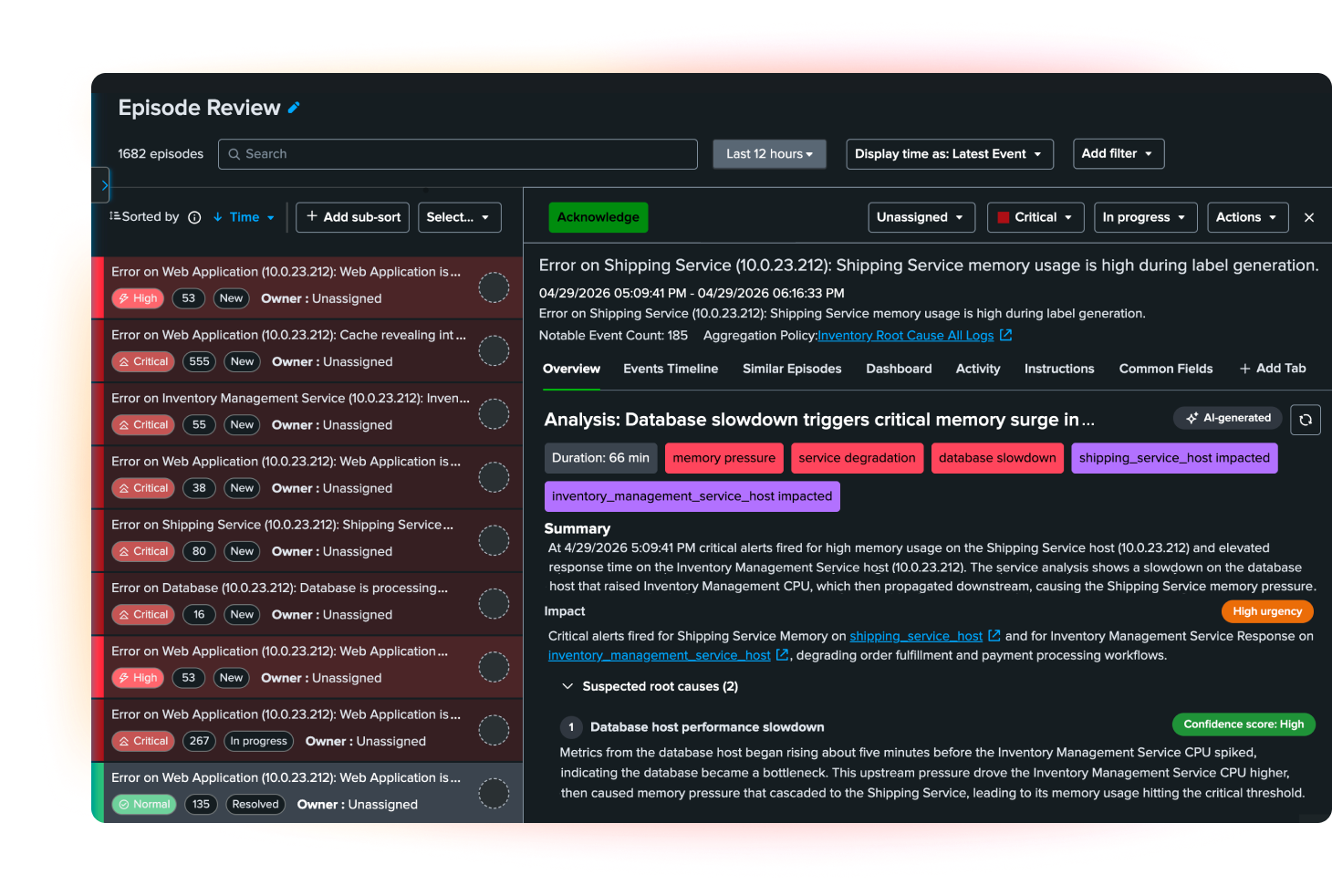
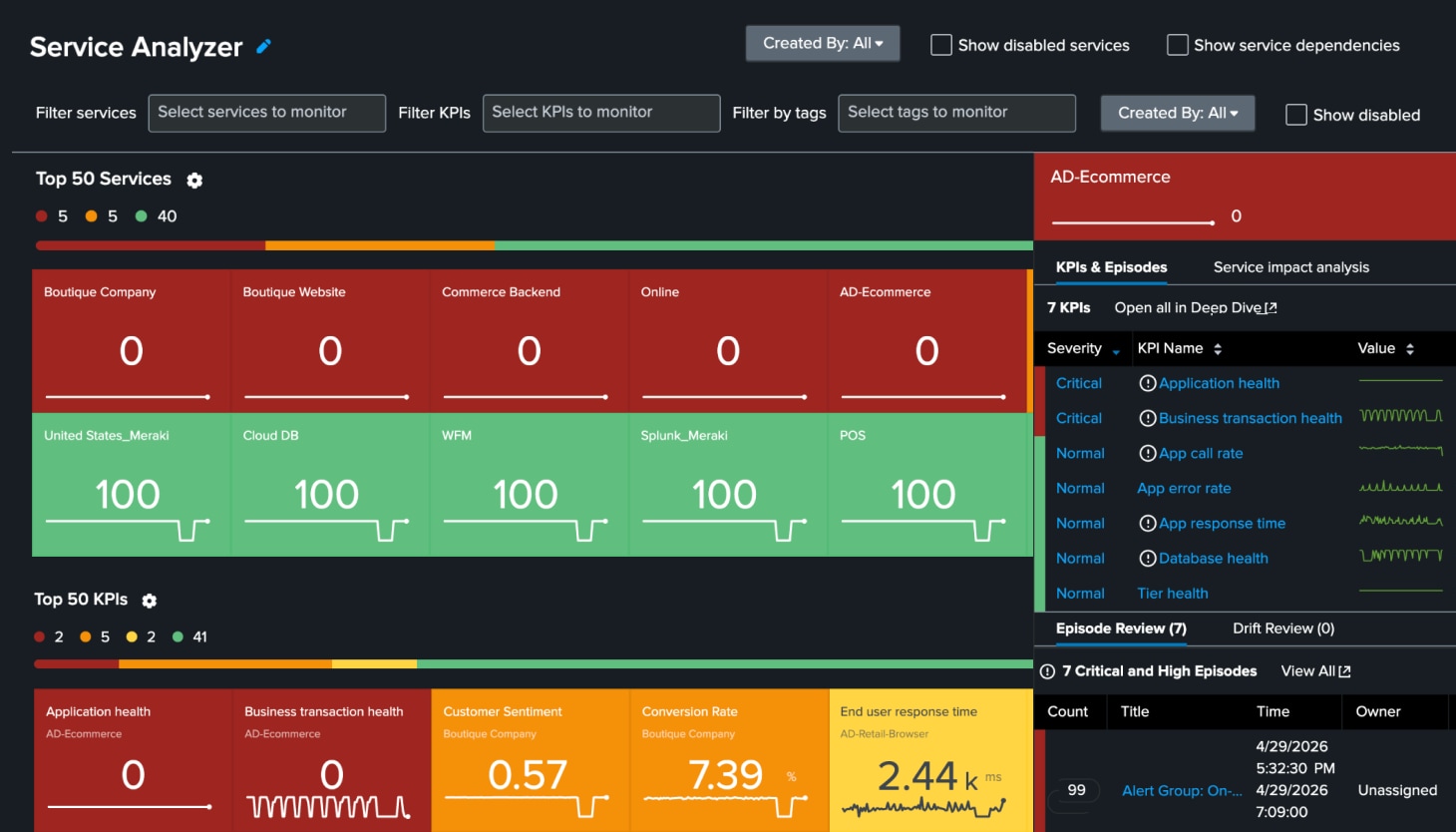
Prioritize response with service health and business impact insights
ITSI connects service health, KPIs, and dependencies to business priorities so teams can see what matters most. Health scores and real-time dashboards help operators prioritize work by customer, revenue, and operational impact — not just by alert volume.
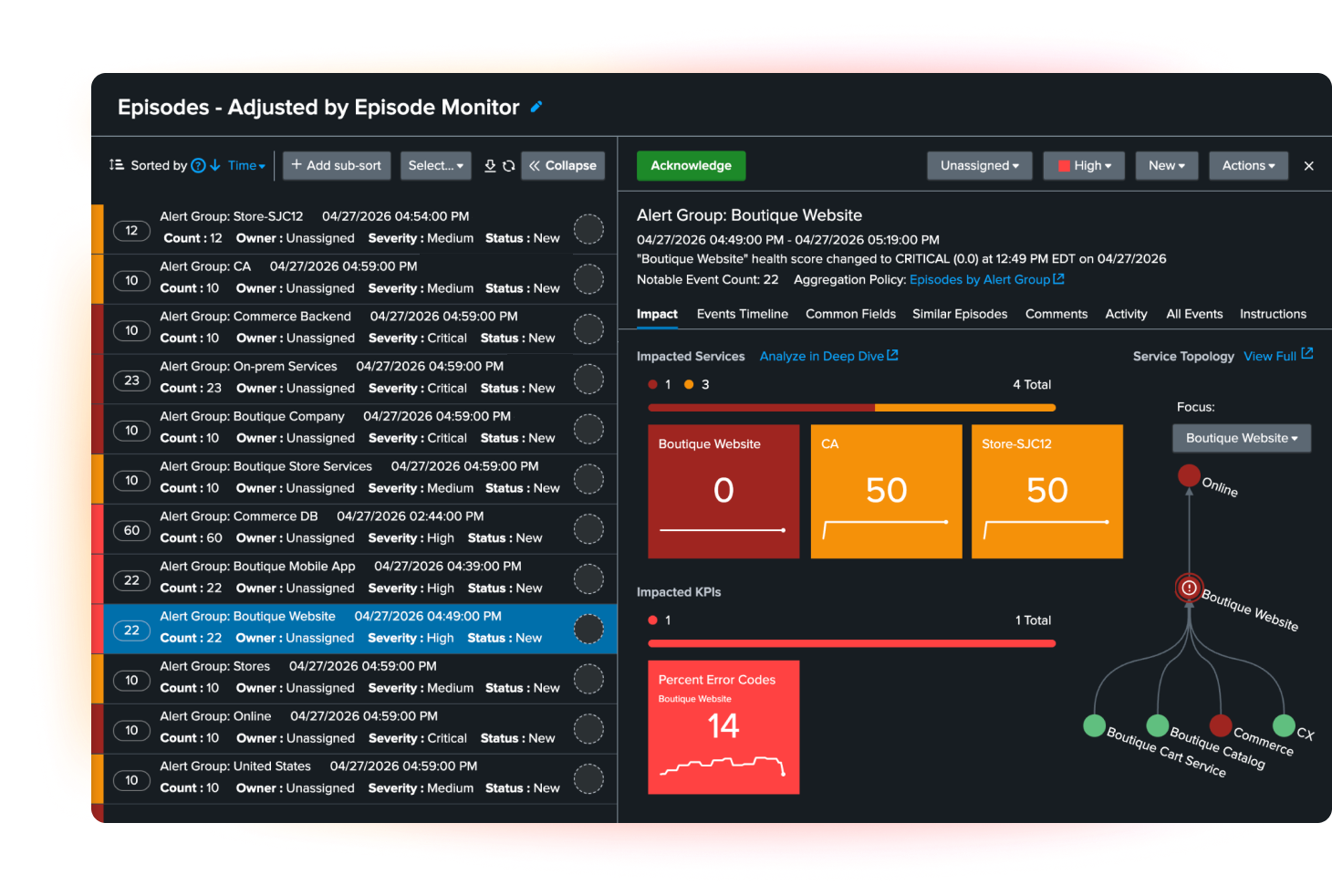
Run service operations in a modern, AI-connected workspace
A redesigned experience, Cisco AI Canvas integration, tag-based management, extended access controls, and flexible maintenance windows make daily operations easier to run. Teams can collaborate more efficiently, reduce false positives during planned work, and scale service ownership with more control.
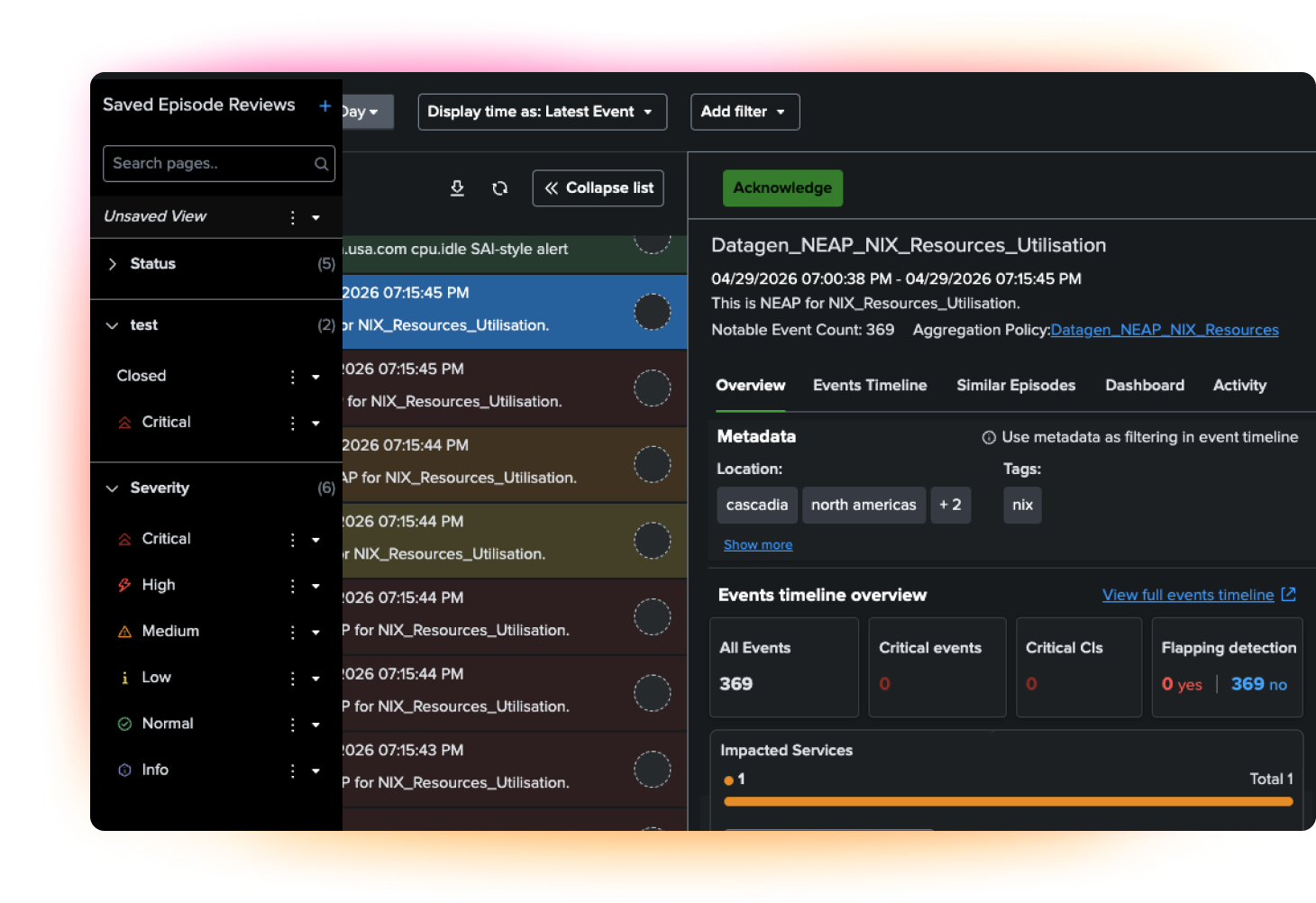
Unify operations. Reduce noise. Prioritize what matters.
Works with your existing tools
Bring together data from the tools you already use
ITSI works across Cisco and third-party monitoring tools, helping teams unify visibility and workflows without ripping and replacing existing investments. That means less disruption, faster adoption, and a clearer path to service and event intelligence.
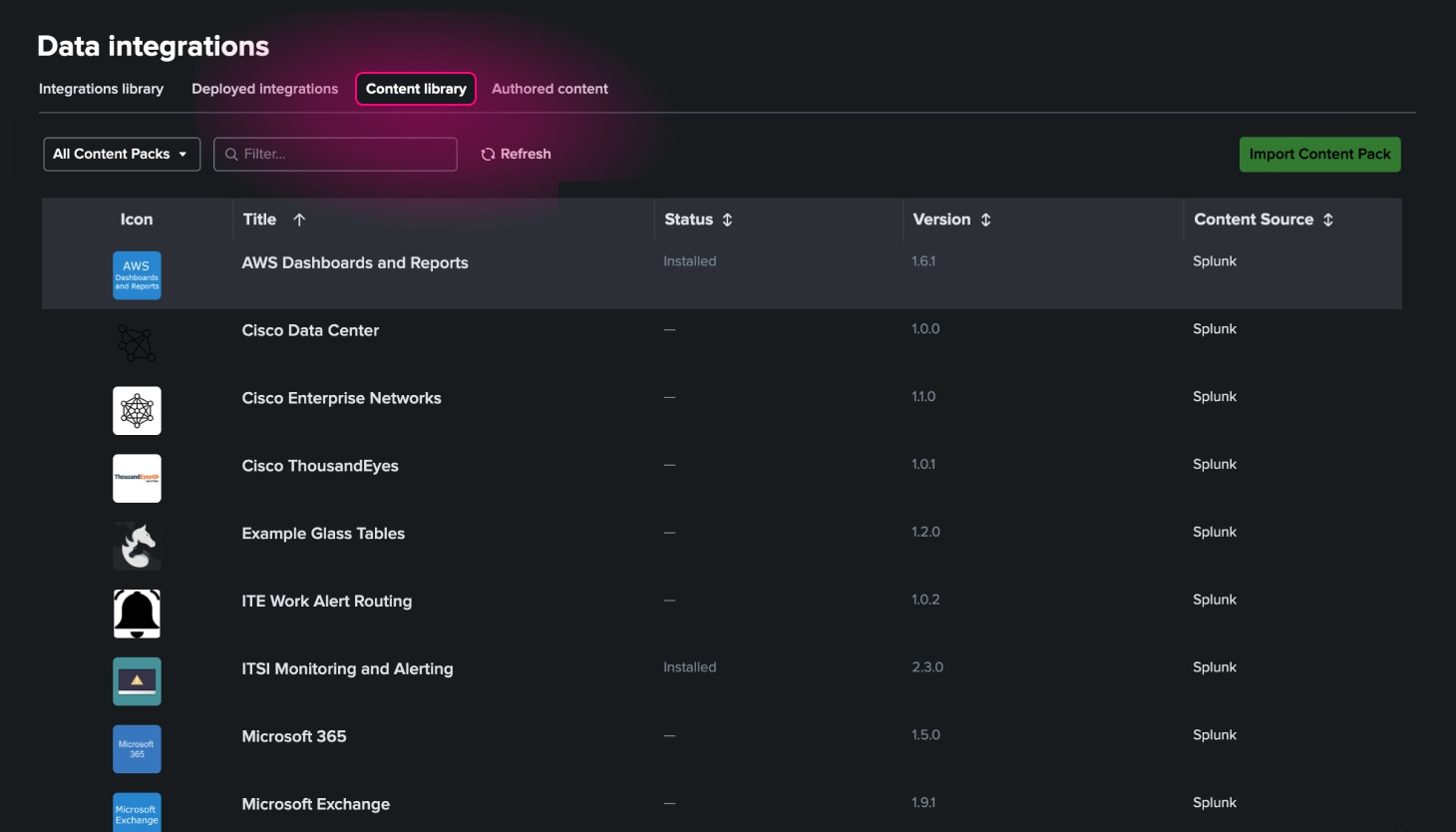
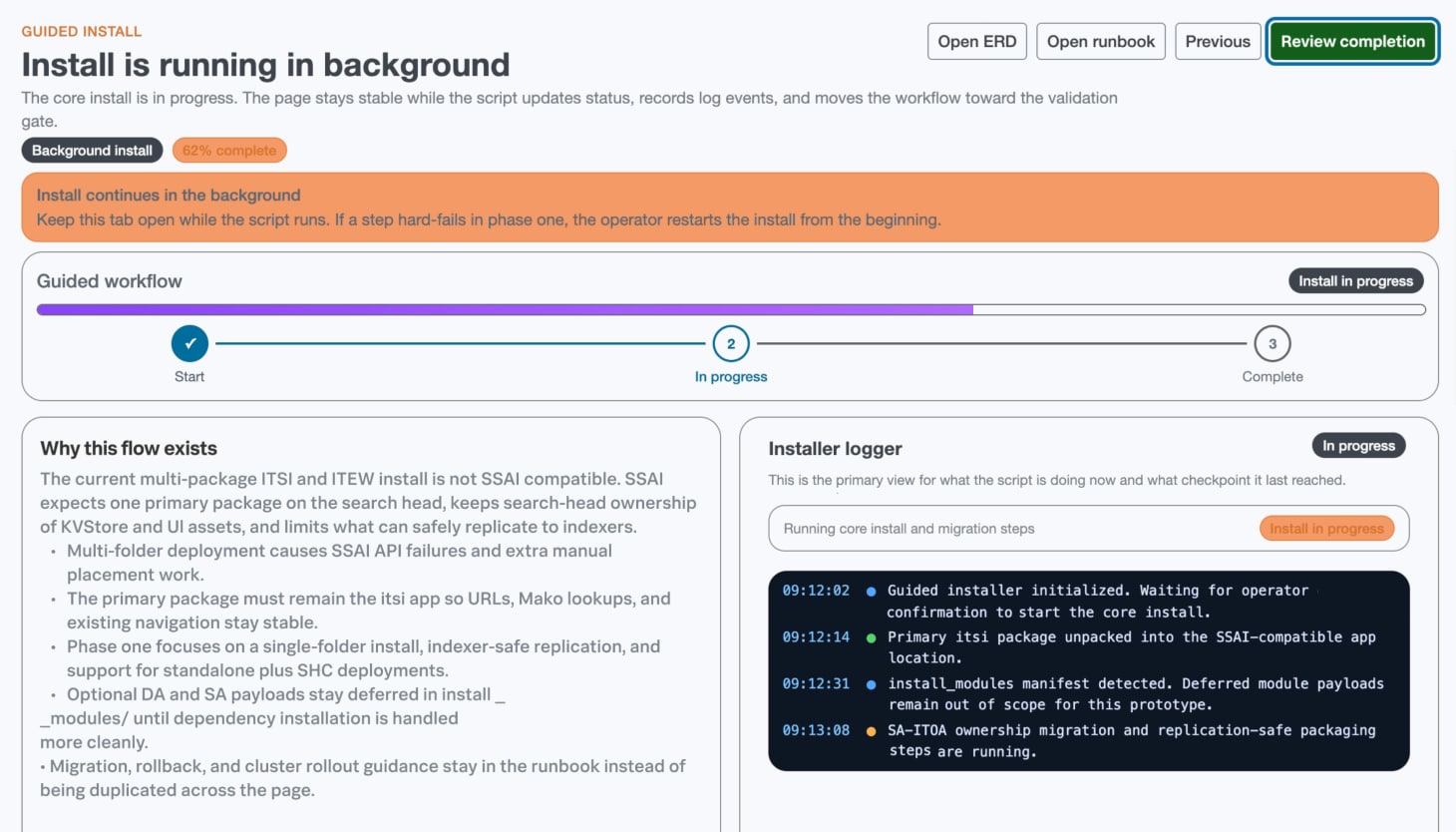
Simplified installation
Install in minutes, not days
Install and operationalize ITSI with relevant content packs in under 30 minutes through a self-service, intelligent installation experience that works seamlessly across Splunk Cloud and Enterprise environments.
Faster time to value
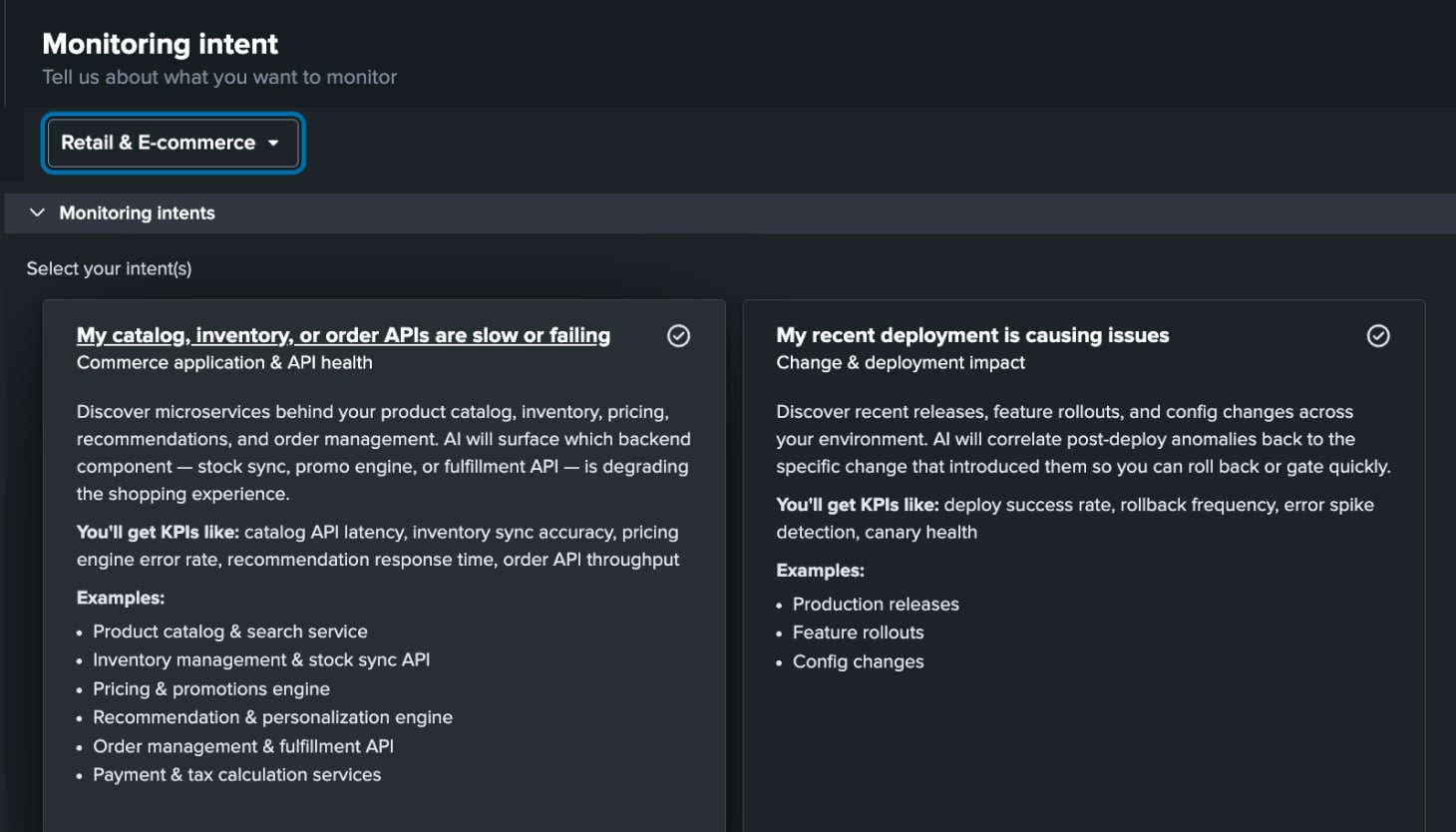
Start quickly with prebuilt content, integrations, and AI assistance
Out-of-the-box integrations, service templates, and AI-assisted setup help teams get up and running faster, reduce manual work, and realize value sooner across modern, hybrid environments.
Service ownership at scale
Clarify ownership with tagging, sharing, and team-based access
Use tags, shared service models, and team-based access controls to make ownership clearer across teams. Reduce handoff friction, improve collaboration, and keep service operations organized as environments grow.
Executive-ready reporting
Show service performance and business impact in real time
Give operations leaders and executives real-time dashboards that connect service health to business priorities. ITSI makes it easier to report on risk, uptime, and what teams are doing to protect critical services.

CUSTOMER STORY
TransUnion Invests in Splunk Solutions for Enterprise Monitoring, Machine Learning
With Splunk ITSI, we have a way to visualize application flow and health from service to service. ITSI helps us speed root cause determination and resolve issues as fast as possible.
CUSTOMER STORY
Molina Healthcare Gains Healthy Advantage
We went through a tools rationalization exercise and compared what the future state would look like versus where we were with our tools landscape, and the financial payout with Splunk® Enterprise and Splunk® ITSI was immediately apparent.


CUSTOMER STORY
Splunk Ensures Performance of Key Trading Application at ENGIE Global Markets
When there’s an issue, Splunk ITSI shows us where to look so we can solve the issue.

CUSTOMER STORY
Specsavers Sees 10x Faster MTTR with Splunk
Splunk has made every team's life easier.

Splunk IT Service Intelligence FAQs
Splunk IT Service Intelligence is an AIOps and service intelligence solution for IT operations teams. It brings together data from applications, infrastructure, networks, and existing monitoring tools to help teams monitor service health, reduce alert noise, find likely root cause faster, and understand business impact in real time.
Organizations add Splunk ITSI to turn operational data into faster action. It helps teams move beyond raw alerts and dashboards to unified service views, correlated incidents, and business-aware prioritization. For teams already using Splunk, ITSI helps extend the value of the data and workflows they already rely on.
Traditional tools often stop at domain-level monitoring and alerts. Splunk ITSI correlates signals across applications, infrastructure, networks, and services, then adds service context and business impact. That helps teams reduce silos, speed root cause analysis, and focus on the issues that matter most.
Yes. Splunk ITSI is designed to work across Cisco environments, third-party monitoring tools, and hybrid IT. It brings signals from across your environment into one operational view, helping teams reduce tool sprawl, improve cross-domain visibility, and respond more consistently across teams and domains.
Splunk ITSI uses AI-driven event analytics to onboard, normalize, and correlate alerts from multiple sources. Related alerts are grouped into actionable incidents, helping teams cut alert fatigue, reduce manual triage, and move faster from detection to resolution with stronger context and less guesswork.
Splunk ITSI connects service health, key performance indicators, and dependencies to the business services they support. That helps teams quickly see which issues are most likely to affect customers, revenue, and critical operations, so they can prioritize response based on impact — not just alert volume or technical severity.
Splunk ITSI is built for IT operations teams, network operations teams, site reliability teams, service owners, and IT leaders. Practitioners use it to reduce noise and speed troubleshooting, while leaders use it to gain real-time visibility into service health, operational risk, and business impact across complex environments.
Splunk ITSI helps teams get value faster with a self-service deployment wizard, prebuilt integrations, AI-assisted workflows, and streamlined setup. Organizations can build on existing data and operational processes, reducing manual work and accelerating onboarding so teams can improve visibility, triage, and reporting sooner.
Splunk ITSI includes modern capabilities designed to help teams move faster from signal to action. These include zero-touch alert onboarding and normalization, AI-driven event correlation, AI-assisted incident summaries and root cause guidance, Cisco network observability integrations, and a modernized user experience built for faster, more efficient operations.
Splunk ITSI simplifies service operations with tagging, flexible maintenance windows, team-based access controls, and modern visualizations. These capabilities help clarify ownership, improve collaboration, reduce false positives during planned work, and make service health monitoring easier to manage at scale.
Splunk Cloud
Search, analyze, visualize, and act on your data with a flexible and cost-effective data platform service.
Infrastructure Monitoring
Get real-time infrastructure monitoring and troubleshooting for all environments.
Splunk Observability Cloud
Unified visibility and real-time troubleshooting across any environment.