
Observability Buyer's Guide
Increase reliability, avoid downtime, and simplify IT operations. Learn how in this guide.

Key takeaways
The focus of synthetic monitoring is on website performance. Synthetic monitoring emulates the transaction path, between a client and application server, and monitors what happens.
The goal of synthetic monitoring is to understand how a real user might experience an app or website.
In this article, we’ll go deep into this topic. You should learn a thing or two about how to get more value from your synthetic monitoring tools and strategy.
Synthetic monitoring is one type of IT monitoring, and its focus is on website performance. (Other types, for example, include application performance monitoring and real user monitoring. These different classes exist because each has its own strengths and weaknesses.)
Synthetic monitoring can be used to answer questions like:
The best synthetic monitoring tools enable you to test at every development stage, monitor 24/7 in a controlled environment, A/B test performance effects, benchmark against competitors and, baseline and analyze performance trends across geographies.
(Explore Splunk Synthetic Monitoring, a leading tool for enterprise environments.)
Synthetic monitoring vendors provide a remote (often global) infrastructure. This infrastructure visits a website periodically and records the performance data for each run.
(Importantly, the traffic measured is not of your actual users — it is synthetically generated to collect data on page performance.)
A simple synthetic monitoring simulation design includes three components:
In synthetic monitoring, you can program a script to generate client-server transaction paths for a variety of scenarios, object types and environment variables. The synthetic monitoring tool then collects and analyzes application performance data along the customer’s journey of interacting with your application or web server:
(Related reading: synthetic data.)
Synthetic monitoring checks are performed at regular intervals. The frequency of these checks—how often they happen — is typically determined by what is being checked. Availability, for example, might be checked once every minute.
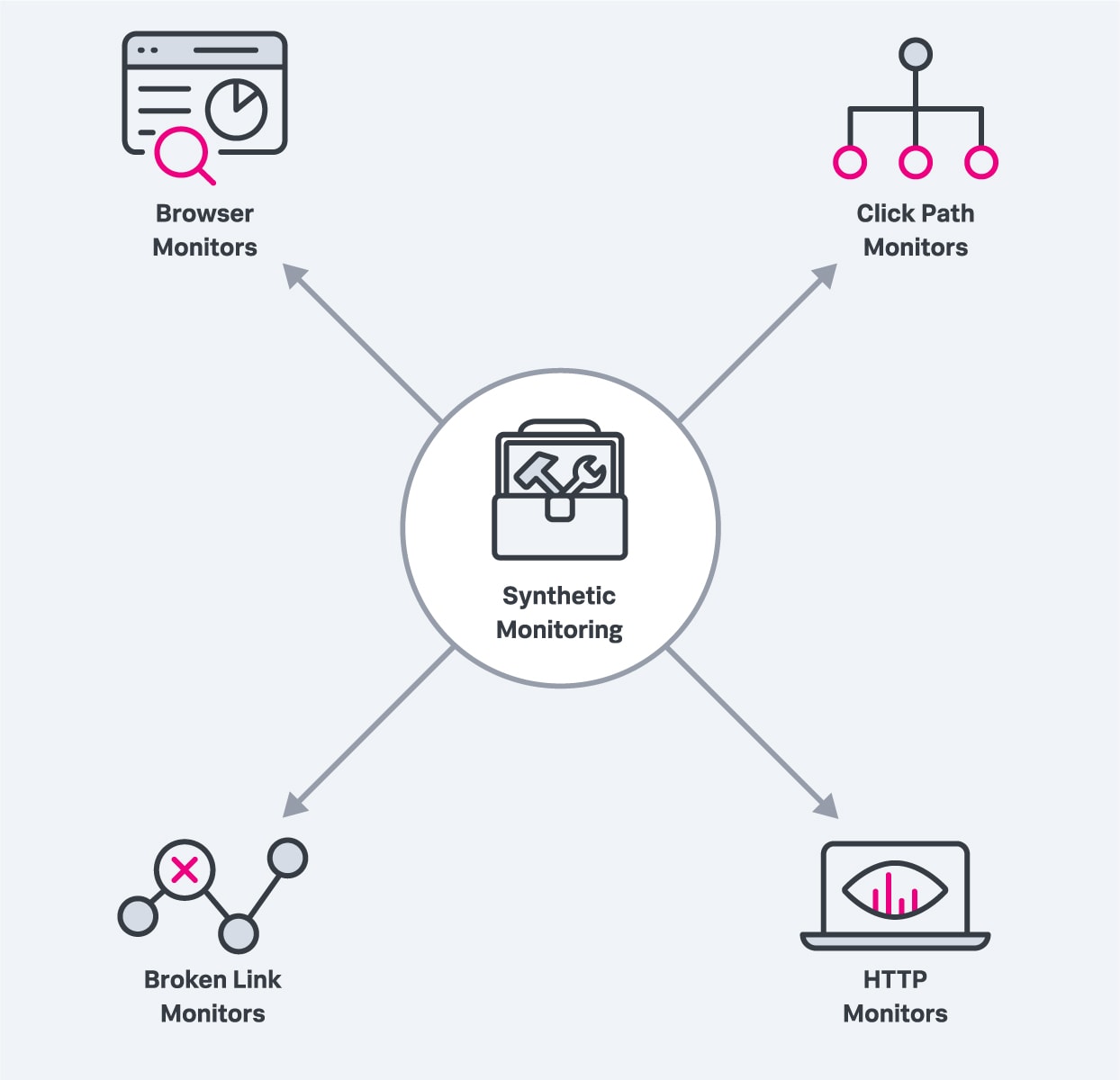
You can set up all sorts of monitors, including:
Browser monitors. A real browser monitor simulates a user’s experience of visiting your website using a modern web browser. A browser monitor can be run at frequent intervals from multiple locations and alert you when, for example:
Click path monitors. Click path monitors also simulate a user’s visit to your site but these monitor specific workflows. They allow you to create a custom script that navigates your website, monitoring a specific sequence of clicks and user actions, and which can be run at regular intervals.
Broken links monitors. These monitors allow you to create scripts that will test all the links for a specific URL. All failures are reported so you can investigate the individual unsuccessful links.
HTTP monitors. HTTP monitors send HTTP requests to determine the availability of specific API endpoints or resources. They should allow you to set performance thresholds and be alerted when performance dips below the baseline.
(Go deep into the differences in synthetic vs. real user monitoring.)
Let’s consider various delay scenarios for the client-server communications.
The synthetic monitoring agent emulates the behavior of a real-user and allows the synthetic monitoring tool to collect data on predefined metrics (such as availability and response time). This agent follows a programmable test routine. The configurations of this routine may include:
The scenario generation component injects a variety of testing scenarios that reflect the performance degradation or network outages. It may also specify how various agents are distributed to simulate a global user base accessing a web service through different data centers, as well as developments and changes in these circumstances.
The output of synthetic monitoring reports may be visual or time series data observations. You can then further analyze these outputs using a variety of statistical analysis and machine learning methods.
Here, analysts typically look for:
Active agent probing can be used for a variety of monitoring types, including API monitoring, component monitoring, performance monitoring and load testing, among others.
The key idea is to emulate a real-world usage scenario on-demand. These interactions may be infrequent and available sporadically.
With that understanding, we can now turn to helping you choose the best tool for your needs. We’ve put together the lists of features any strong, enterprise-grade synthetic monitoring tool should have. Let’s take a look.
A key benefit of synthetic monitoring is that you can define the specific actions of a test, allowing you to walk through key flows of your application — a checkout flow or a sign-up flow — to verify its functionality and performance. This is called scripting. A tool’s scripting capabilities directly determine how valuable it can be.
Here are some of the scripting capabilities that are essential to look for:
Of course, since enterprise websites change daily, and scripts can stop working, it is also important to evaluate a tool based on its troubleshooting capabilities, such as:
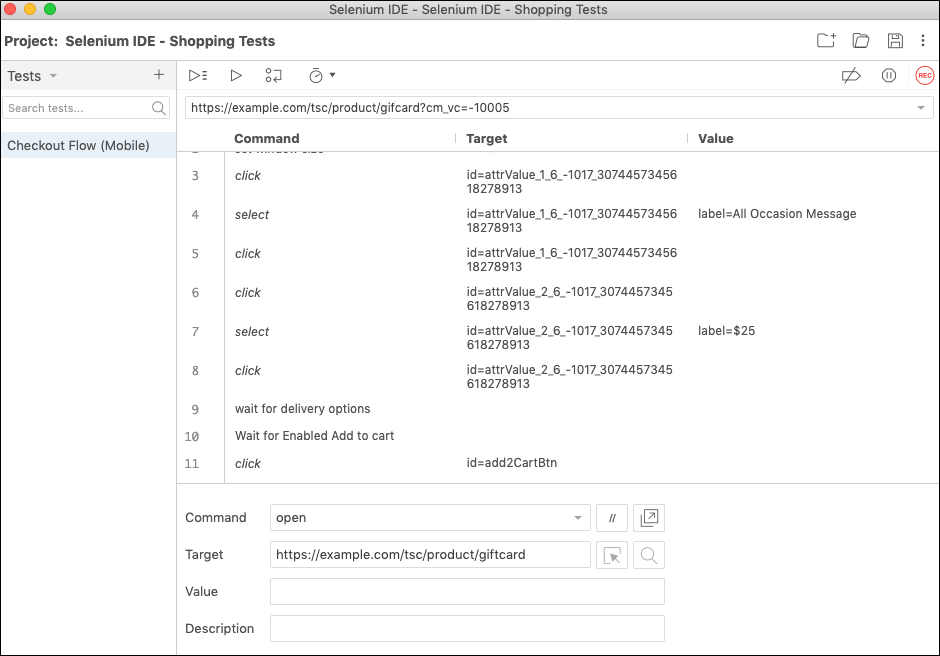
As an example, here is what the industry-standard Selenium IDE recorder looks like when testing a mission-critical “checkout user flow”.
A big advantage of synthetic tools is they allow you to experiment with what-if scenarios and see the impact on performance. It is essential to ensure you have flexibility and options that make it easy to get a clear line of sight of the impact of your performance initiatives.
Some common examples include:
How completely a specific synthetic tool can do these things depends on how much you can control about a test. Here are some of the configuration options to look for to be able to assess the results of common web performance experiments:
Of course, configuring a test with different options is only half the battle. In all these scenarios, you will collect performance data about your sites and applications under different conditions, and then you will need to compare them.
How your synthetic solution allows you to compare data and visualize differences is critical — that determines how easily and quickly you get results. Here are a few ‘must-haves’ to look for:
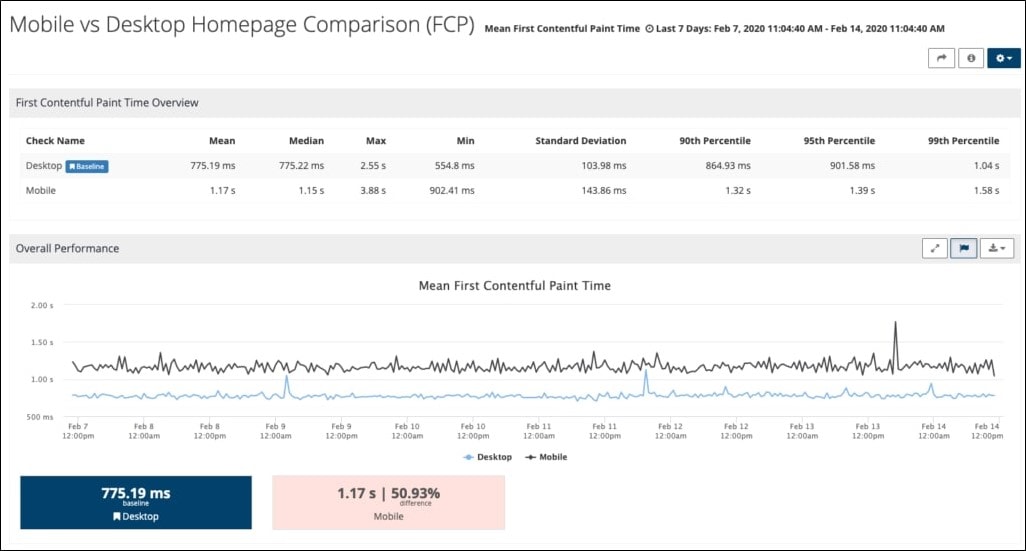
For example, here is what a comparison report looks like in Splunk Synthetic Monitoring:
Synthetic monitoring is one of the best ways to detect outages or availability issues since it actively tests your site from the outside. Critical to this is what capabilities does the tool have to define an outage and send the notification.
Here are a few things to look for:
Trouble accessing the site once doesn’t necessarily mean there is an outage. False positives can lead to alert fatigue so here are some of the more advanced capabilities to look for as well:
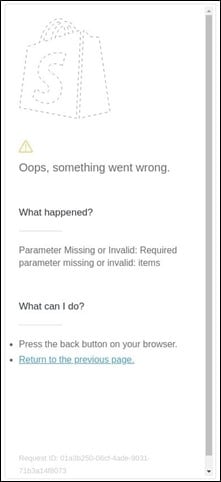
For example, here is a real screenshot (displayed within Splunk Synthetic Monitoring) showing off a page which returned an error:
Once your synthetic monitoring solution has detected an outage, it is critical that it notifies you and your team. How you want a tool to notify you depends on the workflow of your team — email and SMS are minimums.
Beyond that, you should focus on notification options that can easily integrate as tightly as possible into your team’s workflow and style. This will optimize how quickly your team can see and react to an outage.
Here are a few options to look for:
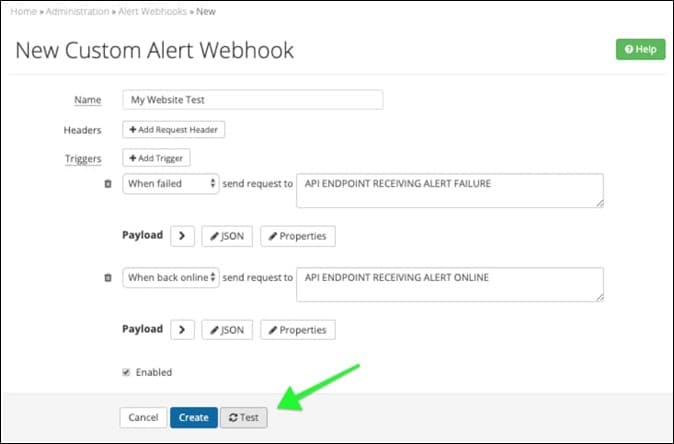
Here is what a typical custom webhook looks like. Make sure the synthetic tool you choose has similar functionality:
One of the key strengths of synthetic monitoring solutions is that they can help you assess the performance and user experience (UX) of a site — without requiring large volumes of real users driving traffic.
This means synthetic monitoring tools can be used in pre-production and lower environments (staging, UAT, QA, etc.) allowing you to understand the performance of your site while it’s still in development. This is tremendously powerful, allowing you to use performance as a gate and stopping performance regressions over time.
To do this, your solution must be able to reach your lower environments and gather performance data. It also must deal with some configuration nuances that are unique to testing environments. Capabilities for accessing pre-production that you should look for:
Is the testing location outside of your environment? Will you need to whitelist IP addresses? How much work is involved with your security team?
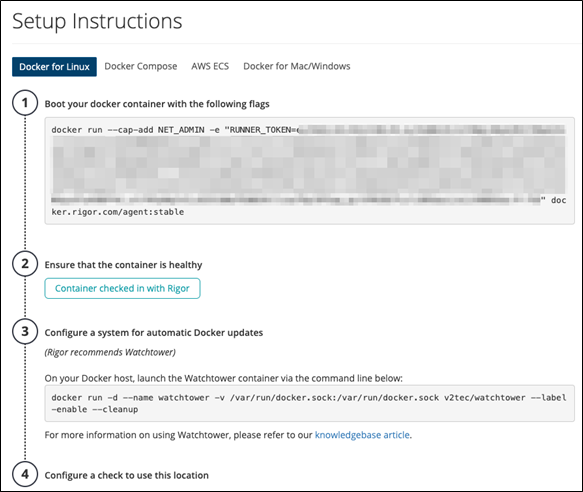
As an example, Splunk Synthetic Monitoring provides copy and paste instructions to launch a Docker instance to test pre-production sites:
A major use case of synthetic tools is to measure the performance of an industry to gain clear visibility into how your performance stacks up against others.
This application is unique to synthetic monitoring! That’s because other tools, like RUM or APM, will require you to place a JavaScript tag on the site or a software agent on the backend infrastructure, something that you obviously cannot do to the websites of other companies.
With a synthetic product, benchmarking a competitor’s site is as easy as testing your own site…you simply provide a URL — and you’re done!
However, there are various web security products that sit in front of websites and can block traffic from synthetic testing tools as a byproduct of trying to block attackers, bots, and other things that can cause fraud. You may often find that the IP addresses of the cloud providers and data centers used by synthetic providers are blocked. So, one thing to consider in your synthetic monitoring solution is:
Can you run tests from locations that your competitors are not blocking?
Another reason security products used by your competitors can block synthetic tests are because of the User Agent. If the User Agent is different than what an actual browser uses, that can cause you to be blocked. Another capability to check for is:
Can you customize the User Agent to remove anything that identifies it as a synthetic testing tool?
Once you can collect performance and user experience data from a competitor, you have everything you need to compare those results to your own site, so it is important to further understand:
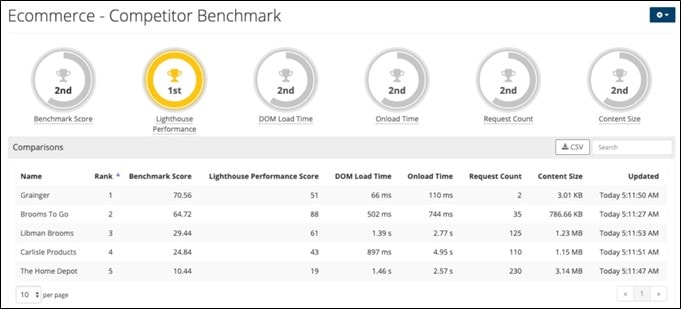
Here, Splunk Synthetic Monitoring illustrates a Competitor Benchmark dashboard:
In order to extract the most value of your synthetic solution, keep these questions in mind:
A major challenge facing synthetic monitoring is the validity of assumptions that go into producing a usage scenario. That is — we cannot assume we know what a user might do. In a real-world setting, users may behave unexpectedly. The scenario generating component, described above, may not be able to emulate an exhaustive set of complex real-world scenarios.
Still, you can mitigate these limitations. By combining synthetic monitoring with real-user monitoring, you’ll get the ideal view: you’ll get to look at the data produced by synthetic monitoring alongside information from real user monitoring — to make a well-informed and realistic statistical analysis.
Splunk Synthetic Monitoring monitors performance/UX on the client-side and tells you how to improve and make optimizations. You can even integrate this practice into your CI/CD workflows—automate manual performance tasks and operationalize performance across the business.

See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.



From testing new features to identifying easy performance wins, Splunk helps us integrate performance testing into our development life cycle.
The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.