
Downtime costs you
Learn about the costs of downtime — and how to avoid it. Get the free report.

Key takeaways
Before learning about mean time to repair, we should know that the availability and reliability of any IT service ultimately govern end-user experience and service performance, both of which have significant business impact.
These two concepts — availability and reliability — are particularly relevant in the era of cloud computing, where software drives business operations, but that software is often managed and delivered as a service by third-party vendors. At the end of the day, availability and reliability are major candidates for the most important metrics in providing IT services.
But how do you measure availability and reliability?
One of the key metrics used for measuring these service dependability characteristics is MTTR (Mean time to repair). Here’s everything you need to know about the MTTR metric including how you can calculate it, how to achieve a low MTTR and the challenges you might face along the way.
One of several "failure metrics", Mean Time To Recover (MTTR) refers to the average amount of time it takes to repair or recover from an issue or failure in a system, equipment, or process. Notes on the term "MTTR" itself:
MTTR also includes the lead time for parts that are not readily available. This can significantly impact the overall repair time. It is one of the most visible and useful metrics to determine:
In application, the lower the MTTR value, the faster the organization can respond to and recover from incidents impacting service or production availability. MTTR varies based on both internal capabilities and external factors that influence the time taken to restore operations from a failed state to the acceptable operational state before the failure occurred.
(Related reading: reliability metrics & incident response metrics.)
When discussing MTTR, it's often assumed to be a singular metric with a uniform interpretation. However, in reality, it encompasses potentially four distinct measurements. The "R" can signify repair, recovery, respond, or resolve,
While these metrics share some common ground, each carries its own significance and subtleties.
MTTR is one of those useful metrics that can be used in a variety of settings.
It’s most normally associated with the management of a service, assuring a service is being delivered to its end-users as promised contractually. It’s also useful in software development, like in the DevOps practice of continuous development: as your software development matures, your MTTR will likely shrink.
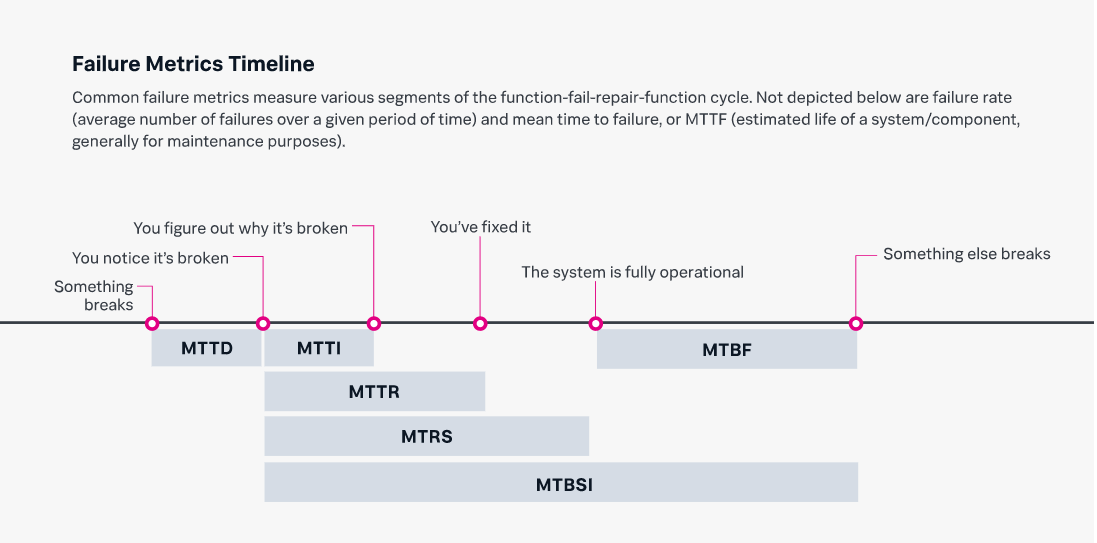
When calculating MTTR, the clock starts ticking as soon as a failure is detected. MTTR includes the time it takes to diagnose the problem, repair it, test it and any other procedures that must take place before the service is up and running and there is a return to normal operations.
Therefore, a low MTTR is preferable to a high MTTR.
Most service-level agreements (SLAs) between a customer and a service provider or vendor include MTTR in some manner as a guarantee of performance, and a high MTTR can lead to high penalties.
It’s important to remember that MTTR represents a typical repair time, not a guaranteed one. A vendor claiming an MTTR of 24 hours is saying that’s how long it usually takes to complete a repair, but individual incidents could take more or less time to resolve.
The purpose of MTTR is to track the time that business-critical systems are unavailable for use, which makes it a valuable metric when analyzing the overall severity and impact of an IT incident. Mathematically, the Mean Time to Recover metric is defined as follows:
MTTR = Time elapsed as downtime / number of incidents
or
MTTR = Time elapsed as maintenance / number of repairs
For any impacted component, the MTTR includes the time that passes from the moment of the incident to the moment you’ve recovered to the a state of operation and availability.
In this context, availability refers to the proportion of time during which a service remains operational under normal conditions. It is calculated as:
Availability = (Total Elapsed Time - Total Downtime) / Total Elapsed Time
This means that functionally, we can consider availability to be the inverse function of MTTR — in other words, as the MTTR increases due to lack of system reliability, the service spends less time in a fully operational and functional state.
In our equation, reliability refers to the probability that the service maintains expected performance standards during its operational state.
Reliability can be used as an attribute of availability, describing how well the service performs during transient states of availability and outages as measured against predefined performance metrics. As a general rule, the reliability of a service decays over its lifecycle and the MTTR metric value increases.
MTTR can fluctuate substantially from component to component, as there are multiple factors influencing availability and reliability. The failure rate may be a constant term defined for an individual hardware or software component, but recovery to the original state of availability may depend on a variety of factors, including internal system dependencies and external factors such as availability of replacement products, tools and services.
When assessing this metric, keep in mind that not all MTTR is the same: the opportunity cost of downtime for ecommerce companies during a peak holiday season is significantly higher than an outage during off-peak seasons. In this context, various modular redundancies can reduce the MTTR to a minimum, creating imperceptible failure incidents.
(See how site reliability engineers improve system reliability.)
MTTR has a strong correlation with business performance. Here are just a few ways MTTR influences business operations and outcomes.
User experience. Unplanned outages have a significant impact on end-user experience. MTTR is particularly relevant for cloud-driven enterprises, as the opportunity cost of downtime is entirely dependent on how frequently outages occur and how long it takes to recover from an IT outage incident.
This means that user experience has an inverse correlation with MTTR: the more time it takes for your service to recover from an outage, the more negative the impact it will have on your end-user experience.
Downtime costs. Downtime is expensive. The longer it takes to repair or recover from an issue, the more downtime a business experiences. Downtime can lead to:
Faster MTTR reduces the duration of downtime and minimizes its negative financial impact.
Operational efficiency. Directly relating to downtime costs, a strong MTTR indicates that a business has efficient repair and recovery processes in place. This efficiency not only reduces downtime but also allows you to use resources more effectively, leading to improving the overall operational efficiency.
Employee productivity. In IT-intensive businesses, MTTR is just as critical for internal systems and services. Disrupted service in key tools can stop employees from being able to perform tasks efficiently, or sometimes entirely — resulting inloss of productivity, employee frustration and loss of revenue.
SLA adherence. It’s not uncommon for businesses to have service level agreements (SLAs) with customers that specify minimum MTTR targets. By failing to maintain the agreed-upon MTTR, businesses may face penalties or be challenged for breach of contract.
Fighting for a great MTTR metric is never a “one-and-done” endeavor. Like most things in IT, it's a practice that requires continuous iteration and attention.
Here are a few ways organizations tackle the ongoing process of maintaining strong MTTR.
If you want to fix an issue, you have to know:
An advanced IT monitoring solution will give you real-time, uninterrupted data to help you fully understand your system’s performance — and provide all the data related to any fault or failure. Also, MTTR is reduced by latent fault detection by detecting hidden issues before they evolve into failures. This enables quicker repairs and reduced downtime.
Because MTTR measures the capability of an organization to respond to an issue, alerting needs to be highly accurate and effective, as teams will need to be made aware of major issues as quickly as possible to minimize the business impact of an incident.
(Measure monitoring and alerting success with the the MTTA metric.)
The first step to improving MTTR is to understand the incidents that cause it. Thorough root cause analysis of major incidents is key in minimizing MTTR. Understanding the cause of a system failure is crucial. This knowledge allows you to implement appropriate safeguards. Additionally, you can make necessary replacements or fixes. These actions help prevent the same issue from recurring. Ultimately, this leads to improved system reliability.
Organizations with a carefully planned incident response protocol (IRP) are much more likely to respond quickly and effectively to issues and therefore have a lower MTTR. For many organizations, this likely includes an IT service management (ITSM) approach. Companies that have successfully undergone full digital transformation may take a more flexible approach, employing cross-functional collaboration tools and constructing specific responses — even explicit checklists — for each incident.
A great solution for many organizations, an automated incident management system can handle the process of sending alerts in multiple channels (phone calls, SMS texts, email, etc.) to all incident responders, reducing the time frame to notify people. The key to any plan, regardless, is to have a clear understanding of who to notify of an incident, how it should be documented and what steps should be taken to rectify it.
Nowadays we have modern technologies like machine learning, augmented reality, artificial intelligence, wearable devices and other techs. These all can help to:
This will lead to improving the efficiency of a technician, reduce errors and streamline communication. All of these working together can lower MTTR and increase a system's uptime, thus ensuring customer satisfaction. For example, Boeing is using AR for inspection and reduce maintenance time.
Past incidents aren’t just dips on your availability graph — they’re opportunities to learn and prepare for the future. Logging and documenting incidents clearly is essential. This practice helps organizations create a quick reference guide. Such a guide is useful for similar future issues. Ultimately, this leads to better MTTR. Improved documentation enhances incident resolution efficiency.
(Learn how to hold an incident review or postmortem.)
You can introduce resilience into cloud-based systems. This helps meet agreed SLA terms for service reliability. Additionally, it ensures availability.
Redundancy is also introduced in this context. It aims to remove the potential impact of MTTR. Specifically, this applies to a single network node. Singular node components can be unreliable, but modular redundancy may be inexpensive at the individual component level.
When debating implementing modular redundancy, you should consider both MTTR and MTTF (Mean Time to Failure). At the end of the day, we can define a highly dependable system as one that is optimized to reduce the sum of MTTF and MTTR to a minimum.
(Related reading: redundancy vs. resiliency, what's the difference?)
Reducing MTTR is not only a constant process, but it can be increasingly difficult. As new threats emerge and systems become more complex, cybersecurity is in constant flux and IT teams can have increasing potential failure points in a system.
Unfortunately, that’s just the tip of the iceberg. Here are some of the key challenges to keep in mind when assessing MTTR.
One of the challenges surrounding cloud environments is the lack of visibility and control of the infrastructure operations. Without sufficient real-time monitoring data, it may not be possible to determine the true underlying root cause of IT outages — MTTR then becomes a function of complexity and dependencies within your IT environment.
To address these concerns, AI-enabled hyper-automation technologies can help. They extract relevant monitoring information at the process level. Additionally, they evaluate system performance effectively. These technologies also account for dependencies across the environment. This includes the end-to-end multi-cloud environment.
You purchased a third-party tool for a reason. Failures involving third-party tools can greatly impact MTTR. This impact may stem from increased functionality or scalability issues. Additionally, a lack of internal personnel or resources plays a role. Often, you must rely on external support teams. This reliance can complicate incident resolution. Furthermore, you have significantly less visibility over the system. Consequently, your MTTR will inevitably take a hit. This occurs when a third-party component stops functioning.
(Learn about third-party risk management.)
Approaching detection and triage manually can inflate MTTR significantly. It’s important to incorporate automatic detection and response tools into a system to ensure incident resolution can happen as quickly as possible.
Every second spent resolving system failure impacts your customers during the outage. Depending on the service or tool being provided, this can cause a lot of distress for those customers. Lapses in communication during an outage can result in frustration or dissatisfaction. Communication on outages and resolution time frames becomes increasingly difficult when root cause analysis takes longer than expected.
Not all MTTR is the same. A failure in user communication can have significant consequences. Specifically, this is true during a high-impact outage. Moreover, such failures may create rippling effects across the business. Now, let's discuss some other metrics to assess system reliability.
Understanding MTTF, MTBF and MTTA are important to evaluate system performance and reliability. These metrics help you with valuable insights into your system's operational efficiency, thus helping you to make informed decisions. Let's discuss what they are used for -
The availability and reliability of IT services significantly influence end-user experience and overall business performance. When measured through MTTR, we can gather valuable insights. Specifically, this relates to the dependability of services. Additionally, it reflects the efficiency of incident resolution processes.
MTTR is a critical indicator for any organization. Moreover, this applies to both internal and external services. By overcoming related challenges, organizations can enhance operational efficiency. Consequently, improved efficiency can lead to increased revenue. Furthermore, a focus on MTTR fosters a satisfied customer base. In addition, it contributes to a happier user base.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.