
Downtime costs you
Learn about the costs of downtime — and how to avoid it. Get the free report.
Key takeaways
SRE (site reliability engineering) is a discipline used by software engineering and IT teams to proactively build and maintain more reliable services. SRE is a functional way to apply software development solutions to IT operations problems.
From IT monitoring to software delivery to incident response, site reliability engineers focus on building and monitoring anything in production that improves service resiliency without harming development speed.
Often used as a highly integrated method for tightening the relationship between developers and IT teams, the biggest roles for SREs is twofold:
Site reliability engineers write code to improve service resilience and flexibility. Then, they help spread information across DevOps and business teams, encouraging a blameless culture focused on workflow visibility and collaboration.
How do these teams know they're achieving their goals? In this article, we'll take a look at the core components of SRE, including metrics, the Four Golden Signals of Monitoring, and KPIs to help you track progress.
Splunk IT Service Intelligence (ITSI) is an AIOps, analytics and IT management solution that helps teams predict incidents before they impact customers.

Using AI and machine learning, ITSI correlates data collected from monitoring sources and delivers a single live view of relevant IT and business services, reducing alert noise and proactively preventing outages.
First, let's start with a little background on how and why SRE has become so important today, starting with ITSM...
IT service management (ITSM) has existed since the beginning of computers. System administrators (sysadmins) would handle everything from assembling software components to deploying them and responding to incidents. Then, with the introduction of personal computers, IT professionals needed to define universal principles for reliably handling applications and infrastructure.
The growing adoption of technology gave way to the IT service management practice, often harnessing ITIL, a set of defined rules for all IT operations. For a while, defined rules worked well. Software developers wrote the code and gave it to sysadmins who configured and deployed the services. However, this proverbial fence led to a natural division of labor between software developers and sysadmins.
Then, with the birth of the Internet and highly complex, integrated systems, Agile software development practices, and CI/CD became a necessity. In order to keep up with the faster delivery of always-on services, IT service management practices also needed to change.
DevOps was adopted in response to the shift in development and release practices. DevOps is a method for:
A DevOps methodology gets IT teams involved earlier in the software delivery lifecycle (SDLC) while also increasing developer accountability for services in production.
With the faster delivery of more complex applications and cloud infrastructure, teams needed a way to proactively address reliability concerns, leading to the creation of the modern practice of SRE. However, this also came with additional requirements for SRE — to learn Docker and Kubernetes to fit in today's cloud-native environments.
(Related reading: SRE, DevOps, platform engineering, what's the difference? )
The discipline of site reliability engineering originates at Google. They used SRE to make a shift towards an IT-centric organization, aligning everyone across the business — from engineering to sales. Google’s then VP of Engineering, Ben Treynor, defined SRE as:
Fundamentally, it’s what happens when you ask a software engineer to design an operations function. - Google Interview With Ben Treynor
Google started to treat issues that were normally solved manually as software problems — formalizing an SRE team to apply software development expertise to traditional IT operations problems.
With developers focused solely on making operations better, the team can build resilience into their services without harming development speed. They can automate numerous manual tasks and tests. Thus, increasing visibility into system health and improving collaboration across all of IT and engineering.
(Learn about the SRE role and how to hire SREs.)
40-90% of the total costs of a system are incurred after birth. - Google’s SRE Book
Most DevOps and IT professionals constantly focus on improving the development process, while paying less attention on their systems in production. Surprisingly, the vast majority of application and infrastructure costs are incurred after deployment. Thus, development teams need to spend more time supporting current services.
In order to reallocate their time without impeding velocity, SRE teams are forming: dedicating developers to the continuous improvement of the resilience of their production systems.
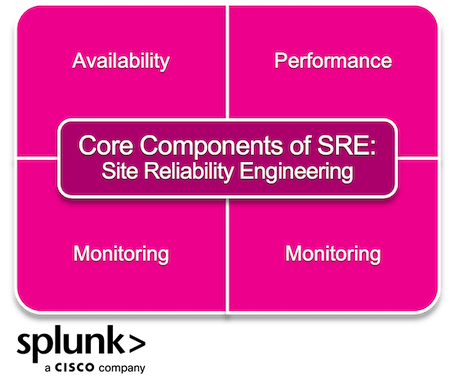
So, what do they focus on to build resilience? The core responsibilities of SRE teams normally fall into these categories:
Availability is the term for the amount of time a device, service, or other piece of IT infrastructure is usable.
For any underlying service (an app, an API, a whole network), availability is often associated with both downtime and a variety of service-level metrics, SLOs, SLAs, and SLIs).
SRE teams initially set SLOs, SLAs, and SLIs to answer business questions such as the following:
Over time, as SRE teams spend more time working in production environments, engineering organizations begin to see more resilient architecture with further failover options and faster rollback capabilities. These companies can then set higher expectations for customers and stakeholders, leading to impressive SLOs, SLAs, and SLIs that drive greater business value. Over time, that begins to look like this:
(Learn more about availability management.)
As teams mature in SRE and thus the availability becomes less erratic, they start focusing on improving service performance metrics like latency, page load speed, and ETL. Questions that can help pinpoint work here include:
Performance errors may not affect the overall availability. However, customers who frequently encounter performance issues may experience fatigue and consider stopping the use of the service: that may mean fewer sales, fewer repeat customers, and lost revenue.
SRE teams help application support and development teams fix bugs and proactively identify performance issues across the system. As overall service reliability improves, teams will open up more time to identify small performance issues and fix them.
(Related reading: website monitoring & application performance monitoring.)
In order to identify performance errors and maintain service availability, SRE teams need to see what’s going on in their systems. Naturally, the SRE team is assigned the great task of implementing monitoring solutions. Because of the way disparate services measure performance and uptime, deciding what to monitor and how to do so effectively is one of the hardest parts of being a site reliability engineer.
SREs need to think of monitoring as a way to surface a holistic view of a system’s health. Anyone from any department in engineering or IT should be able to look at a single source, like a unified data platform (such as Splunk) to determine the overall performance and availability of the services they support.
Indeed, it was precisely this need — for cross-service, cross-team visibility — that spurred the creation of SRE’s golden signals. (The goldens signals serve as a foundation for actionable DevOps monitoring and alerting, as we'll see in the next section below.)
Continuous improvement in several areas — monitoring, incident response, service availability and performance optimization — organically leads to more resilient systems. Ultimately, SRE teams build the foundation for a more prepared engineering and IT team. With the monitoring resources provided by the SRE team, the development and IT team can deploy new services quickly and respond to incidents in seconds.
Integrating site reliability engineers into engineering and IT allows developers to focus on the production environment and helps introduce IT operations earlier in the software development lifecycle. A reactive SRE team responds to issues and fixes them. However, a proactive SRE team puts the system's resilience directly in the hands of individual team members.
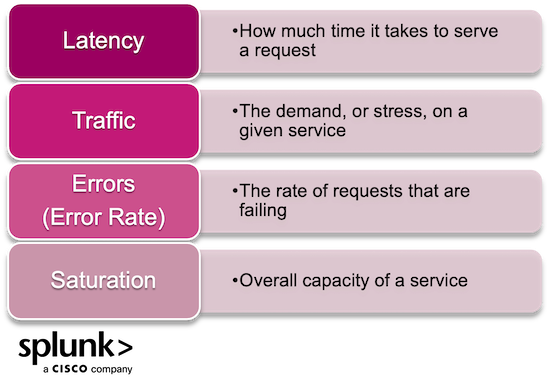
Effective implementation of the of SRE metrics requires visibility and transparency across all services and applications within a system. But, it is complex to measure the performance and availability of disparate services on a single scale. So, Google’s SRE team developed the four golden signals as a way to consistently track service health across all applications and infrastructure. SRE’s golden signals define what it means for the system to be “healthy.”
The four golden signals of SRE are:
While a team can always monitor more metrics or logs across the system, the four golden signals are the basic, essential building blocks for any effective monitoring and observability strategy. Think of these as your get-started, jumping-off point for actionable monitoring.
Tracking the latency, traffic, errors and saturation for all services in near real-time will help all teams identify issues faster and have a clear, immediate, single view into the health of all services. Instead of disparate monitoring across every feature or service, you can roll all monitoring metrics and logs into a single location, like Splunk. Effective monitoring will not only lead to improved incident management but it will improve the entire incident lifecycle over time.
Latency refers to the time taken to serve a request. Measuring latency for your systems has two core parts:
Tracking latency across the entire system helps identify which services are not performing well. It also allows teams to detect incidents faster. The short latency of errors helps improve the speed at which teams identify an incident, allowing faster incident response.
Traffic refers to the stress from demand on the system. The more traffic to your systems, the more "stress" those systems carry. Things to consider here include:
By monitoring real-user interactions and traffic in the application or service, SRE teams can see exactly how customers experience the product and how the system holds up to changes in demand.
Errors, or the error rate, defines the rate of requests that are failing. SRE teams need to monitor the rate of errors, both across the entire system and at the individual service level. This includes:
It’s also important to define which errors are critical and which ones are less dangerous. This can help teams identify a service's true health in the eyes of a customer and take rapid action to fix frequent errors.
You'll also hear about errors in the context of RED: rates, errors, and duration. Known as RED monitoring, these three metrics offer a streamlined approach for monitoring microservices and other request-driven applications.
Saturation is defined as the overall capacity of the service. The saturation is a high-level overview of the utilization of the system:
An important consideration here is benchmarking healthy rates. After all, most systems begin to degrade before utilization hits 100%, which is why SRE teams need to determine a benchmark for a “healthy” utilization percentage.
In this video, see how you can use Splunk Real User Monitoring to quick identify client-side errors and latency.
For SRE teams, they need to assess their impact on a business and identify areas of improvement. Some KPIs for measuring the value of SRE practices include:
Learn more about which metrics and KPIs can deliver value to your organization:
To wrap up, let's now turn to some real world situations for SREs.
SREs with access to adequate resources can take proactive measures to improve system reliability. On the other hand, SREs with insufficient time, tools, or expertise, or teams are understaffed, can only take reactive measures, dealing with incidents as they occur. The lack of adequate automation tools forces SREs to handle repetitive tasks manually, reducing inefficiency. They cannot meet KPIs and the likely indicator here that something is a problem? High MTTR and MTBF.
An internal developer portal is key for the effective implementation of the above SRE metrics. It simplifies access to internal developer tools in a self-service fashion and ensures site reliability policies and practices are embedded into a product from the outset. Besides, it provides a shared platform where SRE and DevOps teams can work together through collaboration.
"When a measure becomes a target, it ceases to be a good measure."
Yes, Goodhart's Law certainly applies to SRE metrics. So what does it mean here?
SRE's goal is to maintain system reliability. However, when SRE teams focus heavily on optimizing a specific metric, such as latency, it may become their primary measure of success, and they may neglect other metrics. This metric may lose effectiveness as the team adapts to meet its targets. The consequence is compromised performance measurement and, ultimately, ineffective decisions.
This is because the team narrows its focus on meeting a target as opposed to ensuring the holistic health or quality of a system. To balance the use of SRE metrics with the pursuit of overall system health, you need to measure a wide range of metrics that reflect different aspects of the system. Also, you should continuously review them to align with evolving system goals.
Site reliability engineers expose themselves to many aspects of the system, inherently improving the collaboration between developers and IT operations teams. Facilitating a DevOps mindset through SRE leads to breakthroughs in your team’s productivity and your system’s resilience. When an incident occurs, instead of passing blame between development and IT, SRE opens transparent discussions about how they can improve. SREs are the gatekeepers for efficient, reliable software development practices that don’t force all production responsibilities to IT teams.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.


The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.