
Downtime costs you
Learn about the costs of downtime — and how to avoid it. Get the free report.

IT services only deliver value when they deliver the designed functionality and agreed performance that customers need and rightfully expect. And availability is the heart of performance: when the service experiences an outage and isn’t available, business processes and user activities are essentially curtailed.
In this comprehensive article, we will look at best practices in availability management. We’ll cover everything you need to know:
Availability management is defined in ITIL® 4 as the practice that ensure that services deliver the agreed levels of availability to meet the needs of customers and users. In this context, availability is the ability of an IT service or other configuration item to perform its agreed function when required.
Availability management involves putting in place the plans, processes, people and technologies required to meet current and future availability requirements, as well as managing availability risks that could materialize in the form of outages.
Avoiding outages is the #1 priority for any IT operations team. This requires concerted efforts, starting with leadership, and then involving all teams supporting the service lifecycle including partners and vendors.
Splunk IT Service Intelligence (ITSI) is an AIOps, analytics and IT management solution that helps teams predict incidents before they impact customers.

Using AI and machine learning, ITSI correlates data collected from monitoring sources and delivers a single live view of relevant IT and business services, reducing alert noise and proactively preventing outages.
Yes, it is true that the number of IT and data center outages are decreasing. But their frequency remains relatively high, as The Uptime Institute’s 2023 Outage Analysis report highlights.
Shown below, the main causes of outages over the last three years were caused by issues with network connectivity, power, software/systems and third party related services or components.
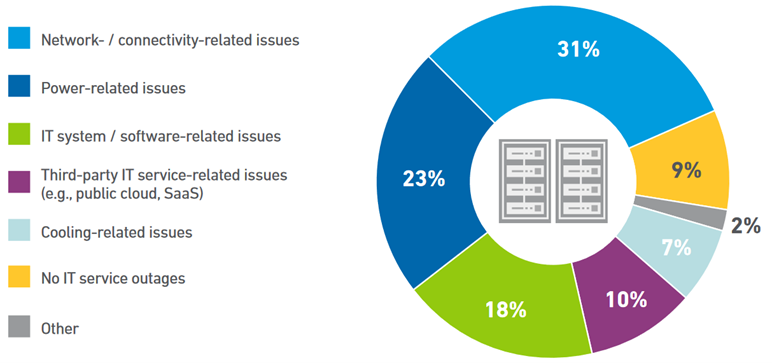
Chart highlighting common causes of outages experienced over the last 3 years (Image source)
When it comes to addressing these causes of downtime through availability management two key approaches come to mind:
This involves planning and designing for availability in IT services and their underlying components.
Here, your enterprise architecture ensures the availability requirements and controls, while the solution design team will design the same controls as part and parcel of the service model. Examples of such controls include:
In this approach, you’ll look at planning activities from a few perspectives. Planning will have a component of risk management that will identify and control risks against availability, while service continuity will conduct business impact analysis to prioritize the IT service for the implementation of resilience mechanisms. The availability controls will be implemented during software development and the configuration of infrastructure and platforms.
Change management will play a role of reviewing deployment plans to ensure that tests for availability have been successfully conducted, and availability risks that could affect other dependent services have been considered and mitigated.
Finally, planning sets the availability thresholds by which the IT service is monitored, and when warning events are identified, they are investigated to address potential issues before they result in unavailability.
Here, monitoring identifies exceptional events that have triggered unavailability. These perspectives and practices will come into play:
Availability management is designed to be a predominantly proactive practice, but this is a struggle for most IT organizations where availability is prioritized only after a downtime occurs.
The phrase “prevention is better than cure” is an apt description of the right mindset — it is easier and cheaper to implement the right service availability controls in advance than try to add them later. Once an IT service gets the notorious reputation of being unreliable, this is very difficult to shake off.
Now let’s turn to measuring your availability efforts. The effectiveness of availability management relies heavily on the measurement, analysis and report of availability of IT services and their underlying components.
The most common approach to measuring availability is as a percentage measure of actual versus agreed availability:
(agreed availability – downtime)/agreed availability
For example, for its compute service, AWS offers a regional-level SLA of 99.99% availability as well as an instance-level SLA of 99.5%. When the SLA is below the agreed target, a cloud provider would deduct a service credit from the monthly bill.
Some organizations consider the above computation as too simplistic since it does not consider the duration and impact of unavailability, as well as the cumulative impact of multiple downtimes over a period of time. Additional metrics that are considered include:
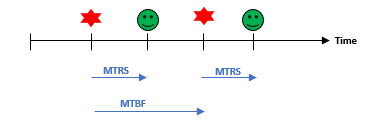
This timeline illustrates two failure metrics: MTBF, or time between failures & MTRS, time to restore service.
(Read our full explainer on MTBF, MTRS and other “failure” metrics.)
Representing availability by percentages is sometimes treated negatively by business users who may feel that the negative effect of downtimes is not captured adequately. This is termed the “watermelon effect” because IT reports everything is green through availability metrics, while users complain about poor experience, i.e. red on the inside.
Service management teams can ensure that customer experience is captured by reporting the impact of the downtimes alongside the percentage, such as:
Other applicable metrics associated with unavailability include regulatory penalties, IT asset repair/replacement costs, brand and PR damage, and lost competitive advantage.
Because availability is an essential part of the IT service lifecycle, its responsibilities are shared across the different stages. This includes business analysts, enterprise architects, solution designers, developers, systems administrators, risk analysts and business continuity analysts, as well as service desk agents, NOC analysts, and incident and problem analysts.
(Know the difference: business continuity vs. business resilience.)
To oversee the end-to-end availability from both proactive and reactive dimensions, some organizations will appoint an availability manager. This role would coordinate the activities related to:
The availability manager would not only consider availability from an IT systems perspective, but also consider the dimensions of people, process, and vendors.
In organizations that have implemented majority of the production systems on public cloud environments, the Site Reliability Engineer (SRE) has become a key role that ensures production systems remain reliable despite many updates.
SREs work closely with developers to create new features and stabilize production systems, through the use of automation tools to monitor and maintain production environments. They would also respond to instances of downtime, hold post-incident reviews, and document lessons learnt and respective solutions in the organization’s knowledge base.
Designing IT systems with availability starts from the adoption of resilience principles. Examples of resilience design principles include:
For systems deemed critical from both business and IT perspective (also known as vital business functions), designing and implementing them to become high availability systems that can operate continuously despite failures is an advanced approach that is adopted by availability management. This involves the elimination of single points of failure across all layers of the technology stack — environment, servers, applications, interfaces, etc. — through redundancy that is automatically activated whenever interruptions are detected.
Organizations can also adopt self-healing systems that promote high availability by automatically responding to errors that cause downtime through techniques such as:
Availability management is central to the success of any business that has technology as its backbone. And by incorporating availability in the requirements and designs of solutions and infrastructure, you can limit the impacts of future downtimes. But with the constant evolution of features and updates to systems, maintaining availability still remains challenging.
A concerted effort that holistically considers processes, people and vendors together with systems is the right way to guarantee reliability that meets business needs and elevates customer experience.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.