Using Splunk as a data store for developers
Tips & Tricks Nimish DoshiA number of years ago, I wrote a blog entry called Everybody Splunk with the Splunk SDK, which succinctly encouraged developers to put data into Splunk for their applications and then search on the indexed data to avoid doing sequential search on unstructured text. Since it’s been a while and I don’t expect people to memorize the dissertations of ancient history (to paraphrase Bob Dylan), I’ve decided to write about the topic again, but this time in more detail with explanations on how to proceed.
Why Splunk as a Data Store?
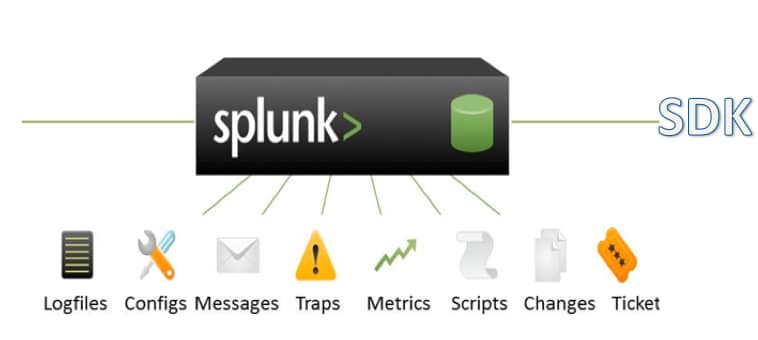
Some may proclaim that there are many no-sql like data stores out there already, so why use Splunk for an application data store? The answers point to simplicity, performance, and scale. You can easily put any type of time series text into Splunk without having to worry about its format while Splunk at the same time provides free universal forwarders to send data from remote places whether the data comes from a file, a network port, or the output of an API (known to Splunk users as scripted input). We call this universal indexing. All data separated by punctuation in the event stream gets indexed. This leads to the performance aspect. If all data is indexed, search speed is incredibly fast for any search term. To make matters even better, a computer science concept called bloom filters used in Splunk, makes searching faster than just simply indexing all the data, especially when performing needle in the haystack searches. Scale is achieved by the implicit use of the mapreduce algorithm for horizontally scaling hosts that index the data. The user of Splunk does not have to write or think about mapreduce as it happens under the covers.
Getting data in is one thing, but getting it out is quite another. The ability to use “google like” searches with AND (implicit), OR, and NOT to retrieve events makes for a natural search experience. However, the real power of Splunk is the included Splunk Search Processing Language (the commands after the pipe symbol) that do wonders for productivity and analysis. If you combine universal indexing, a scalable engine to do the work, and a comprehensive set of commands to become productive quickly, you’ll see why I recommend using Splunk as a developer data store.
Steps to get started
In this year’s blog entry on this topic, I will list out the steps for those who want to get started. I am assuming that you are a software developer that is looking into a technology to use as a data store.
-
Download Splunk and install it. You can start with the free version of Splunk. Download Universal Forwarders if you plan to send data from remote locations. If this is your first time using Splunk, try the tutorial.
-
Get Data In. After that, use the web interface to test retrieving data and to test out the Splunk search language.
-
For the software developer, use one of the open source SDKs to interact with Splunk using either Java, Python, JavaScript, Ruby, C#, or PHP. Each SDK follows this pattern to retrieve data:
- Connect to Splunk.
- Authenticate (which may be implicit with configuration files with some languages).
- Request a Search Job to execute a search. The search will be the same type of search text string you executed from the web interface.
- Iterate over the results to do something with them. Results for matching events can come back as raw text, JSON, XML, or CSV formatted.
- Disconnect, if needed.
This should get you started. More docs are at the Splunk developer website. For certain SDK languages, there may be more integrations that adhere to the culture of the language. For instance, the Java SDK works inside of Eclipse, NetBeans, and Spring.
To sum it up, the ease of getting time series data stored into Splunk with full fidelity, the ability to have it be universally indexed, the capability to scale to large amounts of data, and the inclusion of a powerful set of search commands is why I am advocating using Splunk as a data store.
P.S. In the Everybody Splunk blog entry, I started a rap, but never did finish it for the developer version. Here it is in its entirety.
Everybody Splunk.
Superstars Dunk.
Everyone say hey.
Find the needle in the hay.
Let Splunk show you the way.
Everybody Splunk.
Correlation Funk.
Everybody search.
No need to lurch.
Let Splunk show you the way.
Everybody Splunk.
Don’t be a monk.
Everyone can play.
Shorten your day.
Let Splunk show you the way.