Splunk Coalesce Command
Tips & Tricks SplunkWhen might you use the coalesce command?
“Defense in depth” is an older methodology used for perimeter security. The concept includes creating multiple barriers the “hacker” must cross before penetrating an environment.
Part of the practice of making it difficult for someone with malicious intent includes using multiple vendors at certain layers. For example, at any given moment in time, one vendor’s firewall may have exploitable vulnerabilities whereas another’s may not. Theoretically, this leaves you less exposed. Whether it is from an old defense in depth strategy or multiple corporate mergers, multi-vendor environments continue to introduce risk. As security practitioners, we’ve learned long ago that the speed and convenience of centralized management far outweighs the benefits of reducing exposure using the aforementioned technique. Even if you haven’t lived through it yourself, you’ll understand that even today, over 50% of the largest companies manage their network security manually and individually through each vendor’s console.
In these mixed environments, logging standards cannot possibly be sustained as vast amounts of “machine generated data” is created and fields within the data are labeled differently. For instance, one vendor will use “sip” to describe source IP, while another might use “src_ip”. Another example is the different EventIDs logged for different versions of Windows OSs. EventIDs for desktop firewall changes, (for example we have 852, 4946, 4947 or 4948) but they all represent the same event.
Enter coalesce to solve this problem.
As you will see in the second use case, the coalesce command normalizes field names with the same value. Coalesce takes the first non-null value to combine.
In these use cases you can imagine how difficult it would be to try and build a schema around this in a traditional relational database, but with Splunk we make it easy.
Coalesce:
Sample data:
Thu Mar 6 11:33:49 EST 2014 src_ip=1.1.1.1
Thu Mar 6 11:33:45 EST 2014 sourceip=8.1.2.3
Thu Mar 6 11:33:48 EST 2014 source_ip=1.1.1.0
Thu Mar 6 11:33:47 EST 2014 sip=1.1.1.199
Thu Mar 6 11:33:46 EST 2014 ip=
Thu Mar 6 11:33:46 EST 2014 ip=22.22.22.22
Here we are going to “coalesce” all the desperate keys for source ip and put them under one common name src_ip for further statistics.
For this example, copy and paste the above data into a file called firewall.log. Then use the oneshot command to index the file:
./splunk add oneshot “/your/log/file/firewall.log” –sourcetype firewall
<pre>sourcetype=firewall
|eval src_ip = coalesce(src_ip,sourceip,source_ip,sip,ip)</pre>
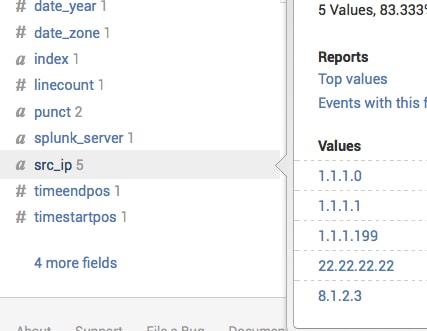
Here is another example of the use and powerful nature of the coalesce command:
Wed Mar 12 10:53:55 EDT 2014 bytesIN=10000000000
Wed Mar 12 10:53:55 EDT 2014 bIN=10000000000
sourcetype=firewall
| eval TotalGBIn = coalesce(bytsIN, bIN)/1024/1024/1024
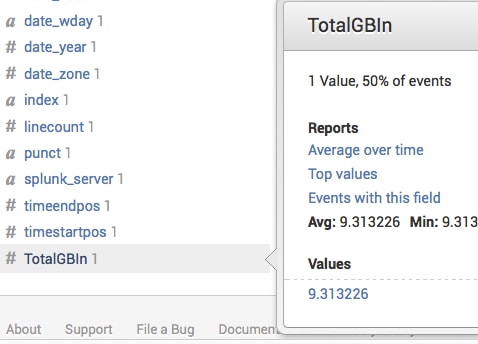
In the above use case, you may have a field such as bytesIN and bIN, representing the same value at any given point in time. The command coalesce only takes the first non-null value in the array and combines all the different fields into one field that can be used for further commands.
Happy Splunking!