Use Cloud Infrastructure Data Model to Detect Container Implantation (MITRE T1525)
Security Rod SotoA unified cloud infrastructure data model is fundamental for enterprises using multiple cloud vendors. Enterprise customers prefer to use multiple cloud vendors as a way to prevent being locked in and dependent on specific platforms. According to Gartner the top vendors for cloud infrastructure as a service in the years 2017-2018, are Amazon 49.4%, Azure 12.7% and Google with 3.3%. These three vendors have different products, services and logging nomenclatures that makes it difficult for the enterprise to have a unified visibility when managing data from the different cloud providers.
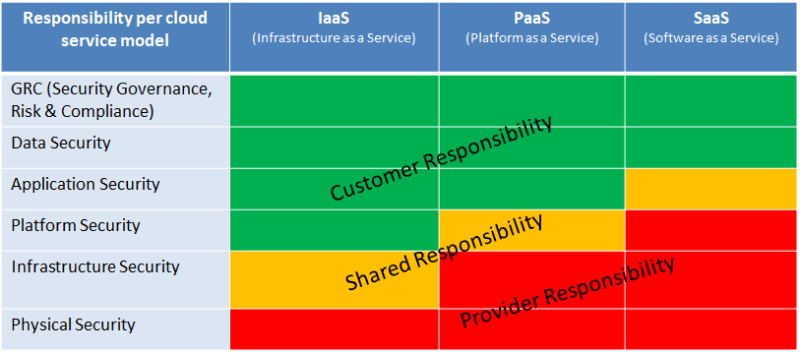
The Blurry Line Between Provider and Customer Responsibilities…
There are popular misconceptions about the ownership of responsibilities between cloud adopters and providers, when operating in the cloud is only related to customer data.
Shared Responsibilities by Cloud Service Model

Source Peerlyst
{kind=link}
This blurry line is one is just one element of a bigger challenges which include:
- Cloud provider’s customers do not have a clear understanding of the security risks and data ownership boundaries between cloud real estate and perimeter security. Without proper visibility, customers are potentially exposed to threats.
- Vendor competition with different services and evolving standards presents a challenge for customers with multiple cloud vendors.
- Market does not have a unified criteria for different cloud services, this leaves every customer creating their own, furthering confusion and lack of consensus.
- Cloud security standards are recent and evolving, introducing new challenges in security compliance, risks and threats.
Another important element to consider when addressing proper visibility is the distribution of outward facing and inward facing cloud applications in enterprises.
Percentage of Applications Facing Internally, Externally and Both

Source CSA
Having the ability to monitor and visualize multiple vendor cloud operations in a unified manner improves the ability of IT and Security analysts to monitor, detect and investigate operational issues as well as security threats. This can be difficult to achieve, especially as main vendors do not cooperate amongst each other and in some cases do not even provide data from their proprietary offerings, but there are ways to approach this challenge.
The Splunk Security Research Team has identified six initial main categories that can group together the three major cloud providers to begin to address visibility across multi-cloud environments. These categories were selected after researching log data from cloud customers use of services from the three major vendors.
- Compute: Artifacts such as virtual machines, containers, apps, microservices.
- Storage: Storage type (block, object, file).
- Management: Management access, logging setup,kubernetes flavor.
- Network: External access, VLAN/VWAN, VPN, routing
- Database: SQL or NoSQL
- Security: IAM, Encryption and Firewalls
Splunk Unified Cloud Data Model
As more enterprise organizations continue to move to the cloud using multiple cloud providers, it's important to have visibility into your data across the multiple cloud platforms. The Splunk Security Research Cloud Infrastructure Data Model normalizes and combines cloud generated data from AWS, Azure, and GCP, so you can write analytics that work across all three major vendors.
Features of this Data Model include:
- Provides a data model suitable for normalizing some of the data coming from AWS, GCP, and Azure.
- Blocks for compute (VM Instances), storage, network traffic, and authentication/authorization
- Includes additional eventtypes, field aliases, tags, and calculations to help populate the model.
- Provides data-model mapping for:
- Basic VM activity (start, stop, create, terminate).
- Basic bucket/object activity for storage use cases.
- Network traffic, as provided by vpc flow logs, and gec_instance events for GCP.
More information on Data Model prerequisites and specifics of the data model can be found here.
Putting it Together
The unified cloud infrastructure data model initially covers 4 main areas.
- Compute: i.e VM instances
- Storage: i.e buckets
- Traffic: i.e flow logs
- Authentication/Authorization: i.e Roles, API Access
Once the prerequisites and source types are met, the log information is normalized and displayed
Compute
In the compute category we group log information related to virtual machines, containers, regions, users, interacting user-agents and compute engine events in general.

Storage
In the storage category we group log information about storage centric (Usually buckets) accounts, entities, actions, regions, IP addresses, storage types, path of storage objects, etc.
Traffic

The traffic category groups network derived events, such as IP addresses sources, destinations, ports, packet stats, cloud traffic rules, TCP/IP protocols, etc.
Authentication/Authorization

The authentication category addresses security, authentication and authorization items such as authentication tracking events, roles, assumed or impersonated roles, identity groups, identity providers, multi factor authentication settings, etc.

Applying the Unified Cloud Infrastructure Data Model to Security
Once we have vision in these 4 areas, we can utilize this data for detection and investigations of security threats. One way of applying this data focusing on security threats related tactics, techniques and procedures, can be accomplished by using the recently published MITRE Cloud Attack Matrix as reference.
MITRE Attack Cloud Matrix

Source MITRE
Detecting Implant Container Image MITRE Cloud ATT&CK T1525
In the following example we will perform a detection using data normalized from the Unified Cloud Infrastructure Data Model. The scenario of MITRE ATT&CK T1525 assumes an user account with enough privileges to manage containers has had their credentials compromised or a service account with such roles has been compromised as well.
GCP Permissions for Google Container Registry *

AWS Permissions for Amazon Elastic Container Service *
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:DescribeTags",
"ecs:CreateCluster",
"ecs:DeregisterContainerInstance",
"ecs:DiscoverPollEndpoint",
"ecs:Poll",
"ecs:RegisterContainerInstance",
"ecs:StartTelemetrySession",
"ecs:UpdateContainerInstancesState",
"ecs:Submit*",
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}
This scenario falls within the CI/CD Devops attack surface. The components of this attack surface usually fall under:
- Source code repository: Bitbucket, Beanstalk, Github, Gitlab, SVN, S3 buckets
- CI/CD platform: TravisCI, Jenkins, CircleCI, Gitlab
- Container repository: Docker, Vagrant (Amazon ECR, Google Container Registry, Azure Container Registry)
- IaaS Provider: Kubernetes flavor, OpenStack (this may also be local in some private, hybrid environments)
- IaC: Ansible, Terraform, Chef, Cloudformation
MITRE ATT&CK Cloud T1525

We will use Rhino’s security Cloud Container Attack Tool, to implant a backdoor in a container.

Once we upload an implanted container to the Container Registry and this container is deployed, we can then detect container implantation by using the following indicators:
In AWS
- API User Agent
- ECR Enumeration
- API IP geolocation
The following are searches designed to detect use of 2 user agents by 1 API Token.


We can also search for “PutImage” which indicates the uploading of a container image to the Elastic Container Registry.
In GCP
In the case of GCP when container images are pushed into a private container registry using Google Container Registry, the images are stored in a bucket and the transaction will be recorded under an specific bucket, from an specific account and with destination showing the SHA256 digest. We can use the same CCAT tool to explore a public Google Container Registry repository.
Figure Shows CCAT Tool Enumerating Public GCR Repository

Figure Shows Unified Data Model Base Search for GCP Showing Container Creation
| datamodel Cloud_Infrastructure Storage search | search Storage.event_name=storage.objects.create | table Storage.src_user Storage.account Storage.action Storage.bucket_name Storage.event_name Storage.http_user_agent Storage.msg Storage.object_path
Figure Shows Splunk Cloud Infrastructure Data Model on GCP Container Creation

Once in the GCR we can also cross reference using the upcoming Kubernetes updates to the Splunk Security Research data model.

Based on the above data there are some items to review to detect implanted containers:
- Source user pushing container
- The bucket name where the container is being created
- The timestamp of container creation
- Container deployment to clusters as in the next figure

Finally, we can also create alerts when vulnerable containers are uploaded to the container registry. The following is an example of GCR Vulnerability Scanner engine results on our uploaded backdoored/implanted container.

The following is a grouping of alerts by container occurrences and container vulnerability alert from GCR vulnerability scanning. This base search can be used to create alerts.
index=gcp_gcr data.kind=VULNERABILITY "data.notificationTime"=* "data.name"=* |table data.kind data.notificationTime data.name | rename data.kind AS "container_alert", data.notificationTime AS "notification_time", data.name AS "container_occurrence"

The Splunk Security Research Team is focused on developing security analytics based on a unified security posture for all major cloud security providers. Please visit our github site or install the ESCU app for the latest security content. You can also reach out to us via email research at splunk.com.
About the Splunk Security Research Team
The Splunk Security Research Team is devoted to delivering actionable intelligence to Splunk's customers, in an unceasing effort to safeguard them against modern enterprise risks. Composed of elite researchers, engineers, and consultants who have served in both public and private sector organizations, this innovative team of digital defenders monitors emerging cybercrime trends and techniques, then translates them into practical analytics that Splunk users can operationalize within their environments. Download Splunk Enterprise Security Content Update in Splunkbase to learn more.
Related Articles

Detecting Clop Ransomware

Turning Hunts Into Detections with PEAK
