The shift to cloud-native infrastructure has transformed how we collect, store, and analyze metrics — bringing massive increases in data volume and cardinality.
In this article, we explore the concept of cardinality and its growing importance in modern monitoring and observability systems, especially in cloud-native environments.
What is cardinality?
Cardinality refers to the number of unique values in a dataset or field. A field or dataset may be either high cardinality or low cardinality:
- A field containing user IDs or transaction types may have thousands of distinct entries — this is high cardinality.
- In contrast, a field like "status" with values like "success" or "error" would have low cardinality because there’s only a few distinct values, repeated.
In the context of observability, cardinality determines how finely we can slice and analyze our metrics. High cardinality provides rich insight but introduces challenges around scalability, performance, and cost. (More on these challenges later.)
See how low vs. high cardinality compares:
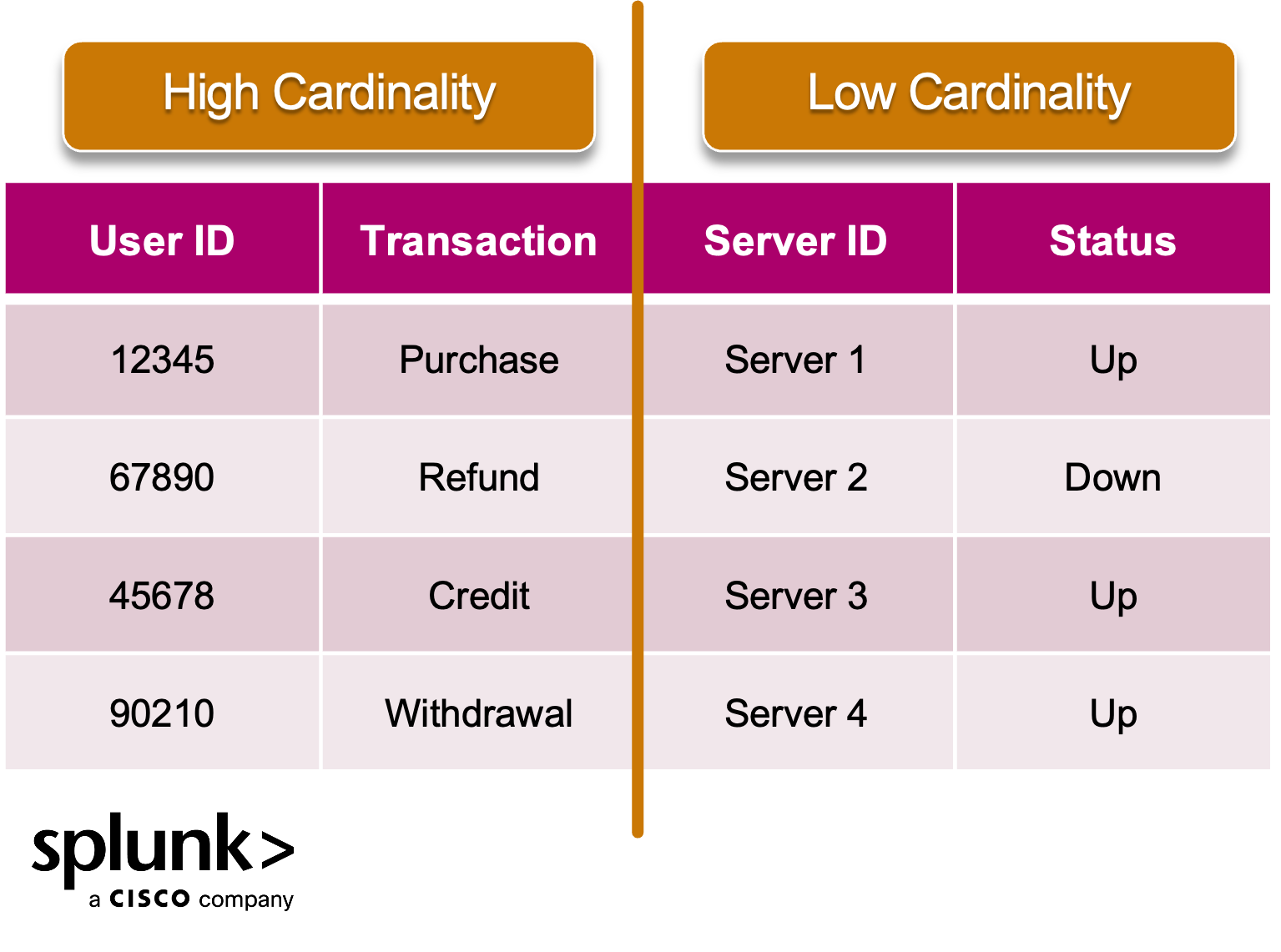
This infographic illustrates the difference between high and low cardinality in monitoring metrics. High cardinality involves many unique values — such as user IDs or transaction types — enabling granular insights but increasing system load. Low cardinality metrics, like server status or boolean flags, offer broader trends with less overhead. Understanding the trade-offs is key to designing efficient observability systems.
Cardinality metrics
In monitoring and observability systems, the term “cardinality metrics” refers to metrics that track the number of unique combinations of a metric name and its associated labels or dimensions.
Here’s an example: A metric might be something like http_requests_total. Labels/dimensions are additional data points that give context, like:
- method=GET
- status=200
- region=us-west
Each unique combination of these label values creates a new time series. The more unique combinations, the higher the cardinality.
So, let’s say a simple app has 10 HTTP methods, 50 status codes, and 20 regions, you could have 10,000 unique time series, just for a single metrics.
Why cardinality matters for monitoring and observability
High cardinality fields enable granular tracking of individual records or events. In monitoring, high cardinality helps to:
- Differentiate between multiple instances of a service.
- Track performance metrics per user or region.
- Detect anomalies that broad aggregations might miss.
Observability takes things further — combining logs, metrics, and traces to deliver a complete picture of system behavior.
High cardinality is critical for debugging distributed systems because the higher the detail, the easier it is for engineers to trace individual user requests across microservices, identify anomalies within specific regions or clusters, and analyze vast datasets without losing crucial details.
We can sum up how high cardinality is so valuable, because it delivers:
- Granular insights of individual services, endpoints, users, or transactions. This allows for precise anomaly detection and root cause analysis.
- Improved filtering and querying thanks to high-dimension data based on specific attributes — region, customer ID, API version, for example — speeds up problem identification and diagnosis.
- Enhanced customization and flexibility means teams can create tailored dashboards, alerts, and reports using unique combinations of metric dimensions, leading to more meaningful insights.
Challenges of high cardinality
Despite its benefits, high cardinality introduces significant operational challenges:
- Scalability. Each unique combination of metric and label results in a new time series. This can quickly escalate to millions of series, overwhelming traditional time series databases (TSDBs).
- Storage overhead. High cardinality metrics consume more storage, especially as time series grow with constant inserts. Efficient retention, aggregation, and compression strategies become essential.
- Query performance. Complex queries across high-cardinality data are slower and more expensive to compute, especially when joins or long time ranges are involved.
How modern systems handle these challenges
Modern observability platforms like Splunk Observability Cloud are built to support high cardinality at scale. These platforms:
- Index all metric tags equally.
- Enable fast queries across millions of time series.
- Provide real-time alerting without performance trade-offs.
Platforms like Splunk handle high cardinality and high dimensionality data, allowing users to freely query and filter on any attribute regardless of its cardinality.




