
The Essential Guide to SIEM
Ready to level up your threat detection? Get your SIEM guide today.

Key takeaways
How do you know when something is wrong? Often, it’s not “normal” or expected behavior.
Anomaly detection is the practice of identifying data points and patterns that deviate from an established norm or hypothesis. As a concept, anomaly detection has been around forever.
Today, detecting anomalies today is a critical practice for organizations and companies of all sizes and stripes. That’s because identifying these outliers can power important activities, such as:
So, here, let’s look at the wide world of anomaly detection. We’ll look at how AD works, techniques for detection, ways to use it in the workplace, and solving common challenges.
(Anomaly detection is essential to many Splunk services and products, including our industry-leading SIEM platform and our full-stack observability portfolio.)
Anomaly detection includes any technique that helps find data points or events that deviate from “normal” or expected behavior. For decades, anomaly detection was manual work. Only in more recent years has machine learning, automation, and yes, AI, are making it easier and more sophisticated to detect anomalies in all sorts of environments.
So, what is an anomaly?
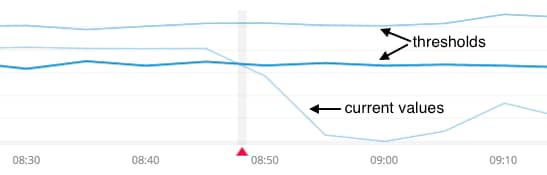
Any data point or pattern that may deviate significantly from an established hypothesis or from pre-determined thresholds. Let’s illustrate this with some real-world examples.
A go-to example of anomaly detection is a credit card fraud detection system. This uses algorithms to identify unusual spending patterns in real-time: large purchases in a new location, for example, This alert for potentially fraudulent activity is then reviewed by the bank directly. How does it achieve this? By picking up on anomalous purchases within a customer's typical spending behavior.
Other examples of anomaly detection systems include:
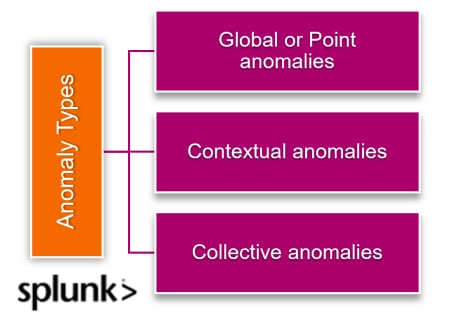
When looking at a time series of data — data that is collected sequentially, over a period of time — there are three main types of anomalies, which we’ll demonstrate with a classic example:
Global anomalies (aka point anomalies): This anomaly is a piece of data that is simply much higher or lower than the average. If your average credit card bill is $2,000 and you receive one for $10,000, that’s a global anomaly.
Contextual anomalies: These outliers depend on context. Your credit card bill probably fluctuates over time (due to holiday gift giving, for example). These spikes may look strange if you consider your spending in the aggregate, but in the context of the season, the anomaly is expected.
Collective anomalies: These anomalies represent a collection of data points that individually don’t seem out of the ordinary but collectively represent an anomaly, one of which is only detectable when you look at a series over time.
If your $2,000 credit card bill hits $3,000 one month, this may not be especially eyebrow-raising, but if it remains at the $3,000 level for three or four months in a row, an anomaly may become visible. Collective anomalies are often easiest to see in “rolling average” data that smooths a time series graph to more clearly show trends and patterns.
When building an anomaly detection model, here’s a question you probably have: “Which algorithm should I use?” This greatly depends on the type of problem you're trying to solve, of course, but one thing to consider is the underlying data.
Talking about anomaly detection techniques easily overlaps into technical areas like statistics and machine learning. That’s because AD techniques can be categorized into three primary types:
There are countless ways to identify these outliers, ranging from simple to sophisticated: sorting your data/spreadsheet, visualizing the data using graphs, charts, etc., looking at z-scores, creating outlier fences using interquartile ranges — among many others.
Some common AD algorithms and techniques include:
Local outlier factor. A common technique that compares the local density of an object to its neighboring data points. If the object has a lower density, it's considered an outlier.
Isolation forest. An efficient method that's relatively low complexity and consumes low CPU and time. However, it's not adapted to data stream contexts.
Nearest neighbors. A classic in the AD world, nearest neighbors is a successful and long-standing technique.
Intrusion detection. Compares normal data packets with incoming data packets to detect malicious data packs.
Autoencoder. A technique used in deep neural networks to identify anomalies in robotic sensor signals.
Additional techniques, though by no means all of them, include machine learning AD, clustering algorithms, and hybrid approaches, which may combine anomaly- and signature-based detections.
(Related reading: Splunk App for Anomaly Detection.)
In the context of time-series continuous datasets, the normal or expected value is the baseline. The limits around that baseline represent the tolerance associated with the variance. If a new value deviates above or below these limits, then we can consider that data point to be anomalous.
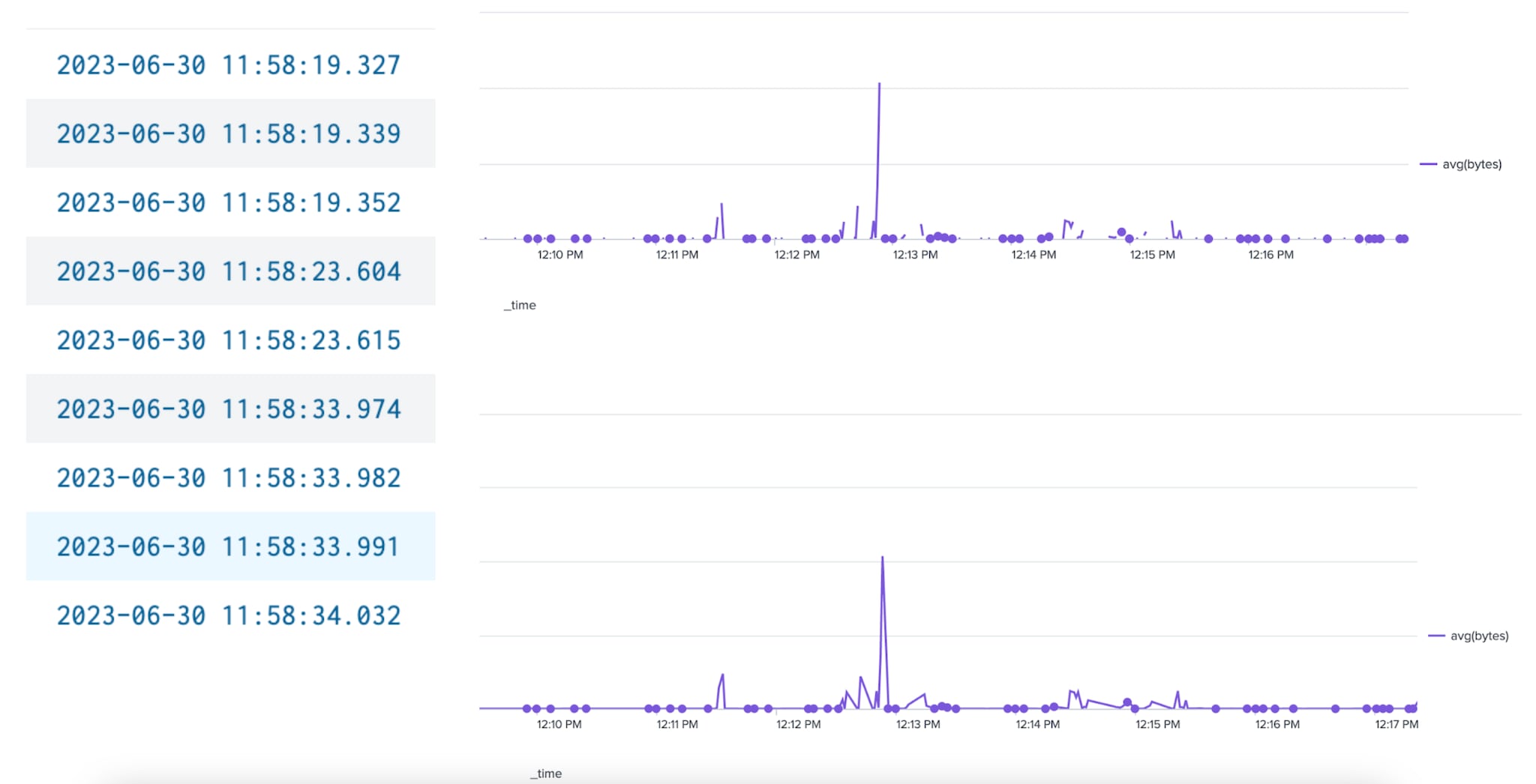
Anomaly detection is a very common way that organizations today harness machine learning. We know, of course, that accurate anomaly detection relies on a combination of historical data and ongoing statistical analysis. Importantly, these models are highly dependent on the data quality and sample sizes used that affect the overall alerting.
(Related reading: exploratory data analysis for AD.)
First things first: anomalies may be introduced by a variety of reasons depending on the environment. Considering the case of network traffic flows, from above, a surge in user traffic could stem from a variety of situations:
Anomalies can emerge from a variety of sources. In order to fully understand the underlying causes, the following key challenges are addressed as part of the anomaly detection process:
Defining a universal hypothesis is already near-impossible. It’s often implausible to define a model that encompasses all data dimensions (factors and the applicable constraints) and quantifying intangible qualitative metrics (such as user preferences and intent) is doubly challenging.
Defining “anomaly” is not easy. That’s because the answers often are not black/white issues: instead, there’s many shades of grey. First, the notion of “anomaly” deviates highly between the application of and the sensitivity of the situation. An example:
In cybersecurity, threat actors know how to hide their anomalous behavior. These adversaries can quickly adapt their actions and/or manipulate the system in a way that any anomalous observations actually conforms to the acceptable models and hypothesis.
Normal or expected behavior is dynamic. The notion of normal and expected behavior evolves continuously, especially in large organizations. Internal organizational changes and a growing user base may require decision makers to redefine things like:
Trusting the model. Any AD system must establish trust with its users. Without the trust, why would we run business-critical activities over that data? One “trustworthy” area to get right is that the users must believe, know, trust that the model is indeed finding all outliers, or at least the ones deemed relevant by your own settings.
We’ve looked at the conceptual challenges of anomalies and detecting them. Now let’s look at the practical side: the real issues your teams may face when handling anomalous behavior – we’ll look at the challenge and then offer some paths towards solving them.
Data quality — that is, the quality of the underlying dataset — is going to be the biggest driver in creating an accurate usable model. Data quality problems can include:
How to solve data quality issues. So, how do you improve data quality? Here are some best practices:
Having a large training set is important for many reasons. If the training set is too small, then…
Seasonality is another common problem with small sample sets. Not every day or week is the same, which is why having a large enough sample dataset is important. Customer traffic volumes may spike during the holiday season or could significantly drop depending on the line of business.
It’s important for the model to see data samples for multiple years so it can accurately build and monitor the baseline during common holidays.
How to solve for lack of dataset size. Unfortunately, thin datasets are the most difficult problem to solve. If you don’t have “enough” data, you’ll need more. You’ll have to capture real data within the wild to get an accurate understanding of what’s considered normal.
You could build synthetic datasets by extrapolating on current datasets, but this will likely lead to overfitting.
Identifying anomalies is an excellent tool in a dynamic environment as it can learn from the past to identify expected behavior and anomalous events. But what happens when your model continuously generates false alerts and is consistently wrong?
It’s hard to gain trust from skeptical users and easy to lose it — which is why it’s important to ensure a balance in sensitivity.
How to solve for model sensitivity. A noisy anomaly detection model could technically be right in the alerting for anomalies; but it could be written off as noise when reviewed manually. A reason for this is the model sensitivity. If the limits are too tight around the baseline, then it may be common for normal variance to deviate away from that baseline.
To solve this, you could:
Another solution to fix false alerting would be to increase the sample size the algorithm used to build the model. More examples of historical data should equate to higher accuracy and lower false alerts.
Another method of building an anomaly detection model would be to use a classification algorithm to build a supervised model. This supervised model will require labeled data to understand what is good or bad.
A common problem with labeled data is distribution imbalance. It’s normal to have a good state which means 99% of the labeled data will be skewed towards good. Because of this natural imbalance, the training set may not have enough examples to learn and associate with the bad state.
How to solve imbalance. This is another problem that can be hard to solve. A common technique to get around this includes scaling down the number of good states to be more equal to the number of bad states. Ideally, you should have enough bad states (i.e., anomalous states) so the model can accurately learn and reinforce its behavior.
Because of this imbalance distribution, it’s likely you may not have enough labeled data to learn from those bad (anomalous) states.
Once an anomaly has been identified, it’s important to act on that insight and quantify the impact on that anomaly. A good strategy is to:
To summarize, anomaly detection is about defining normal behavior, developing a model that can generalize such a normal behavior and specifying the thresholds for observations that can be accurately deemed as a significant variation from the expected true normal behavior.
How your organization uses this information, however, is up to you. And THAT is where the good stuff happens.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.


The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.