
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

Amazon Web Services (AWS) Elastic Block Store (EBS) is used to provide disk volumes for Elastic Compute Cloud (EC2) instances. It’s elastic because it allows users to quickly create volumes based on their needed size and performance. EBS also offers greater durability by automatically replicating within an availability zone, making it easy to setup encryption and create snapshots.
Since disk volumes are a foundational resource for operating systems and their applications, it’s important to monitor them to ensure your application’s availability. If your disk has hit a performance limit, it can slow down your application. If the disk is full, it may even crash the server.
From a performance perspective, each EBS volume has a maximum read latency and throughput rate determined by the type of volume you’ve chosen. Hard disk drives (HDD) have a very high throughput rate for sequential writes, but have a higher latency and lower throughput for random reads and writes. Since most systems run several applications that require reading from a variety of locations, it can be faster to run your instance on a solid-state drive (SSD). If your application is primarily limited by I/O operations per second (IOPS), Amazon also provides the ability to purchase provisioned IOPS, which reserves a set capacity. The only way to know if you are hitting one of these performance limits is by monitoring your EBS volumes. Amazon provides a very useful view into these DevOps metrics through CloudWatch. You can then use these metrics to optimize your use of EBS volumes.
The other important characteristic to consider is cost. Obviously, if your instances are configured for much more volume than you need, you’ll be wasting money. You can switch to smaller size volumes if you have a good monitoring system that will alert you when you’re nearing a limit.
Additionally, there is a 500% difference in cost per GB between the least expensive HDD volume and the most expensive SSD volume type. Monitor your application’s IOPS and throughput during peak usage or stress test to determine if they are a critical factor in your application performance. If your application is CPU-limited or memory-limited, you might be able to save money by switching to a lower-cost volume type.
Splunk Infrastructure Monitoring offers a great dashboard straight out of the box so that you can easily get insight into these factors without having to set up your own trend graphs. Take a look at the dashboard below to get an overview of the metrics we make available by default:
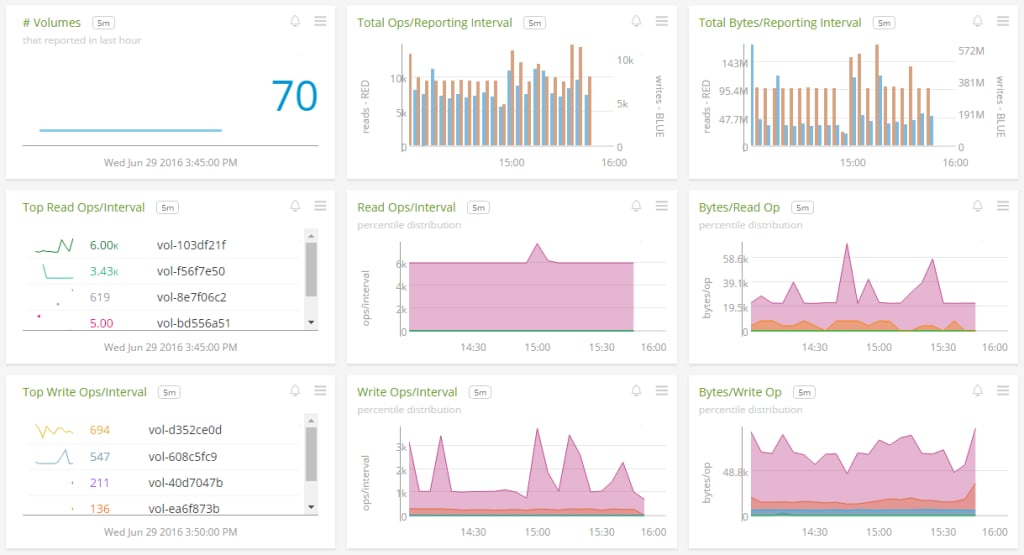

The first item in the dashboard is the number of volumes you currently have in your account. The number of volumes is correlated with your cost. If you have way more volumes than instances, some of them are likely no longer needed. The AWS console will give you additional information, including whether each volume is currently in use and the type of each volume. If you have volumes that are not in use, you should consider cleaning them up.
We show you the total I/O operations and throughput across your entire cluster. This gives you an idea of how much capacity you’re using in aggregate. On these charts, the read metrics are shown in red and the write metrics are shown in blue. The reporting interval is currently set at five minutes. Large spikes might indicate a system-wide activity pattern, like a sudden increase in traffic to your website. A good load balancer would distribute traffic, so you’d expect to see a fairly even distribution across your servers.
Next, we give you a breakdown of your read operations both by the top volumes and by a percentile distribution. This will help you determine which volumes are using the most read operations. Furthermore, the percentile time series chart will show you how many servers are affected and how the load changes over time.
In the example below, we see that there is a large pink area on the Read Ops/Interval chart. Pink is used for the max, and since the rest of the colors are relatively small, those servers appear to be outliers. It’s also not a temporary spike, because it is using that much capacity continuously. Looking at the top chart, we see the two volumes responsible are vol-103df21f and vol-f56f7e50. We should investigate these volumes more closely to determine that the servers are operating correctly, and if so, whether read IOPS has become a performance bottleneck.

We can also see the number of bytes per read operation. This will give us a clue as to how many volumes are experiencing small reads versus large reads. If you have many small reads, you might be better served with an SSD because they have more IOPS capacity. If you hit the IOPS limit, you can get more by purchasing provisioned IOPS. HDDs have the advantage of a higher 1k maximum IO size (or block size), so you can read more data in a single operation. If you have large read operations, you might benefit from greater throughput offered by an HDD.
Write operations are reported similarly to read operations. This helps you determine how many servers are experiencing a high number of write operations through the percentile distribution, as well as the top table so you can see which volumes are affected. Likewise, you can see the number of bytes per operation, which could help you provision the best type of volume.
The queue length is defined as the number of read and write operations that are waiting to be completed. If your application has a high number of IOPS, you might be able to decrease the latency by keeping a low queue length. A higher queue length allows you to achieve higher throughput due to sequential reads or writes but at potentially a lower latency. To optimize performance, Amazon offers a rule of thumb in benchmarking EBS volumes. SSDs should have a queue length of 1 per 500 IOPS, and HDDs should have at least 4 while performing 1 MiB sequential I/Os.
The latency reported here is the end-to-end time to complete an I/O operation. It’s reported as a percentile distribution so you can see a variety of statistics including the average and maximum times. If you notice that your latency is higher than expected, it might be because you hit the limit on IOPS or throughput or your queue length is not optimized for your volume type.
Splunk Infrastructure Monitoring also provides access to metrics on a per-volume basis. These types of metrics are more useful when drilling down to troubleshoot issues with a specific volume.
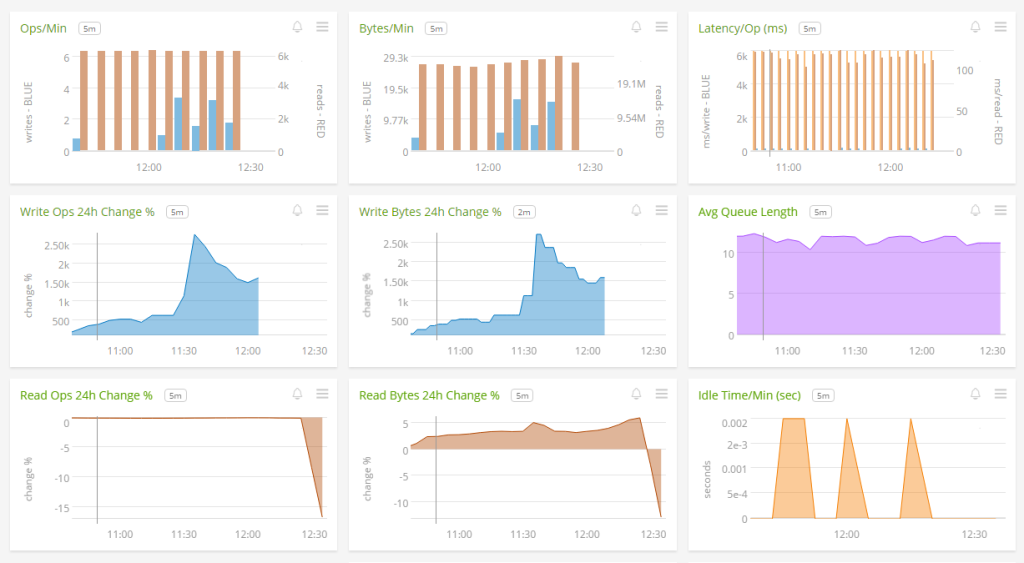

The first row of charts in the graph above show operations per minute, throughput, and latency. Writes are shown using the blue color, and reads are shown using a red color. These are very similar to the metrics shown on the aggregated volume dashboard discussed in the first section, except they are only for a single volume. This view shows us that our application has much more reads than writes and the latency for reads is quite high.
We can also see the write operations and throughput as a percent change relative to 24 hours ago. In both of these charts, we can see that around 11:30 there was a big increase in write operations and throughput. However, there was not a large change in the read operations or throughput at the same time, which is shown in red.
The average queue length remains fairly steady over time and at a fairly high level, indicating that the discs are being used at near-full capacity. This is also confirmed by the chart showing the idle time is very low.
Lastly, the average bytes per read and write operation are shown. Both of these are very small, in fact smaller than a typical disk block size. If the reads are random, you might be able to increase performance by optimizing for sequential reads so that multiple read operations can be combined into a single one.
Splunk Infrastructure Monitoring also provides access to a lot of other information that gives you wider visibility into your system status and lets you drill down fast when you’re investigating issues.
Amazon CloudWatch makes additional metrics available including volume total write time and volume total read time. These tell you the total time to complete all the operations submitted within a certain range of time. For example, if it takes longer to complete all submitted operations than a set five-second interval, this could give you a clue as to what might be causing latency issues.
It might not be immediately intuitive, but network utilization is important if you’re not on what Amazon calls an “EBS-optimized instance.” Since EBS volumes are networked disks, I/O operations need to be sent over the network interface. That means if you’re using a lot of network bandwidth, it could lead to increased disk latency and reduced throughput. EBS-optimized means Amazon sets aside dedicated network capacity for your disk operations. It’s a little more expensive but can lead to much better performance.
Surprisingly, CloudWatch does not offer metrics about the size of your volumes or what percent of it is used. It’s important to monitor disk size because, if your server runs out of disk space, it can become unstable or crash.
We recommend using a monitoring agent such as collectd along with the df plugin to monitor disk usage. Our plugin for collectd also computes additional metadata, making it easier to analyze. For example, disk.utilization offers a metric describing what percent of your disk is used. Below, you can see that a couple of volumes are in the 60% range, and the rest are vastly underutilized.
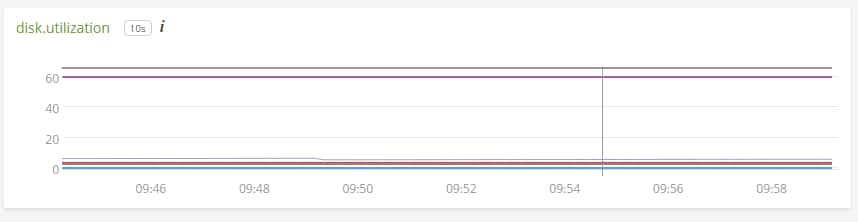
Other collectd plugins can give you insight into page file usage, disk operations by process, file counts, network usage, and more. If you’re trying to hunt down what’s causing extra I/O operations, these metrics can give you the insight needed to optimize your systems.
SignalFlow is the advanced analytics engine that allows you to take standard metrics and easily derive new and more intelligent signals to monitor your systems and applications in real time without having to learn a new programming language or dealing with delayed data. It allows you to calculate new fields, to observe trends before they affect your users, compare different moments in time, and even predict when a resource will run out of capacity. Furthermore, it performs these calculations on the data as it streams, so your dashboards and alerts are always up to speed and you can react when it matters most.
In the example for disk utilization above, the percentage of disk used was calculated using data from the df_complex plugin as follows:
100 * [df_complex.used / (df_complex.free + df_complex.used)]
Splunk Infrastructure Monitoring did this calculation automatically so I didn’t have to enter any formulas, it just worked out of the box.
I can also create my own custom calculations. For example, let’s say I want to be notified when there is a large percentage change in disk usage from yesterday. If I’m expecting my disk utilization to be fairly steady, a big spike could indicate a problem.
In the example below, I’ve created a dynamic alert detector by quickly applying a formula right within the Splunk interface. The first line of the formula in Row A gets the disk utilization on my Couchbase host and calculates the mean over the last 24 hours. Row B takes the metric in Row A and shifts it by one day. Row C then calculates the percent change from yesterday as (A-B)/B*100.
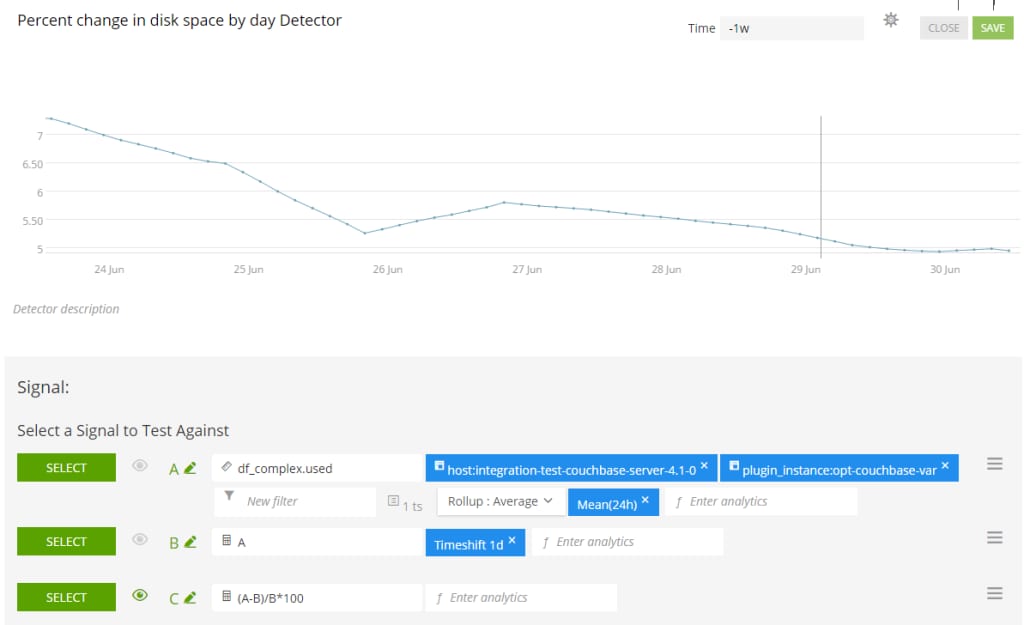
Next, I’ve set up a threshold that will alert me if the change in disk space has increased by 30% or more since yesterday. I can choose to send notifications over PagerDuty, Slack, HipChat, email, or other alerting platforms, as well as applying a webhook.
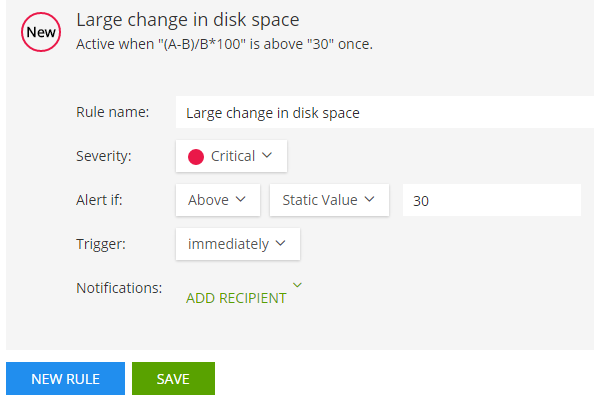
This is only one example of what you can do a SignalFlow analytics to get highly relevant alerts with fewer false-positives. You can create any number of calculations and customize them exactly as you want. Our integration with Amazon CloudWatch makes it so easy that it only takes a few minutes to try out.
Get visibility into your entire stack today with a free 14-day trial of Splunk Infrastructure Monitoring.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.