Consolidation with Splunk
Customers & Community Nimish DoshiSplunk is committed to using inclusive and unbiased language. This blog post might contain terminology that we no longer use. For more information on our updated terminology and our stance on biased language, please visit our blog post. We appreciate your understanding as we work towards making our community more inclusive for everyone.
One of the things I do regularly here at Splunk is talk to customers. Some are using Splunk for its full potential beyond search and indexing for in-depth analysis of their data with full use of the search language, comprehensive dashboards, and timely alerts. Then, there are some who use it for a single purpose such as monitoring logins, auditing operations, or general purpose troubleshooting. This, in itself, allows Splunk to show value for the task at hand. However, these same customers may also be using several tools and technologies for tasks which may be consolidated with Splunk. What follows is a discussion for using Splunk to monitor several aspects of a business, some by simply reusing the same indexed data for the different purposes. Consolidation may save on maintenance, training, costs, and provide a return on investment that could be used for other endeavors.
Troubleshooting
This is the usual topic people discuss when Splunk is first introduced in the conversation. All your ascii text machine generated data can be indexed in a time series data store for central access to different people based on their roles for reasons that have to do with application and operations support troubleshooting. With the ability to search all your indexed data from a central console, what used to take hours and possibly days can be done in minutes and seconds with centralized search. This also solves the “data butler” problem as dedicated people do not need to be called constantly to deliver logs for those who are investigating issues.
Availability
As soon as you start indexing data for troubleshooting and maintainability for operations, the question of application availability comes into play. Some common patterns in your data such “Weblogic is shutting down” or “disk is full, DB service has stopped” may be enough to monitor for proactive alerts. There are numerous examples of monitoring different devices, platforms, and applications on Splunkbase that directly or indirectly address this customer problem. For example, if your application server is sending a periodic heartbeat over multicast, Splunk can monitor this heartbeat, where the absence of heartbeats on expected intervals may indicate downtime.
In general, a simple search such as:
sourcetype=<name your sourcetype>|stats count
can tell you the number of events that are returned in a time interval. If the number is zero, alerts may be triggered.
Resource Consumption
While you are monitoring applications for operations support and availability, it may also make sense to forward machine consumption data such as CPU usage, disk usage, memory availability usage, and network consumption. Fortunately, the Splunk for Unix app and Splunk for Windows app do these tasks, among other things, right out of the box. The app user also has the ability to disable inputs that are not needed to be consumed to be indexed and provide custom intervals when data needs to be collected. This allows Splunk to play a role in capacity planning. Below are some standard screen shots of these apps.
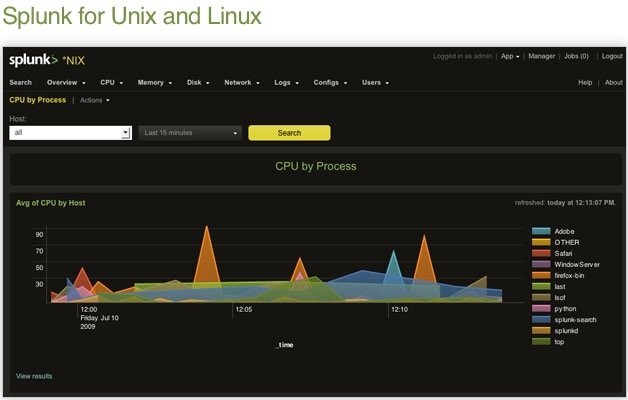
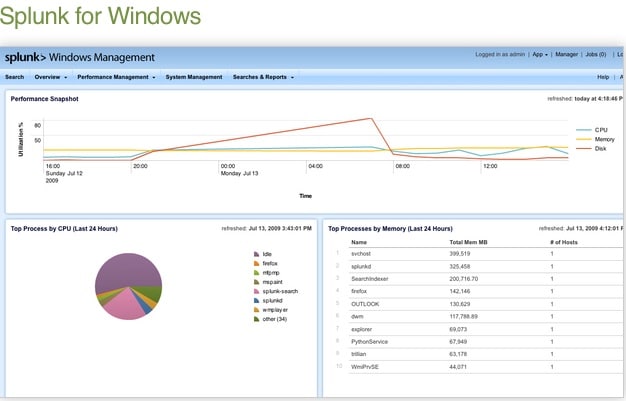
Change Management
As you are now monitoring your applications for operations support, availability, and capacity planning, it may also make sense to forward any file system changes to Splunk for change management. The Splunk instance that is running on these same machines can be configured to monitor changes to the file system and forward both the meta data about the changes (such as what file changed, when it changed, and who was the user that did the change) and optionally the changed file itself to the Splunk indexer. A change, by the way, is an addition, update, or delete to any monitored directories’ files. The text for this event action may look like this:
Mon Mar 16 18:19:03 2009 action=add, path="/Applications/splunk/wsdl/iptocountry.wsdl", isdir=0, size=9599, gid=20, uid=503, modtime="Mon Mar 16 18:18:02 2009", mode="rw-r--r--", hash=
This, by itself, is an enormous uplift in troubleshooting applications as I describe the set up here. If you start indexing your logs from your own change control governance system, then you can start correlating all files that changed without an approval in the change control governance system and files that did not change, even after a change request was approved in the change control governance system.
Security
Using Splunk for security monitoring has been well documented for a number of years. At this point of the discussion, Splunk is either complementing infrastructure for zero day attacks, flexible ad-hoc search, forensics, and event correlation for any type of indexed data or it is the solution for security analysis. One of the advantages of Splunk in this use case is that it allows the user to customize to scenarios as needed to ingest new data sources and match previously unknown patterns without having to wait for a vendor to do this for them. Splunk also provides a suite of applications known as the Splunk Enterprise Security Suite (ESS) to make this happen for those who want to fully utilize Splunk as their security solution because all of your IT data is security-relevant.
For instance, a file may be altered that allows access to all users for a proprietary application. The change management monitoring approach in the previous section may catch the fact that this important file has changed and allow the user to repair access rights back to authorized users only. This is another example of consolidating to use the same tool for troubleshooting, file system change management, and security forensics.
Consolidation
I have mentioned a number of topics to make the case for consolidation with Splunk to either augment or replace other tools that that may be doing similar tasks, which may be performed in a way that is more natural and easier with Splunk. Rather than having five different technologies to perform these different tasks, a Splunk installation can be used to consolidate some or all of this usage, saving on maintenance, training, and other effort leading to better operational intelligence.
Related Articles

Splunk Lantern’s Silver: A Win for Customers

Career Resilience and Splunk: Insights from the 2023 Splunk Career Impact Survey
