Universal or Heavy, that is the question?
Tips & Tricks SplunkIntroduction
As a Professional Services Consultant, a discussion that I often encounter when on site with customers is whether to use a Universal Forwarder or a Heavy Forwarder.
Splunk provides two different binaries, the full version of Splunk and the Universal Forwarder. A full Splunk instance can be configured as a Heavy Forwarder. The Universal Forwarder is a cut down version of Splunk, with limited features and a much smaller footprint.
I am going to show in this blog why Splunk Professional Services recommend the use of Universal Forwarders in preference to Heavy Forwarders whenever possible to ensure a faster, more efficient Splunk Platform.
When should the Universal Forwarder be used and why?
The Universal Forwarder is ideal for collecting files from disk (e.g. a syslog server) or for use as an intermediate forwarder (aggregation layer) due to network or security requirements. Limit the use of intermediate forwarding unless absolutely necessary. Some data collection Add ons require a full instance of Splunk which requires a Heavy forwarder (e.g. DBconnect, Opsec LEA, etc..).
Previously Heavy Forwarders were used rather than Universal Forwarders to filter data before indexing. Thought to be the most efficient use of resources, this not only increased the complexity of the environment, it also increased the amount of network IO that the indexers had to handle. In some circumstances this also increased the CPU and memory usage, negating the intended efficiency gain. This increase in network traffic is due to the Heavy Forwarder sending parsed/cooked data over the network with all the index time fields, raw event and additional metadata, rather than just a raw event.
Do all parsing and filtering on the indexers when possible, to keep the network IO down, this will make the configuration simpler to manage through the use of Universal Forwarders making the Splunk administrator’s job easier.
The following table shows the results of sample tests, sending a dataset from a Heavy Forwarder to an indexer. This test was repeated with acknowledgement enabled and then repeated the tests again using a Universal Forwarder as the data source. The test file contained 367,463,625 events.
The key takeaways are:
- The amount of data sent over the network was approximately 6 times lower with the Universal Forwarder.
- The amount of data indexed per second was approximately 3 times higher when collected by a Universal Forwarder.
- The total data set was indexed approximately 6 times quicker when collected by the Universal Forwarder.
The use of intermediate forwarding/aggregation layer
The use of aggregation layers sitting between collection and indexing tiers should be the exception rather than the rule, as this can have unintended consequences when it comes to your data.
The use an intermediate forwarding tier is an artificial bottleneck, increasing the amount of time from event generation to availability for searching and can also be a cause of data imbalance on the indexing tier that will reduce search performance.
The use of an intermediate tier will cause the data will funnel data to a smaller subset of indexers at any one time, causing hot spots of data for a given time period. When it comes to searching, this could mean that only a one or two of your indexers contain the results for your search and your search would only leverages the power of a few, rather than the power of many/all. As shown in the diagram below.
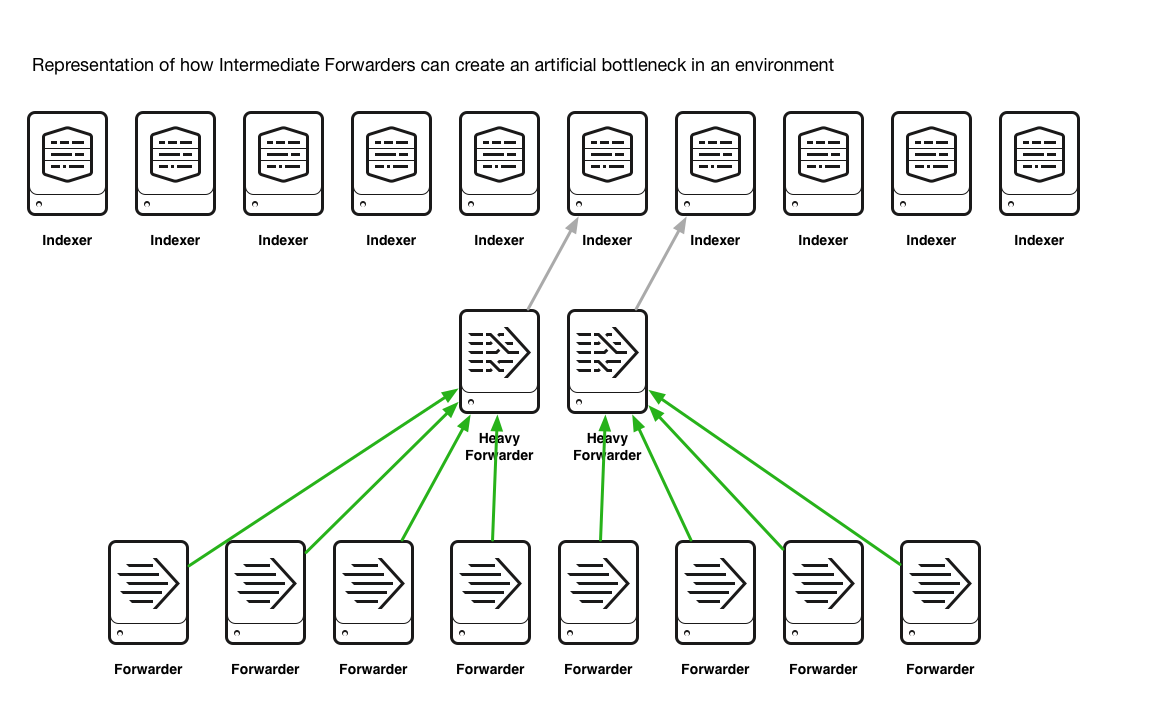
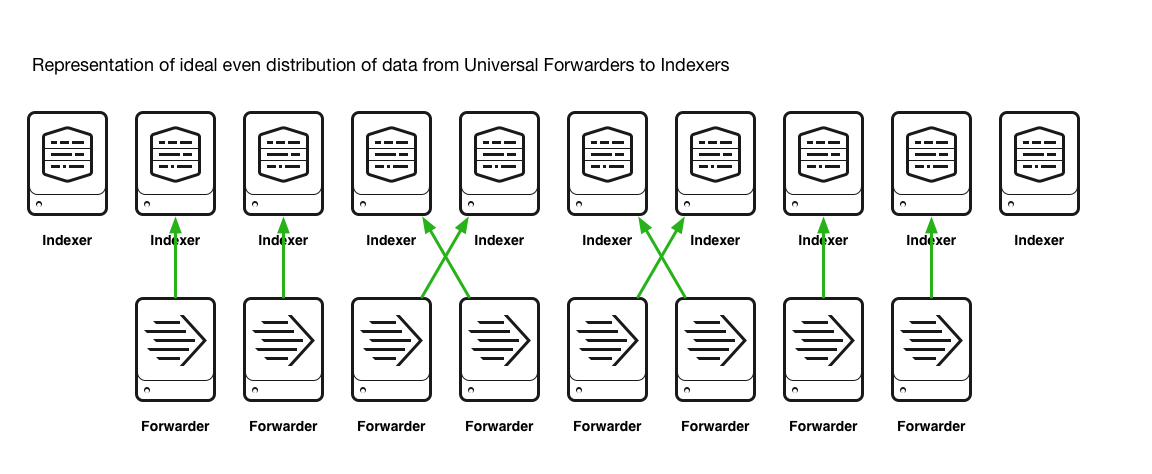
The distribution of data across your indexing tier will be lower when an intermediate tier of forwarders is used, ultimately causing a detrimental impact on search performance and user experience.
Common questions
Can I send from a Heavy Forwarder -> Universal Forwarder -> Indexer?
Yes. If you were collecting some data from a database on a remote site and had requirements that data goes through an aggregation layer before it left site, or upon arrival at a remote site.
We may need to filter data, so we should use a Heavy Forwarder, right?
A Universal Forwarder can filter windows events at source by Event ID.
A Universal Forwarder cannot filter based on regular expressions. Do this on the indexers, unless the majority of the data is being dropped at source. This is the most performant and easiest to manage at large scale.
We need to route the data to multiple locations
Simple routing and cloning of data can be performed with the Universal Forwarder, only when you need to route different events to different destinations does a heavy forwarder become necessary. As with filtering, do this at the indexers if at all possible.
Conclusions
The Universal Forwarder is great! It should always be chosen over and above the Heavy Forwarder unless you require functionality the Universal Forwarder cannot deliver.
Perform your data filtering on the indexer, data will be indexed quicker and network admins will be happier that Splunk isn’t using massive amounts of bandwidth.
By only parsing your data on the indexers, your configuration will be simpler.
People that know me know that I love the Acronym K.I.S.S. (https://en.wikipedia.org/wiki/KISS_principle). I always have this rattling in my head when I work on anything, the Universal Forwarder is an easy way to achieve that.
Recommendations
Only use the Heavy Forwarder when:
- Dropping a significant proportion of the data at source.
- Complex UI or addon requirements, e.g. DBconnect, Checkpoint, Cisco IPS.
- Complex (per-event) routing of the data to separate indexers or indexer clusters.
Thanks for reading,
Darren Dance
Senior Professional Services Consultant
----------------------------------------------------
Thanks!
Darren Dance