
ガートナー社 2025年 SIEM部門のマジック・クアドラント
Splunkが11回連続でリーダーに選出された理由をこちらからご確認ください。
プロフェッショナルサービスコンサルタントとしてお客様の現場へ出向いたときによく話題になるのが、ユニバーサルフォワーダーとヘビーフォワーダーのどちらを使うべきか、という問題です。
Splunkは、フルバージョンのSplunkとユニバーサルフォワーダーという、2種類のバイナリを提供しています。フルバージョンのSplunkインスタンスは、ヘビーフォワーダーとして構成できます。ユニバーサルフォワーダーはSplunkの簡易バージョンであり、機能が一部に制限されフットプリントははるかに小さいです。
このブログ記事では、Splunkプラットフォームの高速化および効率化という観点で、なぜSplunkプロフェッショナルサービスがヘビーフォワーダーよりもユニバーサルフォワーダーをおすすめするのかを説明します。
Splunk Universal Forwarderのダウンロードはこちら。
ユニバーサルフォワーダーが最適となるのは、syslogサーバーなどのディスクからファイルを収集する場合や、ネットワークやセキュリティの要件で中継フォワーダー(集計層)として使用する場合です。なお、中継フォワーダーを使用するのは、本当に必要な場合に限定しましょう。データ収集アドオンにはフルバージョンのSplunkインスタンスを必要とするものがあり、この場合はヘビーフォワーダーが必要です(DBconnect、Opsec LEAなど)。
以前は、インデックス化する前にデータをフィルタリングする目的で、ユニバーサルフォワーダーよりもヘビーフォワーダーが使用されていました。これは最もリソースを効率的に使用できる方法と考えられていましたが、実際には環境を複雑にするだけでなく、インデクサーが処理するネットワークIOも増加します。CPUやメモリーの使用率も上がり、意図していた効率化の効果が打ち消されることもありました。このようにネットワークトラフィックが増加するのは、ヘビーフォワーダーが解析や処理の済んだデータをネットワークに送信するからです。このデータには、Rawイベントだけでなく、インデックス時間のフィールドや他のメタデータもすべて含まれます。
可能であれば解析とフィルタリングはすべてインデクサーで行い、ネットワークIOを増やさないようにすべきです。そしてユニバーサルフォワーダーを使用すれば、単純で管理しやすい構成となり、Splunk管理者の業務が軽減されます。
下の表は、ヘビーフォワーダーからインデクサーにデータセットを送信したサンプルテストの結果です。テストは応答確認を有効にした状態でも行い、さらにユニバーサルフォワーダーをデータソースとして使用して同じテストを行いました。テストファイルには367,463,625件のイベントが格納されています。
| インデクサー応答確認 | ネットワーク送信量(GB) | ネットワーク平均速度(KBps) | インデックス化平均速度(KBps) | 所要時間(秒) | |
| ヘビー | あり | 39.1 | 1941 | 5092 | 21151 |
| なし | 38.4 | 1922 | 5139 | 20998 | |
| ユニバーサル | あり | 6.5 | 863 | 14344 | 7923 |
| なし | 6.4 | 1015 | 17466 | 6662 |
注目すべきは以下の点です。
通常は収集層とインデックス層の間で集計層を使用すべきでなく、あくまで例外です。実際のデータでは予期せぬ結果となる可能性があるからです。
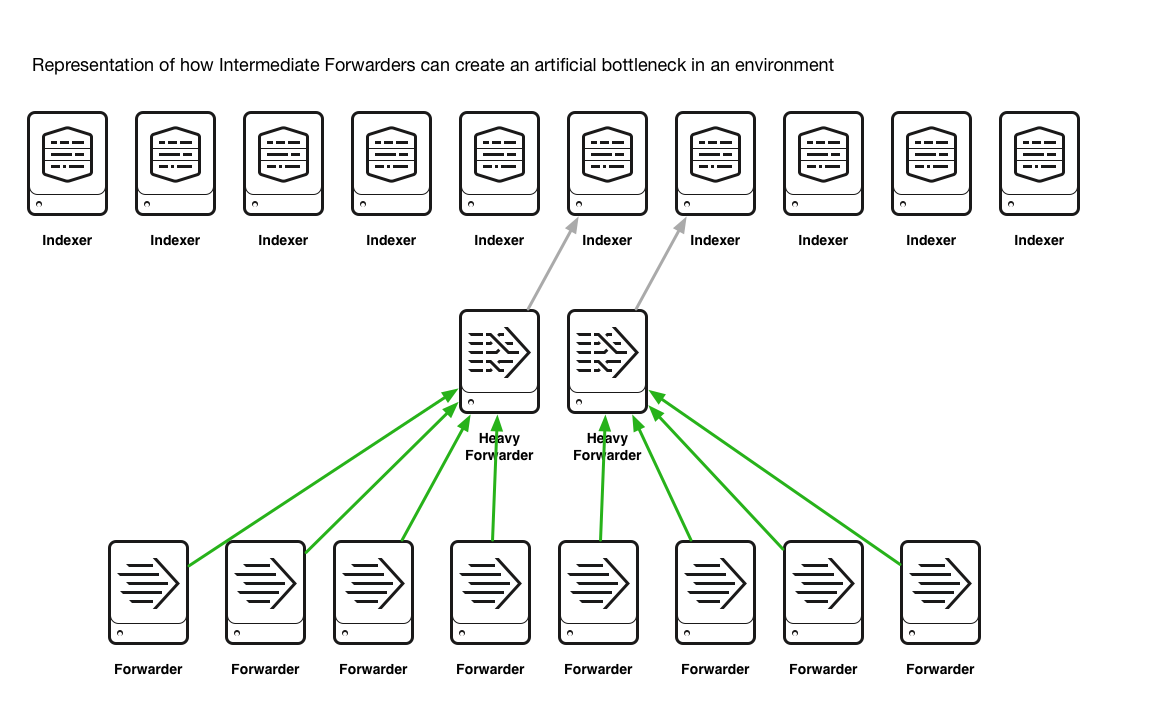
中継フォワード層を使用すると人為的にボトルネックを作ることになり、イベント生成からサーチできるようになるまでに必要な時間が増加するだけでなく、インデックス層のデータが不均衡になり、サーチパフォーマンスが低下する要因にもなります。
中間層を使用すると、一度に少数のインデクサーにしかデータが送られなくなり、データが集中して負荷が高くなる時間帯が生じます。サーチに関しては、サーチ結果を持つインデクサーが1~2台になる可能性もあり、そうなると多数もしくは全台を有効活用したいのにもかかわらず、わずかな台数の処理能力しか使えません。図で表すと以下のようになります。
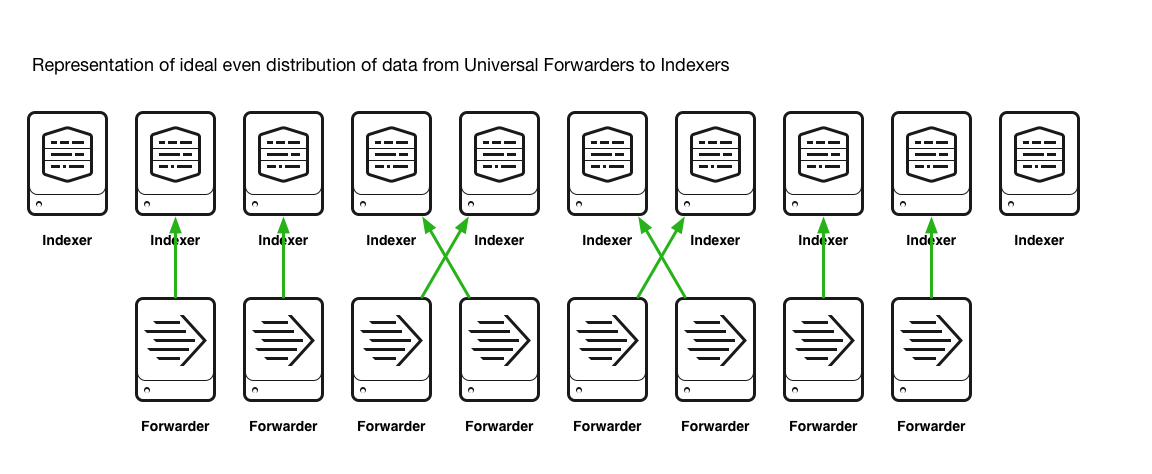
中間層を使用するとインデックス層全体へのデータ分散が行われにくくなり、その結果、サーチパフォーマンスやユーザーエクスペリエンスに悪影響が生じます。
はい。リモートサイトのデータベースからデータを収集しており、データがリモートサイトで送受信される際に集計層を経由することが要件の場合、そのような送信が可能です。
ユニバーサルフォワーダーでも、ソース側でイベントIDを使用してWindowsイベントをフィルタリングすることはできます。
ただし、ユニバーサルフォワーダーで正規表現によるフィルタリングはできません。ソース側で大部分のデータを破棄するのでなければ、インデクサーで正規表現を使用しましょう。規模が大きい場合、この方法が非常に優れたパフォーマンスを発揮し、管理も簡単です。
データの単純なルーティングとクローン作成ならば、ユニバーサルフォワーダーでも可能です。イベントごとにルーティング先を変える必要がある場合に限り、ヘビーフォワーダーが必要になります。フィルタリングは、できる限りインデクサーで行いましょう。
ユニバーサルフォワーダーはとても優れたソリューションです。ユニバーサルフォワーダーにない機能を必要としている場合を除いて、常にヘビーフォワーダーよりもユニバーサルフォワーダーを優先して選ぶべきです。
インデクサーでデータをフィルタリングすれば、インデックス化が高速になるだけでなく、Splunkがネットワークの帯域幅を大量に消費することもないので、ネットワーク管理者にも歓迎されるでしょう。
インデクサーでデータを解析するだけで、構成をシンプル化できます。
私は、自他共に認める「KISS」という略語の支持者です。仕事をするときはいつも、この言葉が頭にあります。ユニバーサルフォワーダーはKISSを簡単に実現できる手段です。
ヘビーフォワーダーを使用するのは、以下の場合に限定しましょう。
お読みいただき、ありがとうございました。
Splunk Universal Forwarderをダウンロードして、そのメリットを体感してください!
Darren Dance
シニアプロフェッショナルサービスコンサルタント
----------------------------------------------------
ありがとうございました!
Darren Dance

© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
© 2005 - 2026 Splunk LLC 無断複写・転載を禁じます。
