Effective IT monitoring is crucial for preventing downtime, enhancing system reliability, and ensuring a seamless user experience by proactively identifying and addressing issues.
Modern IT monitoring leverages automation, advanced analytics, and unified, real-time visibility — including dashboards, automated alerting, and end-user experience data — to shift from reactive firefighting to proactive issue prevention.
Monitoring enables organizations to define, track, and report on Service Level Indicators (SLIs) and Objectives (SLOs), aligning technical performance with business outcomes and customer expectations.
Whether on the cloud or on-premises, visibility into the inner workings of our IT services and infrastructure is an essential ingredient of a well working IT system.
The drive for digital transformation as a core strategic objective for most modern enterprises has meant that ensuring IT systems are working well, secured and delivering value for money is a critical endeavor. Monitoring IT status and performance is crucial for:
In The Uptime Institute’s Annual Outage Analysis, more than two-thirds (67%) of all outages cost organizations more than $100,000. The takeaway? The ability to quickly detect and address system anomalies is capability you need.
In this article, we will review what is monitored, the process of monitoring as well as future trends.
What is IT systems monitoring?
Put simply, the term “IT monitoring” refers to any processes and tools you use to determine if your organization’s IT equipment and digital services are working properly. Monitoring helps to detect and help resolve problems — all sorts of problems.
Today, monitoring is complicated. That’s because our systems and architecture are complicated — the IT systems we use are distributed. (Just like the people we work with are, too.)
Let’s look at a couple official definitions.
Google’s SRE book defines monitoring as the “collecting, processing, aggregating, and displaying real-time quantitative data about your system”. This data can include query counts and types, error counts and types, processing times, and server lifetimes.
In ITIL® 4, information about service health and performance falls under the “Monitoring and Event Management” practice. They define monitoring as a capability that enables organizations to:
Respond appropriately to past service-affecting events.
Take proactive action to prevent future adverse events.
Monitoring can have various “flavors”. Though this article is about IT systems monitoring writ large, we can also categorize some more specific subsets of monitoring, like:
(Splunk can help with all of this. We also offer vendor-specific monitoring: AWS, SAP, GCP and more.)
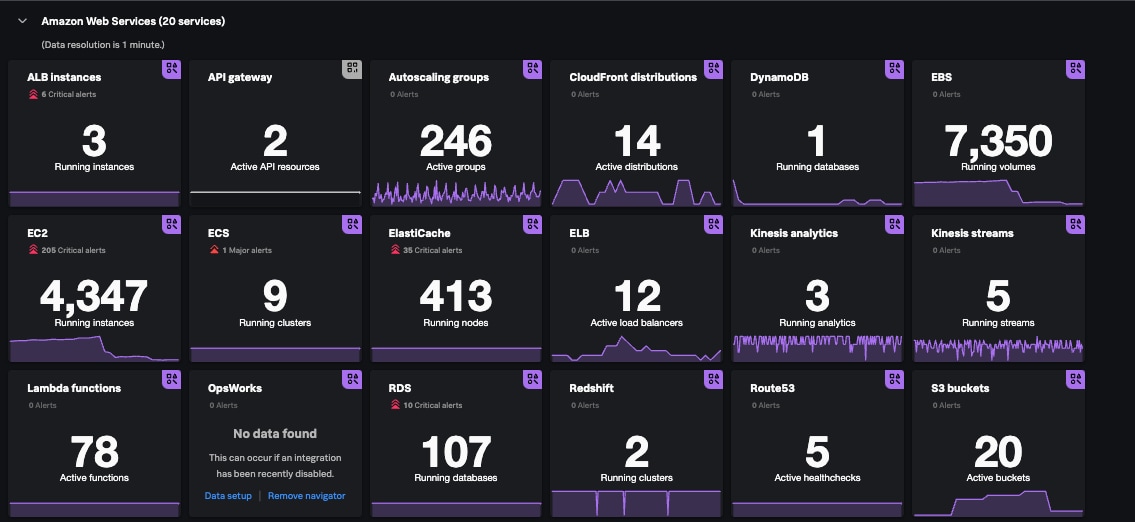
Example: Splunk Infrastructure Monitoring showing an AWS services dashboard
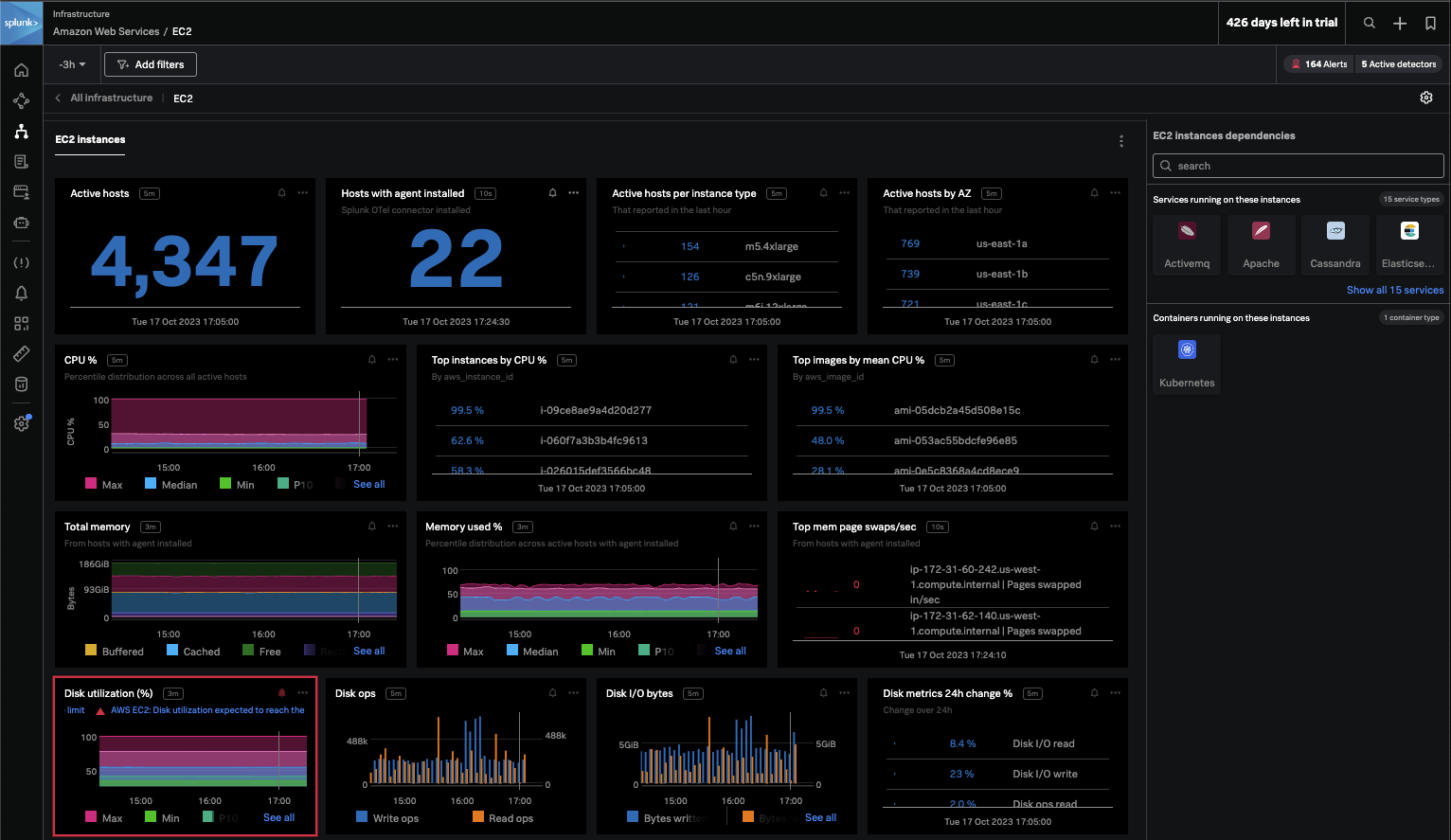
The EC2 dashboard displaying out-of-the-box metrics and indicating critical disk space issues
What to monitor in IT systems
IT systems monitoring is about answering two fundamental questions: what is happening, and why it is happening.
To answer these questions, you need to continuously monitor elements in the system for anomalies, issues, or alerts for maintenance activities, in order to ensure that the services operate and can be consumed as per agreed performance levels.
Metrics are the sources of raw measurement data that is collected, aggregated, and analyzed by monitoring systems. IT system metrics range across multiple layers, including:
Low-level infrastructure metrics: These are measured at the level of host, server, network and facilities, and include CPU, disk space, power and interface status among others.
Application metrics: These are measured at software level and include response time, error rate, and resource usage among others.
Service level metrics: These are infrastructure-, connectivity-, application-based and service action-based, where applicable.
Monitoring based on low level infrastructure metrics is known as “black-box monitoring”. This is generally the preserve of system administrators and DevOps engineers. At the application level, the term “white-box monitoring” applies, and is usually the work of developers and application support engineers.
IT system monitoring metrics are usually sourced from native monitoring features that are designed and built within the IT components being observed.
Beyond that, some IT monitoring systems deploy the use of custom-built instrumentation (such as lightweight software agents) which can extract more advanced service level metrics.
Four golden signals
According to Google there are four golden signals that should be the focus for IT systems monitoring:
Latency. The time it takes to service a request, i.e. the round-trip time usually in milliseconds. The higher the latency, the poorer the level of service being experienced — this is where users complain about slowness and lack of responsiveness.
Traffic. A measure of how much demand is being placed on your system, i.e. requests handled or the number of sessions within a period of time, taking up configured capacity. As the traffic increases, so does the stress on IT systems, and the potential to affect customer experience.
Errors. The rate of requests that fail, either explicitly, implicitly, or by policy. Errors point to configuration issues or failure by elements within the service model.
Saturation. A measure of the system fraction, emphasizing the resources that are most constrained, i.e. how "full" the service is. Exceeding the set utilization levels would likely lead to performance issues.
Best practices for alert fatigue
As system administrators set up monitoring systems to capture more data, they run the risk of being overwhelmed by:
The quantity of alerts being paged.
The complexity of relating alerts and logs.
It is a good practice to set up simple, predictable, and reliable rules that catch real issues more often than not.
In addition, regular review of thresholds settings (informational vs. warning vs. exceptional) as well as effective configuration of automated correlation engines such as those enabled by AIOps can help prevent over-alerting.
Now, with the context set, let’s have a look at the six main activities in IT systems monitoring:
Phase 1. Planning
When selecting an IT system to monitor, you’ll need to do several planning activities, including: defining its priority, choosing features to monitor, establishing metrics and thresholds for event classification, defining a service 'health model' (end-to-end events), defining events correlations and rule sets, and mapping events with the action plans and teams responsible.
This is the first stage of event handling. Here, the IT systems alerts are detected when the set thresholds and criteria are passed. Alerts are captured by an IT monitoring system where they can be displayed, aggregated and analyzed.
Phase 3. Filtering and Correlation
Based on the rules set, the monitoring system filters and correlates the received alert. Filtering can be based on criteria such as:
Source
Time generated
Level
Correlation checks patterns among other alerts to determine anomaly sources and potential impacts.
Phase 4. Classification
In this phase, the event is grouped according to set criteria (such as type and priority) in order to inform the right response. For example, alerts related to intrusion or ransomware would be classified as security events — and this informs a SOC team to act on them.
Phase 5. Response
Based on the action plan and responsibility matrix you previously defined, the relevant team is paged via email, text, online collaboration systems or other agreed channels.
For some IT environments, the event response can be automated, meaning that action is taken independent of human intervention such as rebooting of instances or failover of traffic.
Phase 6. Review
Based on the handling of events and the resultant effect on the quality of IT systems, there should be a regular review of the monitoring planning to ensure that the metrics and thresholds set still meet your requirements. This review should also:
Update response procedures and responsibility matrices.
Check performance of metrics associated with the event management process such as quality of data and failed detections leading to service outages.
Future trends of IT Systems Monitoring
As IT systems grow in complexity, organizations will require to invest in IT systems monitoring tools that provide the capability required to keep up with the technology evolution and the volume of changes made.
A survey from 451 Research had 39% of respondents having invested in between 11 and 30 monitoring tools for their application, infrastructure, and cloud environments—wow! This tool sprawl quickly results in:
Inefficiencies
Wasted money
Missed opportunities
Tools that can span the entire technology landscape and consolidate events across myriad systems and environments will inevitably be more attractive for organizations looking for value for money.
When working with clients over the last years, along with annual research, two primary trends emerge.
Impact of ML and AI
The impact of AI/ML on IT systems monitoring will continue to grow especially given the rising capability of large language models (LLMs). Modern tools that have integrated AI can now handle the entire process lifecycle from detection to response, especially for large event data volumes analysis, as well as handling of tedious activities such as event correlation and log analysis across distributed systems.
With appropriate training, these tools are perfectly suited to sort through alert “noise” and “false positives/negatives” faster and more effectively than any human team. However, this does not mean the total elimination of people from IT systems monitoring — instead, their focus will shift to building better orchestration and automation tools to respond to alerts and resolve them.
Unified observability
The other trend that impacts IT systems monitoring is the advent of unified observability. The rise of platforms that provide a single view — across infrastructure, applications, and user experience — by analyzing logs, metrics and traces means there’s a valuable magnifying glass available to you: more thorough analysis of alerts to pinpoint the exact issues that users are facing across complex environments.
For businesses of all sizes, IT systems monitoring is a critical way for guaranteeing the functionality, performance, and security of their IT services. The field of IT systems monitoring will continue to evolve to meet new challenges and offer more benefits as long as technology continues to grow.
The significance of continual improvement cannot be overstated. Organizations will only guarantee that their services provide value by embracing a proactive, data-driven approach to IT systems monitoring.
Say goodbye to blind spots, guesswork, and swivel-chair monitoring. With Splunk Observability Cloud and AI Assistant, correlate all your metrics, logs, and traces automatically and in one place.
Joseph is an ICT consultant and trainer with over 18 years of global experience across multiple sectors. His passion is assisting business units and IT departments in executing their digital transformation strategies and streamlining their operations in line with global standards and best practices. His areas of expertise include business process reengineering, IT service management, project management and cyber resilience. You can connect with Joseph @josephnduhio and on LinkedIn.
Endpoint monitoring is crucial in 2023, providing real-time visibility into the security posture of all your devices — and your employees’ devices.
About Splunk
The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.