Splunk and Multitenancy
Tips & Tricks SplunkDoes Splunk support multitenancy?
We are asked this question quite often, especially when speaking with Managed Service Providers (MSPs).
Multitenancy refers to a principle in software architecture where a single instance of the software runs on a server, serving multiple client organizations (tenants).
By this definition, the answer is Yes.
Why would anyone want to do this? As an MSP, you may want to provide your customers with some specific functionality that Splunk provides, such as syslog, custom application, or other big data reporting.
You’d also like to do this without having to deploy a unique Splunk instance for each customer. Wouldn’t it be great to allow multiple customer accounts, each with multiple users, to access a shared Splunk instance?
This can be accomplished with Splunk today. Of course, there’s not a one-size fits all approach to how this would be precisely architected, but the basics of the approach boil down to the following:
– Unique indexes per customer
– Role-based permissions
– Granular user access control
Step One: Unique Indexes Per Customer
First things first, ensure your each of your customers store their data in unique, non-shared indexes. This is absolutely critical. For example, Customer_A may be collecting syslog and access logs from their servers and applications. A best practice might be to create two separate indexes, named “customer_a_syslog” and “customer_a_access”, respectively.
Even further, storing these indexes on private and secure partitions is also a best practice, but again, this is best defined by your specific technical requirements.
Step Two: Specify Unique Indexes in Data Inputs
Next, create two new unique Splunk inputs, each storing its data in its respective index. [Splunk -> Manager -> Data Inputs]. Make sure they are not storing data to an existing, shared index (such as main). The destination index for each new input should be unique, and created in the previous step.
Take note of the specified sourcetype. If they are unique it helps even further with data segregation.
Step Three: Access Controls – Roles
Next is Access Controls [Splunk -> Manager -> Access Controls]. Let’s start with Roles first. Create a new Role for each Customer account. For example, create a new role called “customer_a”.
Remember how I mentioned to note the sourcetype specified earlier? You’ll notice there’s a section for Restricting Search Terms. This is an additional method to ensure that these customers can ONLY search across a specific type of data – for example, ONLY access logs. In this case, you’d type sourcetype=access_combined in the Restrict Search Terms box.
Now, there are many other options that determine what this Role can do in Splunk, using Inheritance and Capabilities. The selections you make here will largely be a result of your specific technical requirements.
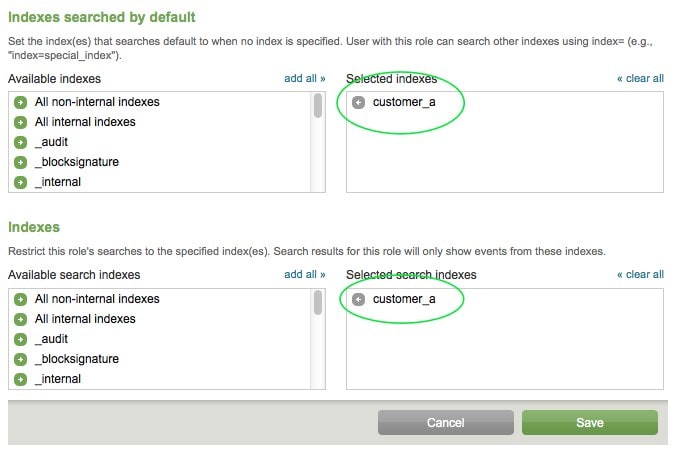
Next, let’s specify the indexes searched by default, as well as what indexes in general this Role can search.
This is where we specify the Index we created earlier. Doing this restricts this Role from searching any other index (other customers’ data). This is what multitenancy is all about. You don’t want one customer seeing another customer’s data!
Step Four: Access Controls – Users
Let’s create some users. [Splunk -> Manager -> Access Controls -> Users].
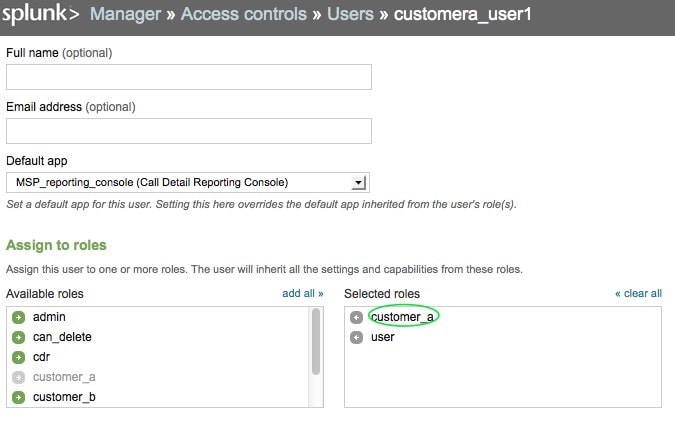
Create a new User, making sure to assign this User to a previously created Role. For example, I might create a new user “customera_user1”.
You can optionally specify a Default app – this will be helpful if you’ve built a customer-centric view that would be a landing page when customera_user1 logs in.
Next, let’s assign this user to the previously created Role – “customer_a”.
Now that we’ve got the basics out of the way, you can continue to architect your Splunk solution according to your specific requirements.
A properly set of configured inputs, indexes, users, roles, and apps can be combined for a truly rich user experience. To see an example of what’s possible, keep reading!
Real World Example
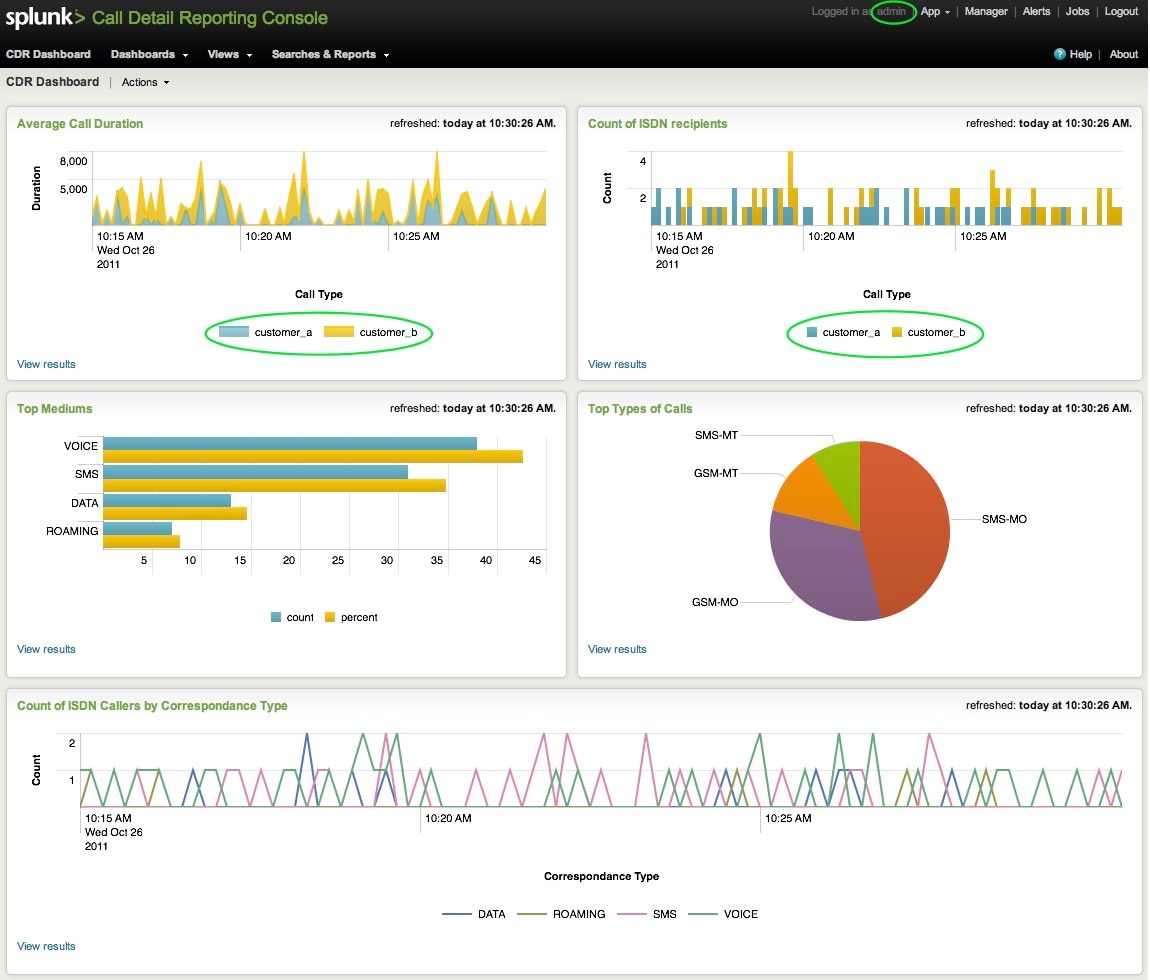
Suppose for a minute I’m the Splunk Administrator at a Managed Service Provider (MSP) in the telecommunications industry. Ideally I’d like a dashboard view displaying certain things: average call durations, ISDN recipients, top mediums, types of calls, etc. Not only do I want to see the data for one specific customer, I’d like to see data across all of my customers.
As a Splunk Administrator, I would have access to all my customer data (if so desired). Each of my customers would be sending data to unique index destinations.
The following dashboard reflects that. Notice I can see data for both customer_a and customer_b.
For the cross-customer Average Call Duration view below, the actual search powering it is:
sourcetype="CDR" | timechart avg(call_duration) by index
This allows me to search across any and all Indexes. A Splunk Administrator can do this. Remember that we configured our customers to only have access to one index, therefore disallowing that type of search.
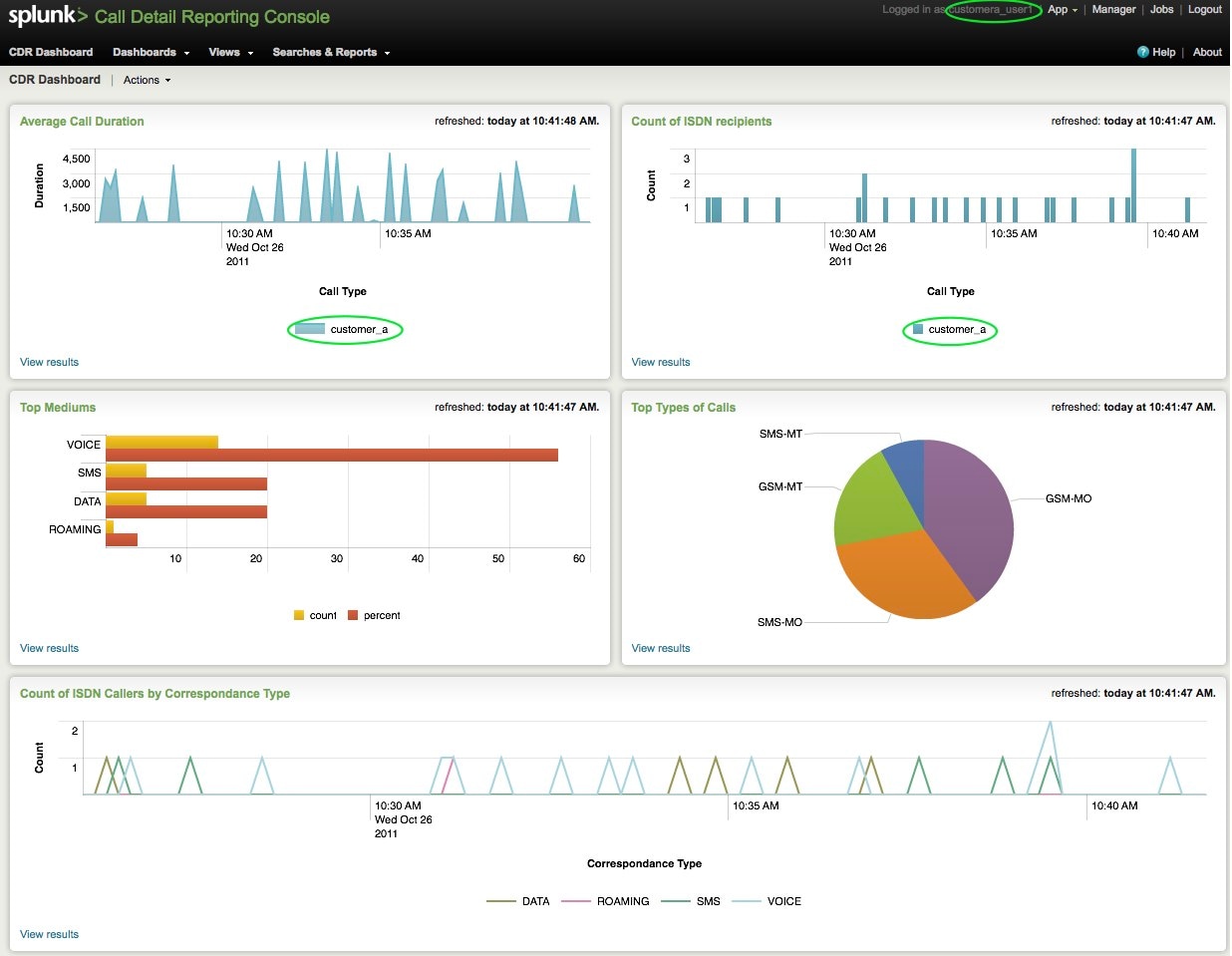
Want proof? See the following screenshots for customer_a and customer_b’s logins:
Customer_a:
Customer_b:
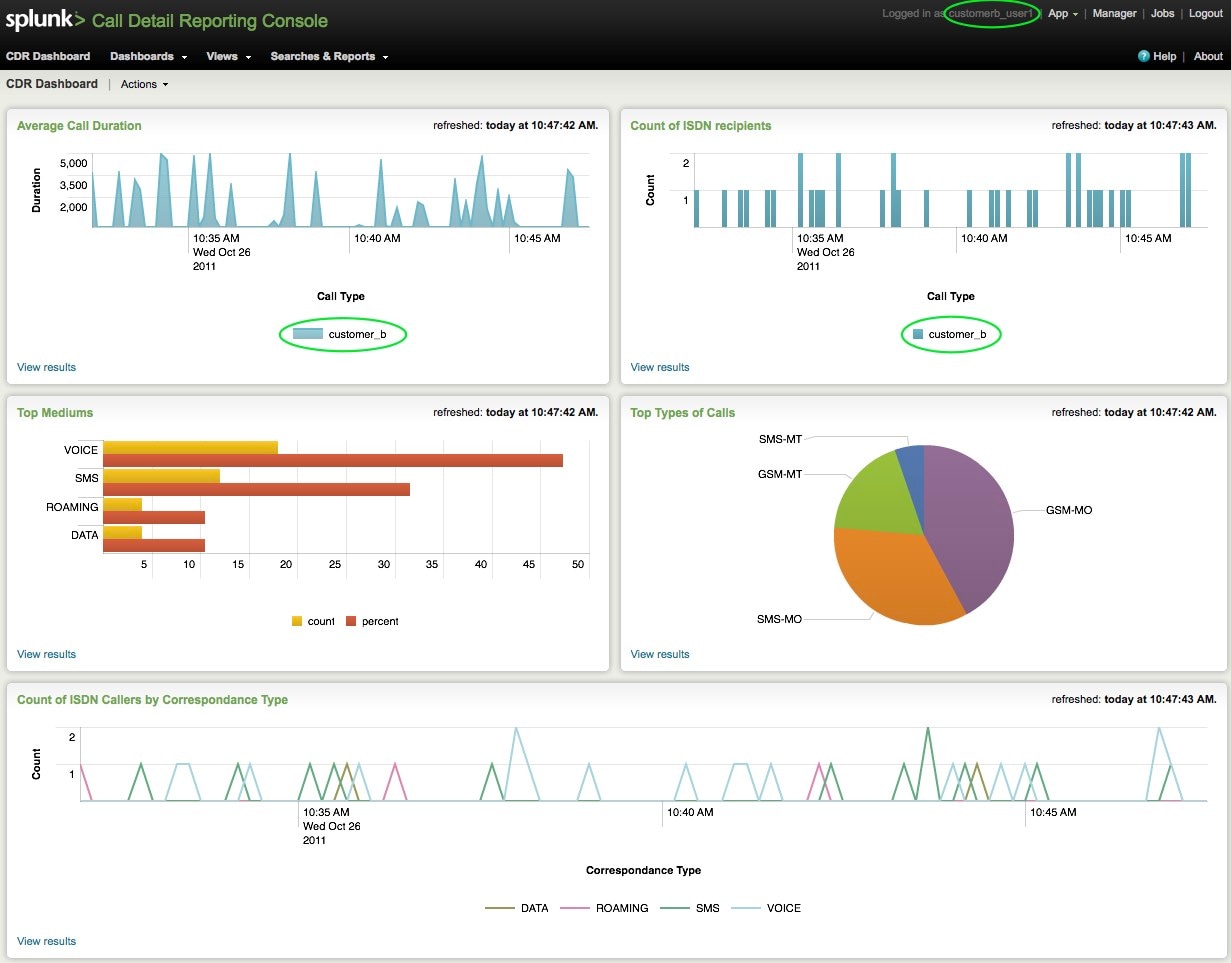
Even further, notice the appearance of the Search app for customer_b.
Customer_b’s users only get to view and report on data in their index:
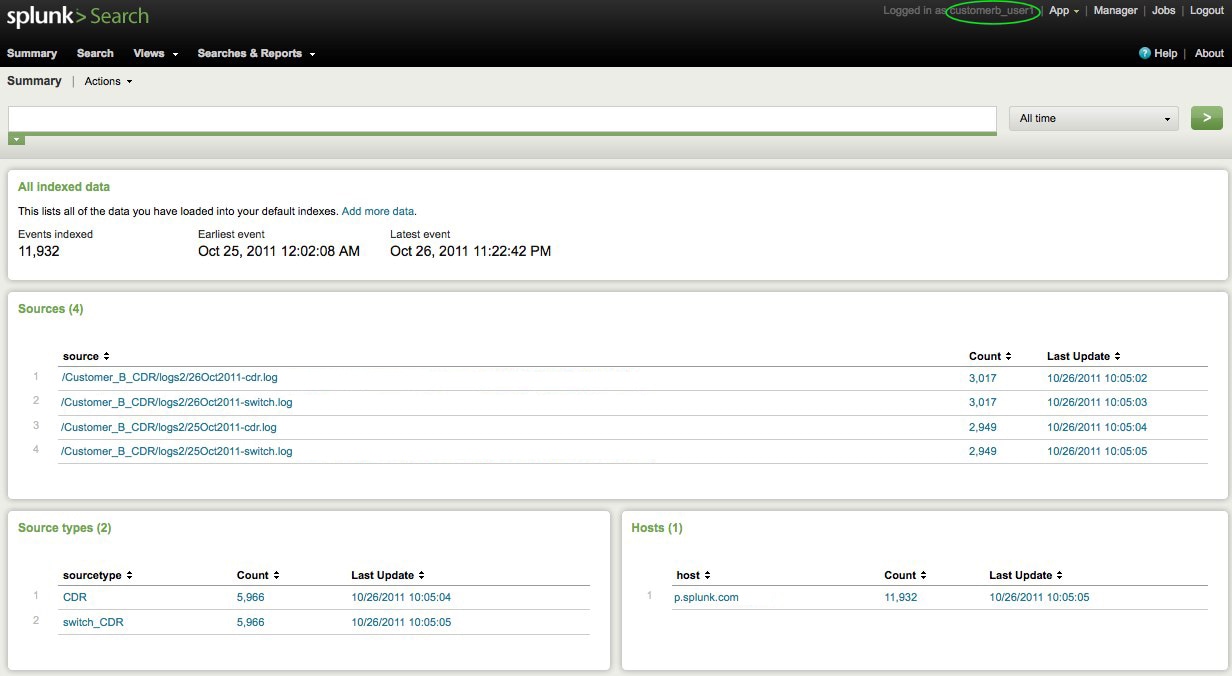
Questions? Comments? We’d love to hear what you’ve accomplished!