Splunk Command> Cluster
Tips & Tricks SplunkBeing a Splunk sales engineer is incredible. I get to talk to customers about their use cases, ‘Splunk’ their data, and together discover the insight Splunk provides them. Initial demos typically start with the search bar, looking for keywords in their data. Usually doesn’t take long before the “Ah Hah!” moment comes – either by using Splunk’s intuitive GUI to interact with extracted fields of interest or employing a very small subset of the 130+ search commands with in the search bar to gain operation intelligence not readily seen before. At a recent customer visit I employed the Splunk on Splunk (S.o.S.) App, explored some of the underlying searches and noticed the cluster command, which I never used before. So I dug a little deeper into some Nagios data with the cluster command.
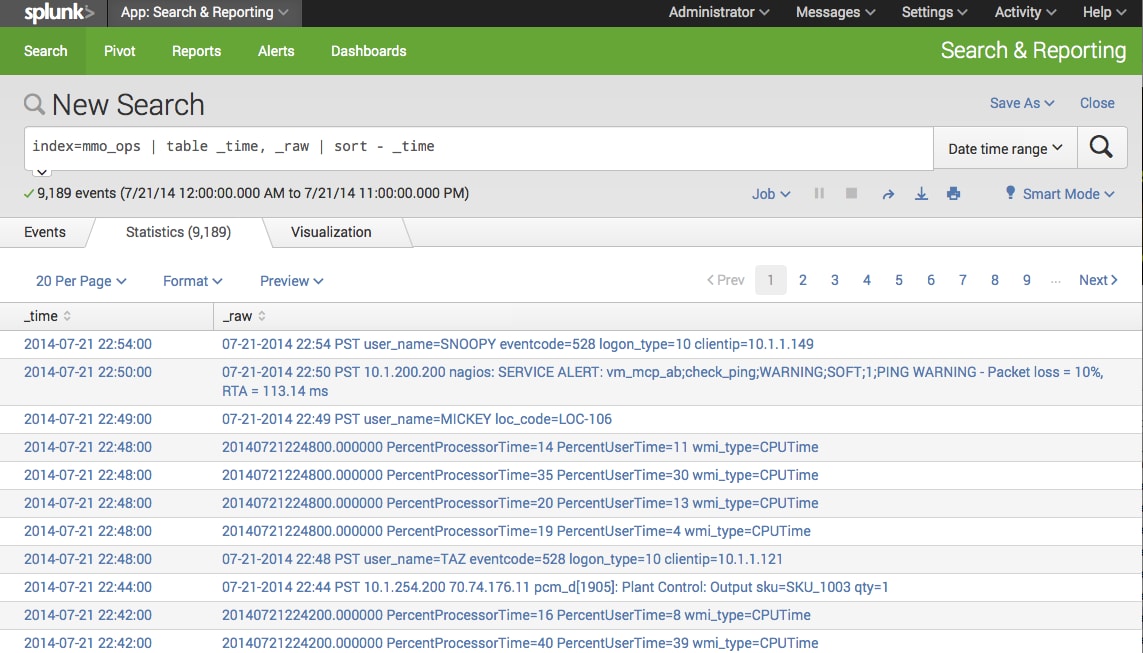
Nagios is an industrial monitoring tool that monitors your entire IT infrastructure. Capturing these events with Splunk allows you to perform historical diagnostics of problems that occurred within your environment. The cluster command is used to find common and/or rare events within your data. A quick search, organizing in a table with a descending sort by time shows 9189 events for a given day.
index=mmo_ops | table _time, _raw | sort - _time
Adding the cluster command groups events together based on how similar they are to each other. Two new fields, cluster_count and cluster_label, get appended to each new event created by cluster. [An option of showcount=t must be added for cluster_count to be shown in results.] The cluster_count represents the number of original _raw events grouped together, cluster_label is a unique label given to each new event. So after cluster I create a table then sort by cluster_count.
index=mmo_ops| cluster showcount=t | table _time, cluster_count, cluster_label, _raw | sort cluster_count
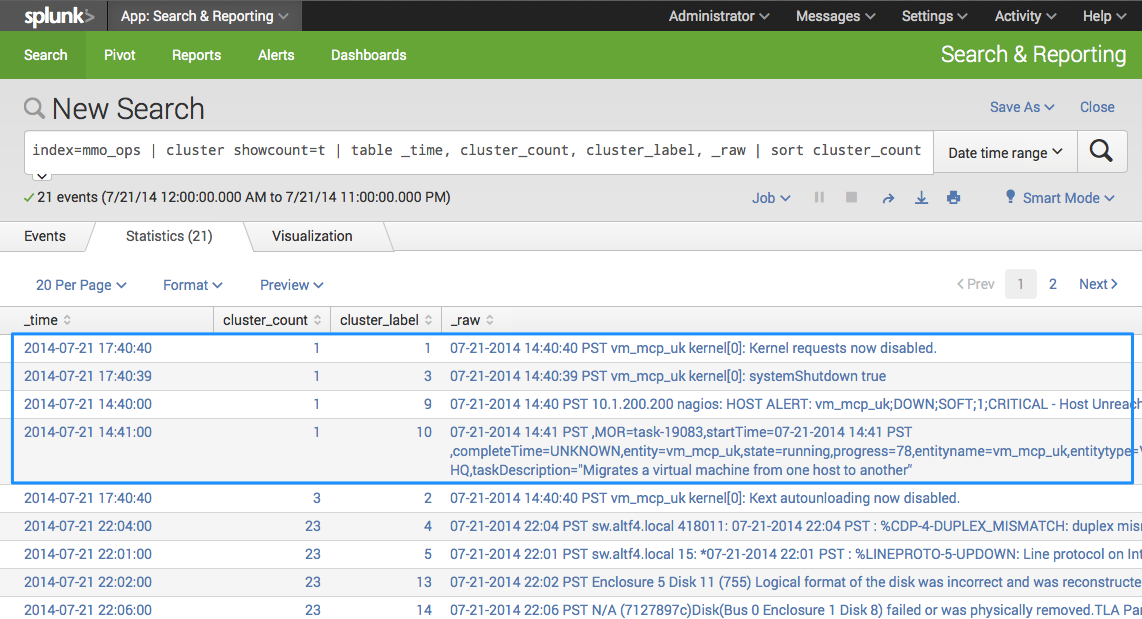
Immediately you see cluster isolates four rare, notable events – one in which a critical system shutdown occurred. Pretty cool, right? No heavy lifting. No prior knowledge of what we might want too look for. The cluster command simply did it for us!
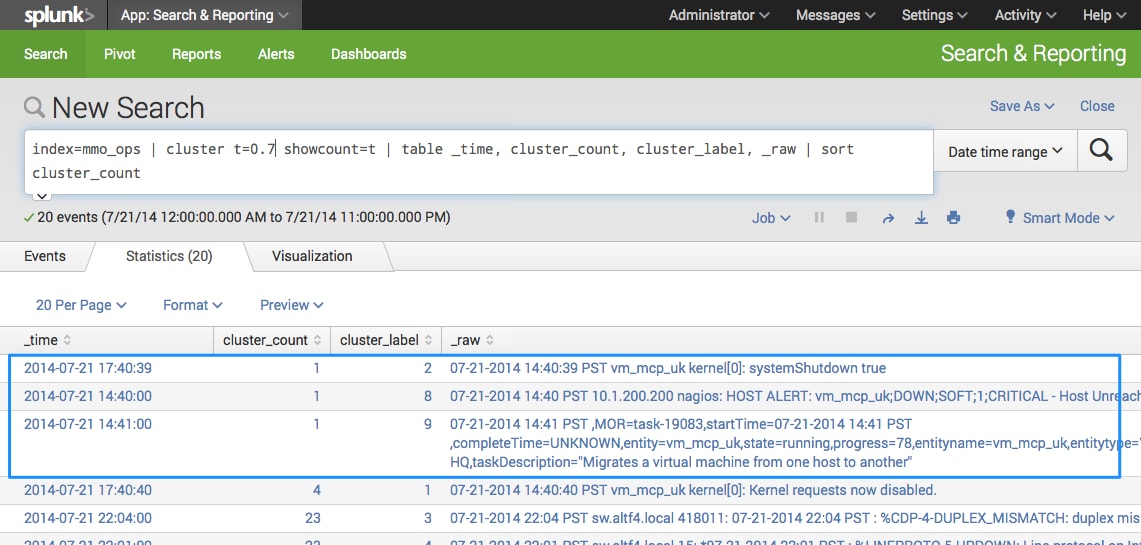
The main option for this command, t, sets a threshold that controls the “sensitivity” of the clustering, values ranging from 0 to 1.0. The closer t is to 1.0 the more similar events are that get clustered together (increased resolution). By default t=0.8 (used for previous search), therefore decreasing t should “zoom out” and decrease the number of clustered events. With my data value of t=0.7 produced fewer clustered events, three unique values with a cluster_count of one, and still showing the system shutdown.
index=mmo_ops| cluster showcount=t t=0.7 | table _time, cluster_count, cluster_label, _raw | sort cluster_count
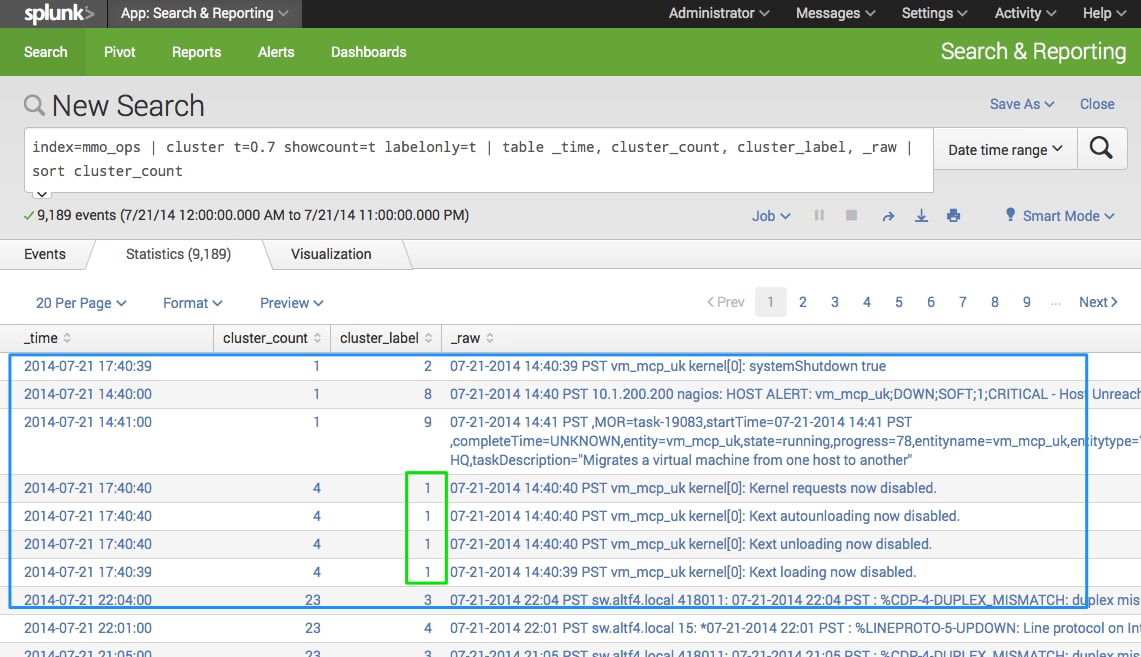
Still want to see the original events but know which clustered event they belong to? No problem! Use the labelonly=t with cluster.
index=mmo_ops| cluster showcount=t t=0.7 labelonly=t | table _time, cluster_count, cluster_label, _raw | sort cluster_count
Extending this search string one more time with dedup (de-duplication) command allows me to see the most recent grouped events within a clustered event. The search below is limited to the last five events within each clustered event.
index=mmo_ops| cluster showcount=t t=0.7 labelonly=t | table _time, cluster_count, cluster_label, _raw | dedup 5 cluster_label | sort cluster_count, cluster_label, - _time
Awesome stuff, huh? Can’t wait to “plunge” into other commands – way too cool! Till then the Force be with you, fellow padawan’s.
*I highly encourage you to download Splunk Enterprise for FREE and try it out! Nagios is free but you can “Splunk” any data.
----------------------------------------------------
Thanks!
Joe Welsh