
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.
In today’s turbulent times, companies big and small are being pushed to do more with less. Budgets are getting tighter and companies are being pressured to serve customers who demand 24/7 availability from their applications and services.
To meet these demands and remain competitive, enterprises are adopting cloud-first strategies and developing applications with microservice architectures. Meanwhile, DevOps and Site Reliability Engineers (SRE), the unsung heroes of the digital world, are ensuring applications run smoothly and users can go about their business uninterrupted.
As fault tolerant as every system strives to be, mistakes happen and errors occur. Our DevOps and SREs are crucial to saving the day when this happens but are often bombarded with scattered alerts across multiple systems. On top of that they must go through the mundane tasks of firing up communication channels, opening tickets and making sense of what just happened.
So, how can DevOps and SREs reduce this toil, stop jumping from tool to tool, and ultimately troubleshoot and resolve incidents faster to maintain service resiliency? Watch the video below.

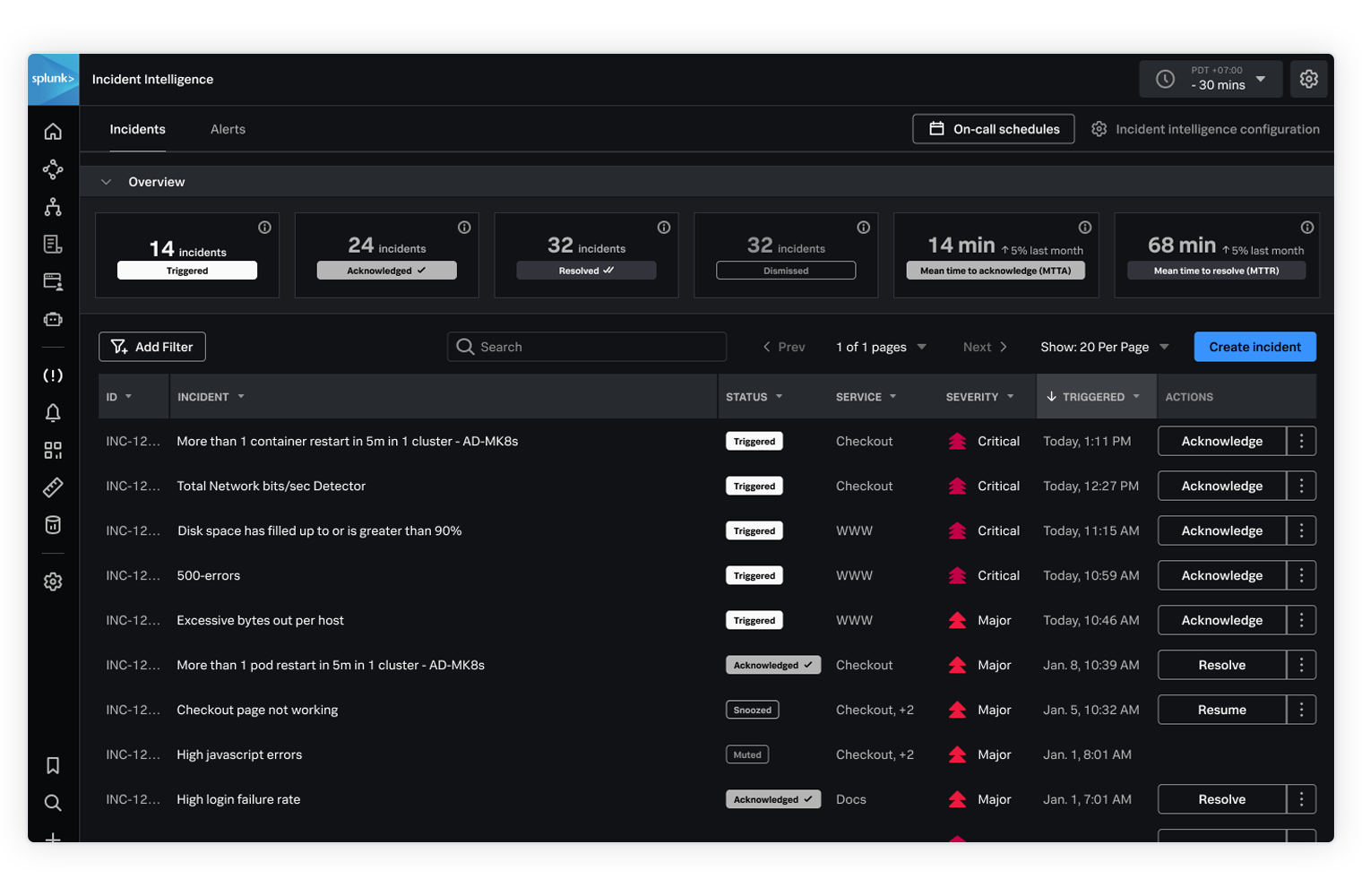
Splunk Incident Intelligence is a team-based incident response solution that connects the right on-call staff to the actionable data they need to diagnose, remediate and restore services quickly. Integrated with the Splunk Observability Cloud portfolio of products, it helps you unify incident response, streamline your on-call and ultimately resolve incidents faster.
A single integrated solution for on-call management, incident response and troubleshooting, Splunk Incident Intelligence helps you unlock the value of the data available in Splunk Observability Cloud. All while seamlessly integrating with third-party collaboration and incident management tools that may be part of your existing business process workflow.
We can help teams reduce swivel chair management across platforms and tools, saving time when it matters the most. There are a plethora of tools available in the market today in various domains such as infrastructure monitoring, application performance monitoring, event management, on-call and incident response. Jumping across multiple platforms and flipping between observability, on-call, collaboration and incident management tools has proven to be error-prone and time-consuming. Given the growing importance of business service uptime and outage mitigation, every second matters, which is why having an integrated on-call solution is so important.
By streamlining the incident response process, DevOps and SREs can quickly identify and diagnose issues. This means they can spend more of their time finding the root cause of the problem and less time filing tickets. Providing insightful tools to dig into the data at its most raw level while visualizing metrics across the broader ecosystem empowers these folks to reduce the time it takes to get systems back up and running.
Splunk Observability Cloud gathers millions of data points from various sources within the IT estate, applications and services at different levels and vantage points in the form of metrics, events, logs, and traces. With the introduction of Splunk Incident Intelligence, we are offering a single integrated solution for observability, on-call management, incident response and troubleshooting, unlocking the value of the data available in Splunk Observability Cloud while seamlessly integrating with third-party collaboration and incident management tools that may be part of your existing business process workflow.
Want to start troubleshooting faster? Splunk Incident Intelligence is part of the Splunk Observability Cloud. Curious to really dig in? Check out Splunk Incident Intelligence Technical Documentation.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.