
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.
Data can reside anywhere and Splunk recognizes that fact by providing the concept of forwarders. The Splunk Forwarder will collect data locally and send it to a central Splunk indexer which may reside in a remote location. One of the great advantages of this approach is that forwarders maintain an internal index for where they left off when sending data. If for some reason the Splunk Indexer has to be taken offline, the forwarder can resume its task after the indexer is brought back up. Another advantage to forwarders is that they can load balance delivery to multiple indexers. Even a Splunk Light Forwarder (a forwarder that consumes minimal CPU resources and network bandwidth) can participate in an auto load balance scenario to deliver to multiple indexers to distribute data for consumption. However, there are times when it is not possible to install a Splunk Forwarder on a machine because of technical or administrative reasons. What can be done then?
A Splunk user would point out that Splunk can use WMI in a Windows environment to pull Windows performance data and Windows events from multiple Windows servers. This is great for those situations as no forwarder is required. On the other hand, if what is being sent is not from Windows or is not in the form of WMI capable events such as IIS logs, J2EE logs, .NET logs, etc., then the WMI approach would not work. The experienced Splunk user would then point out that Splunk can also listen to network ports and execute custom scripts to index data. With that in mind, what I outline in the rest of of this blog entry are three different approaches for getting remote data indexed into a Splunk server without using forwarders or using WMI. The list is not exhaustive. As usual, I do provide reference implementations to supporting application add-on’s for each approach.
HTTP
Some products deliver business events or log events via the HTTP protocol using an HTTP Post or HTTP Get. Someone could configure Splunk to call a scripted input which is an HTTP receiver and the standard output of that HTTP receiver would be indexed into Splunk. Creating your own HTTP server may not be the wisest choice as there are multiple solutions out there to do so. Also, if the HTTP receiver is started with Splunk, if the indexer for some reason is brought down, all events that are sent to it afterwords would be lost.
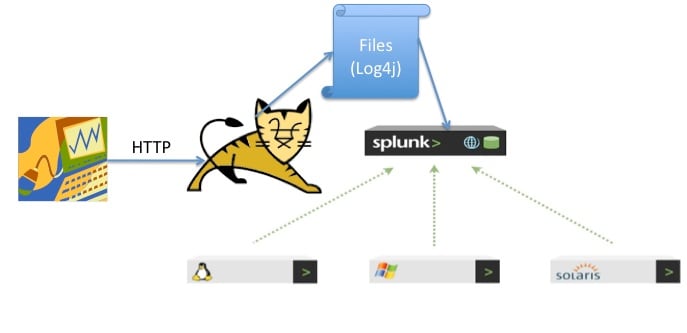
The approach I’ve implemented is to first create a simple Java Servlet, deployed into a Servlet container such as Apache Tomcat, that receives either HTTP POST or HTTP GET requests. The Servlet can then be configured to either write to the standard logging framework for Apache Tomcat or use Log4j to log each event to a rotating file. Splunk can either index the data directly from the file system or a forwarder can be installed on this machine to send the data to a remote indexer. This is pictorially depicted below. The green arrows are the traditional Splunk Forwarders. The cat, of course, is Apache Tomcat.
HTTP to Splunk
Use Case 1: Certain appliances or applications such as IBM Datapower can be configured to send data using HTTP POST or HTTP GET on a periodic basis. In our setup, the Servlet would receive the data and log it to a rotating file. Splunk would then index this data from this rotating file.
Use Case 2: A web server is located in a place where Splunk Forwarders can not be installed. For a web application, every time a business exception happens, such as a credit card is rejected, the web application could send a HTTP POST to the Apache Tomcat Servlet for Splunk to index the data. Splunk’s reporting engine can then provide reports for a dashboard on business activity.
You can download the HTTP POST or GET Capture Splunk add-on to try it out. Although I used Apache Tomcat to house my Servlet, you could use any Servlet container for this approach.
JMS
Java Messaging Service is a decade old technology used by J2EE application servers to produce and consume messages. Splunk can be configured to run a JMS consumer on start up. For every JMS message it receives, the consumer would send the message to standard output for Splunk to index. This is useful for situations where business events are coming from a platform that Splunk does not support. Events would be be sent to a JMS queue or topic via a JMS producer and the JMS consumer could quite elegantly participate in the indexing of data as it dequeues messages. Another advantage of JMS is that it can be made transactional with a persistent backing store so that messages that are in flight to the JMS destination have delivery guarantees once they are queued. In this manner, if the Splunk indexer with its JMS consumer is taken off line, the messages will still be available for consumption when the JMS consumer is made available again. Here is a diagram describing this approach.

Splunk as a JMS Consumer
Use Case 1: An application server such as IBM Websphere or Oracle WebLogic is running on a Mainframe and it produces messages or events to a JMS destination. Since Splunk Forwarders currently do not run on Mainframes, the application can use a JMS producer to send an event to a Queue. The JMS Consumer running remotely on the same machine as Splunk, started as scripted input, can now consume messages from this queue and send them to Splunk via standard output.
Use Case 2: An E-commerce application tracks each time a user removes an item from a shopping cart. This event is sent to an Enterprise Service Bus (ESB), which among other things, forwards the message to a JMS Queue. The JMS Consumer running with Splunk could then be used to index this data. The data could have customer demographics and statistics about the item removed from the shopping cart. Business decision makers can then use Splunk’s reporting and analytic capabilities to take further actions for what they are selling.
You can download a reference implemenation that uses WebLogic’s Example server to send messages to a JMS queue used to index data from Splunk’s add-on site. Although I used WebLogic 10.3 to implement this approach, the code could be modified to run with any JMS container.
TCP or UDP
Splunk can listen on any TCP or UDP network port for incoming traffic and index events from that port. This is a common way to index data from devices or applications that broadcast events to network ports such as using UDP 514 for Syslog data. Remember, if you are using ports below 1024, Splunk must have root or Administrator access to listen on these ports. Generally, in listening to network ports, there is no external persistence of data before it gets indexed. If the Splunk indexer is brought down for some reason, all subsequent data that is being broadcast to the network port will not be delivered. If you are using UDP instead of TCP, your chances for reliability decrease even more as this is a connectionless protocol. Having said that, this is the easiest approach to set up to deliver files from a place where Splunk Forwarders can not be installed. Simply write a TCP or UDP client in any language that the OS can handle, and schedule that program to periodically deliver your remote files to Splunk. The astute reader may say that a FTP scheduler can do similar things. Nevertheless, using your own TCP or UDP client can allow you to enrich the data or filter it before it is delivered as you have access to each event in the file as it is being read. You can also place delays in the delivery code to free computational resources. The approach is diagrammed below.

TCP or UDP to Splunk
Use Case 1: A mainframe produces a file every few minutes that needs to be delivered to Splunk for indexing. Not all contents of the file are necessary (such as DEBUG statements) so a TCP client can be scheduled to read each file as it is produced, filter out the unnecessary information, and deliver it to Splunk listening to a network port.
Use Case 2: A set of mini computers from an era by gone are used to store airline reservations. Each reservation also produces a file of the 10,000 most recent customers with their business data. The TCP client could read events from each produced file and send the data over to Splunk for analysis. Splunk’s ad-hoc reporting could easily produces statistics, charts, and tables to provide situational awareness for data that used to be locked away in remote servers.
Again, you can download the TCP or UDP Sending add-on from the Splunk Application add-on site. Although I created the TCP and UDP client programs in Python for ease of editing, you could easily write them in any language that supports TCP and UDP.
Conclusion
I have created a simple table to outline whether one of the approaches can be applicable when all Splunk indexers are off line. I would recommend using Splunk Forwarders (or WMI in the limited Windows case) as the first approach before investigating other ways to send data remotely.
| Approach to Send Data | Recoverable if Indexer is offline |
|---|---|
| Splunk Forwarder | Yes for local files and when using Multiple indexers |
| HTTP | Yes with replicated Servlet Containers |
| JMS | Yes for Transactional JMS Destinations |
| TCP or UDP | No |
As noted, the three approaches are not exhaustive on different ways to remotely gather data without using Splunk Forwarders or WMI. You are free to come up with any protocol that meets your requirements to add to this list. Please try to share your work other Splunk users.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.