Splunk as a Recipient on the JMS Grid
Tips & Tricks Nimish DoshiA number of years ago, I was fascinated by the idea of SETI@home. The idea was that home computers, while idling, would be sent calculations to perform in the search for extraterrestrial life. If you wanted to participate, you would register your computer with the project and your unused cycles would be utilized for calculations sent back to the main servers. You could call it a poor man’s grid, but I thought it of it as a massive extension for overworked servers. I thought the whole idea could be applied to the Java Messaging Service (JMS) used in J2EE application servers.
Background
Almost a decade ago, I would walk around corporations at “closing” time and see a mass array of desktops idling by. I thought what if these machines and all other machines in the companies could be utilized to perform units of work on behalf of common servers. Each machine could be a JMS client that happily turns itself on in off hours and receives a message encapsulated with data to perform some calculation. The client would receive an object from a queue and call one interface method:
void doWork();
That would perform the calculation on the client, encapsulate the results in the same object, and the client would place this object on a reply-queue. The application server would then receive the message via message driven beans and store the results in some back end store such as a database.
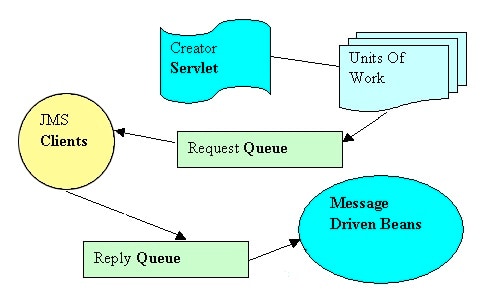
Keep in mind that these were the days before Hadoop, where mapped jobs can be sent to task nodes (although even in Hadoop, jobs are executed on servers, not on underutilized desktops, laptops, and Virtual Machines). So, my idea utilized JMS for the distribution of work. I created a self-contained framework for this idea that you can download for your own use at Github. Although, my implementation was tested on an Oracle WebLogic Server on a Windows machine, it is generic enough to run on any JMS implementation on any JMS platform. As long as the article is still being kept around, you can read about the entire implementation here.
The use cases for these types of calculations span many fields from executing banking applications, to gathering scientific analysis to performing linear optimization to building mathematical models. For my demo within the framework, I chose arbitrary matrix multiplication (used in weather forecasting apps) and mentioned that the results could be stored in a relational database.
Enter Splunk
What does this have to do with Splunk? Examine what a typical matrix would look like here:

Notice that not only is it time series data, but it also could have arbitrary size. Storing a 3×3 matrix vs. storing, say a 25×25 matrix, in a relational database for historical posterity and further calculations may not be trivial. It is simple to do with Splunk. (Remember, Splunk did not exist a decade ago, so you can excuse me for not mentioning it as a data store in the original article.) This means using my framework from Github, you can now easily store the data into Splunk for time series text data.
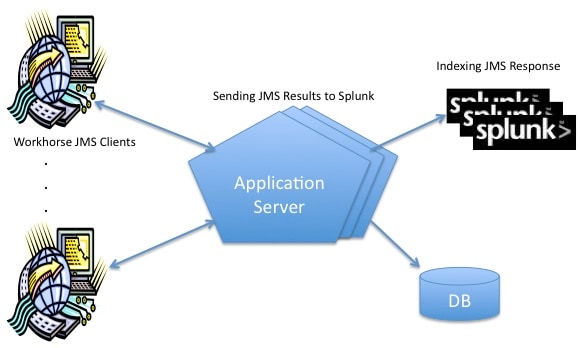
There are two ways to integrate the results into Splunk. One is to have the message driven beans store their results into a rotated file that is monitored by Splunk (or preferably Universal Forwarders). The other is to have JMS clients receive the results from the reply queue and have them send their results to standard output to be picked up by Splunk (or again, preferably Universal Forwarders). There is a technology add-on modular input in the app store to index the results from JMS clients that you can utilized for this latter approach.
You could even have the message driven bean recipients store their results into HDFS within a Hadoop cluster. You can then use Splunk’s HUNK product to query for the results using the Splunk search language without having to write Hadoop Map-Reduce jobs on your own.
Using the Search Language
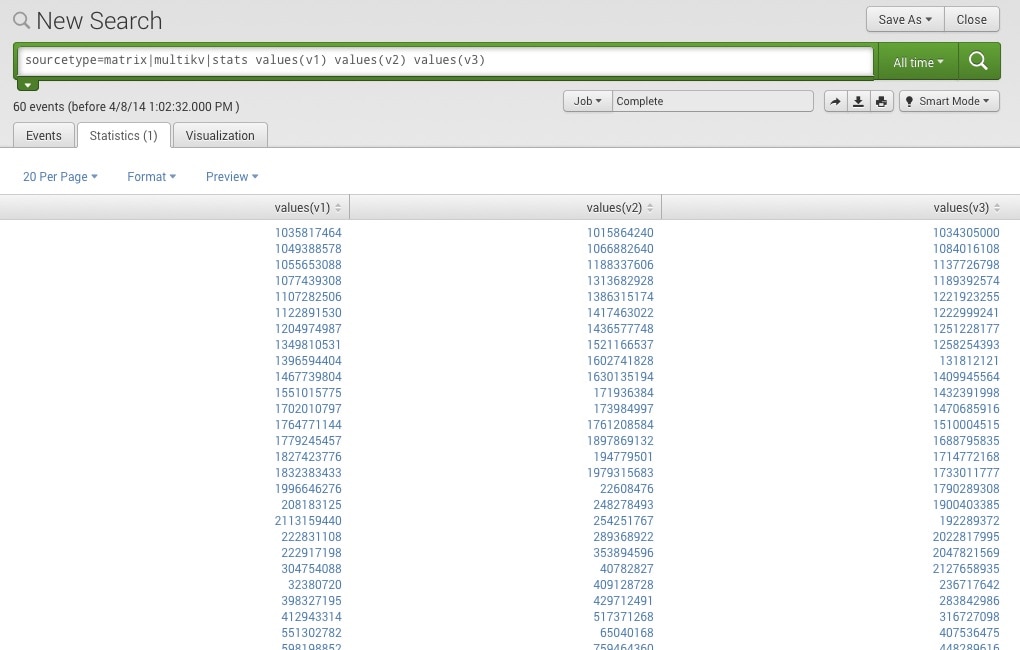
Speaking of the Splunk Search language, here’s some examples for what you can do with the matrix demo results being stored within Splunk in my example. First you can treat each column as a multi-value field and simply view the values.
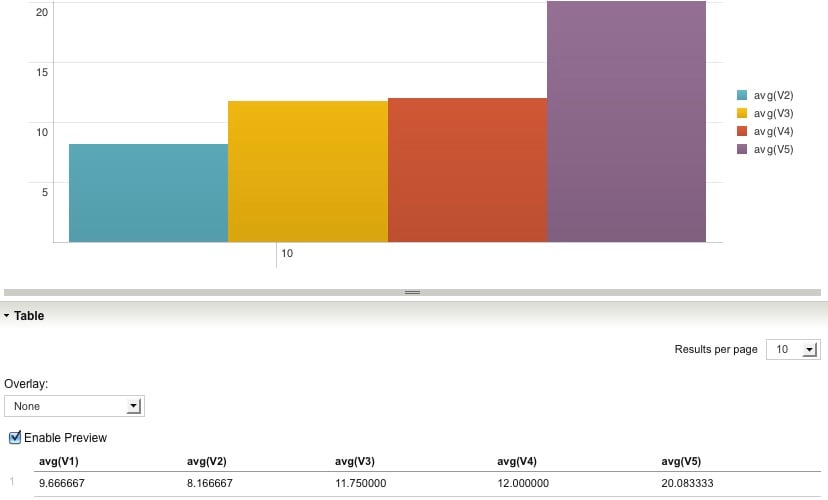
Next, you can create a visualization with the average of each column. Here’s a picture of this, when I first did this a few years ago within Splunk:
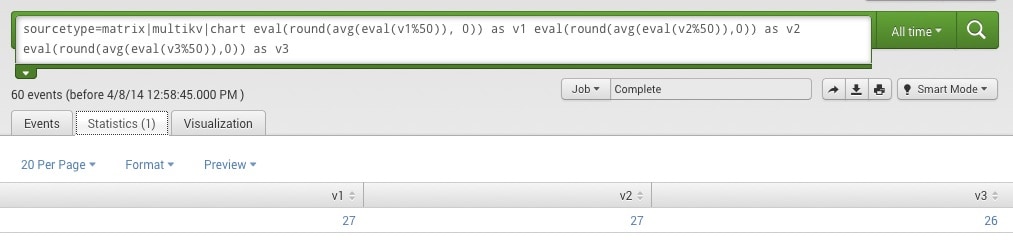
If you want to simply perform arbitrary math on the columns, here’s an example that creates multi-value fields for each column, uses mod 50 on each value, averages the column results and then rounds off the results into an integer.
Conclusion
Some may say that my ideas may sound outdated as we have existing frameworks for message passing and mapping jobs, but the simplicity of my approach is not matched. In other words, anyone who has used J2EE before can try this at home and it addresses the simple notion of utilizing a corporation’s peripheral computing power. The introduction of Splunk to receive these messages adds another dimension to the original work as unstructured time series data now has a scalable home for further analysis using a powerful search language.