Please Bypass the Database
Tips & Tricks Nimish DoshiIt has been a while since I posted to these pages and I am sure there may be one or two of you who misses my erudite musings or as some may say ramblings of a longtime Splunker. Either way, here’s my first post for 2015.
I have noticed that there are a quite a few deployments in the world that write time series data to a log rotated file and have another process translate those events into a rows and columns to be ingested into a relational database. After this extract, translate, and load process (ETL), they then use SQL to gather their database records either add-hoc search or for aggregate reporting. This practice has been going on for decades. The new twist to this is the same users discover Splunk and its DBConnect (DBX for short) add-on which allows them to move the data from the database in short intervals into Splunk for universal indexing of all fields and easy creation of reports without having to know SQL. Their approach looks something like this:
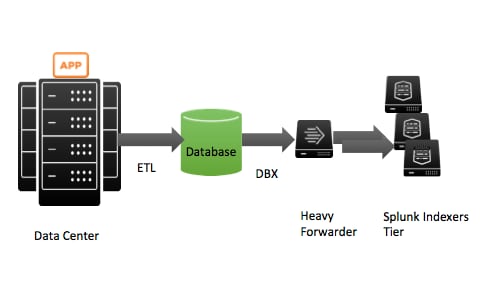
In this approach, a Splunk Heavy Forwarder has the DBX add-on installed upon it and it contacts the Database to gather its records. The events are then distributed in a round robin fashion to multiple Splunk Indexer Machines that may or may not be in the same data center. To the casual observer, this may look like a sound approach, but if you already have time series data written to files, you may as well bypass the database steps entirely as not to promote an ancient architectural acceptance. Doesn’t the picture below look easier to maintain and a lot more elegant?
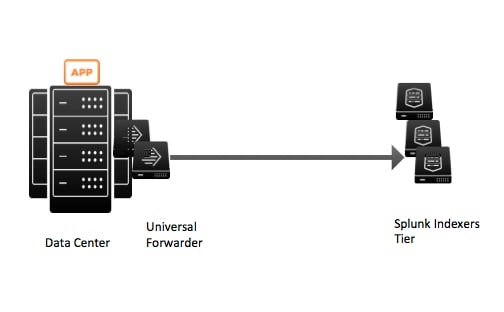
In the more modern approach, Splunk Universal Forwarders are placed on the data center machines that are collecting this time series data from different applications and sending the data in near real-time to Splunk indexer Machines that may or may not be in the same data center. With this, you have effectively done the following:
- Eliminated the Extract, Translate, and Load phase, which someone had to write and maintain.
- Eliminated the need for a schema to collect the data.
- Eliminated the need to constantly react to new adjustment to a schema.
- Eliminated the database entirely and its need for an administrator and license.
- Introduced near real-time collection of time series data.
- Provided some high availability through the use of universal forwarders that can pick up where they left off if the network gets severed.
I can ramble on, but I think the picture says it all. Bypass the database, use Splunk as the universal indexing engine as the platform for search, reporting, and alerts for your textual data and go home early.