Indexing Feeds
Tips & Tricks Nimish DoshiWe often talk about indexing the output of a program or script in Splunk as an universal way to index any type of text data that goes beyond monitoring log files. For those of you who may be new to Splunk, the idea behind a scripted input is that every configurable N seconds, any user provided script or program written in any language can be called by Splunk or a forwarder that gathers data and the standard output of that script or program is then indexed by Splunk. This is the basis for many of my contributions on Splunkbase such as indexing RSS feeds. Logically, this is a “pull” approach in that data is accessed by Splunk on a request basis. This leads to the question about a “push” approach or the more general question on how this can be done for continuous feeds. I will cover this topic here.
The business uses for this idea may be to capture third party feeds for use cases that range from financial services to telecommunications ASCII converted packets to social media feeds. The reasons for performing this capture and indexing may range from correlation with other data, alerting, analytics, troubleshooting, and availability. For the purposes of this article, I’ll cover the technical aspects for setting this up first and let our users fill in with real world use cases within the comments.
Network Ports
Let’s discuss the common example that may satisfy most needs. The idea is to set up a Splunk input to listen on a TCP or UDP port. A third party system such as a syslog generator or raw TCP feed can now push ASCII data to this address and port combination and Splunk will index it. Splunk has been able to do this from as long as I can remember.
Now, if you want your TCP or UDP listener to do more things like selectively modify events based on external conditions or filter them based on time of day, you can then explore writing your own TCP or UDP listener program that is called as a scripted input by Splunk. I’ve covered this subject before with a reference implementation.
General Purpose Feeds
How does one write a listener? An example is the JMS example implementation I have on Splunkbase. A scripted input is called with an interval of -1, which means it is called once upon Splunk start up. The JMS client listens on a queue for messages, dequeues the message, and writes its contents to standard output. Some may say this is not a continuous feed as queues by definition have discreet start and endpoints. I agree. However, the concept from a Splunk point of view is the same in terms of indexing the data from a listener whether it is being picked off a queue from a listener or being sent on a network port and using a 3rd party API to listen and gather data. In this manner, multiple listeners can be called at once on start up and listen for their feeds to gather data.
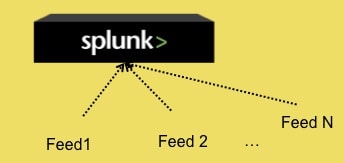
Feeds sent to Indexer
Each feed should have its own sourcetype assigned by the Splunk administrator. One more thing to note is that if you set the interval to a number other than -1 for your listener, Splunk will call your listener upon start up and then attempt to call your listener every N seconds, but it will only be started again if it is currently not running.
Scaling the Solution
You may be receiving millions of events per feed per hour. Having all of these feeds go into one indexer not only creates a bottleneck for indexing, but it also gives you only one node to perform subsequent searches. This is where using a forwarder and Splunk’s Map Reduce architecture comes into place. Place your listeners on forwarders and have the forwarders load balance the sending of data to multiple indexers. This not only provides fault tolerance for indexing the data in case one of the indexers is not available, but it also allows for subsequent parallel distributed searching.
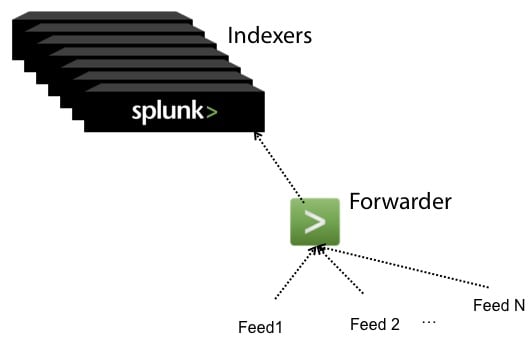
Feed to Forwarder
The next question is what type of forwarder does one use? If your feeds are truly continuous with no real discrete break points in time between groups of events, then a full forwarder may be required in order to properly load balance the distribution of data. If there are discrete breaks in time for groups of events coming in, then you may consider using the more widely used universal forwarder, which sends chunks of data at a time to indexers rather than individual events.
An Example
Here’s a straight forward use case. A 3rd party financial services company has a feed for various trading data and its own API to call a listener to gather this feed. First, write a program that uses this API as a listener, gathers the data, and writes it to standard output as time series data. Test the program from a shell script (or bat file on Windows) with all appropriate parameters passed to it outside of Splunk. If it works as expected, tell Splunk about this listener and enable it as a scripted input. This eventually gets put into an inputs.conf file, if you were to set this up in the UI from Splunk Manager.
[script://some_path/listener.sh] interval=-1 sourcetype=feed source=fs_feed disabled=false
You may also have to set up props.conf and transforms.conf for time stamp assignment and line breaking depending on the nature of your data. Restart Splunk and you should now see your data in the index assuming the feed is being sent. You now have a recipe for indexing continuous feeds.