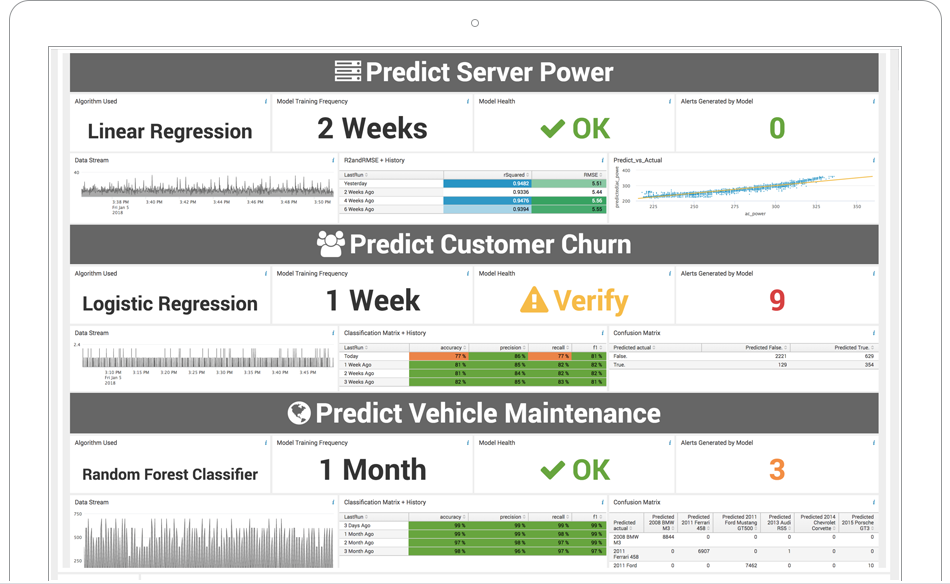
See how customers are using the AI Toolkit!
Splunk AI Toolkit
Build and deploy customized AI models and workflows
Build custom AI models with your data for actionable insights that inform faster, smarter decisions.
Guided AI development
Accelerate time to value with step-by-step guided workflows to build and deploy models for common business challenges.
Actionable intelligence
Operationalize your AI workflow: Collect and analyze data, train models iteratively, and set alerts — in real time.
Accelerate custom use cases
Develop production models for outlier and anomaly detection, predictive analytics and clustering.
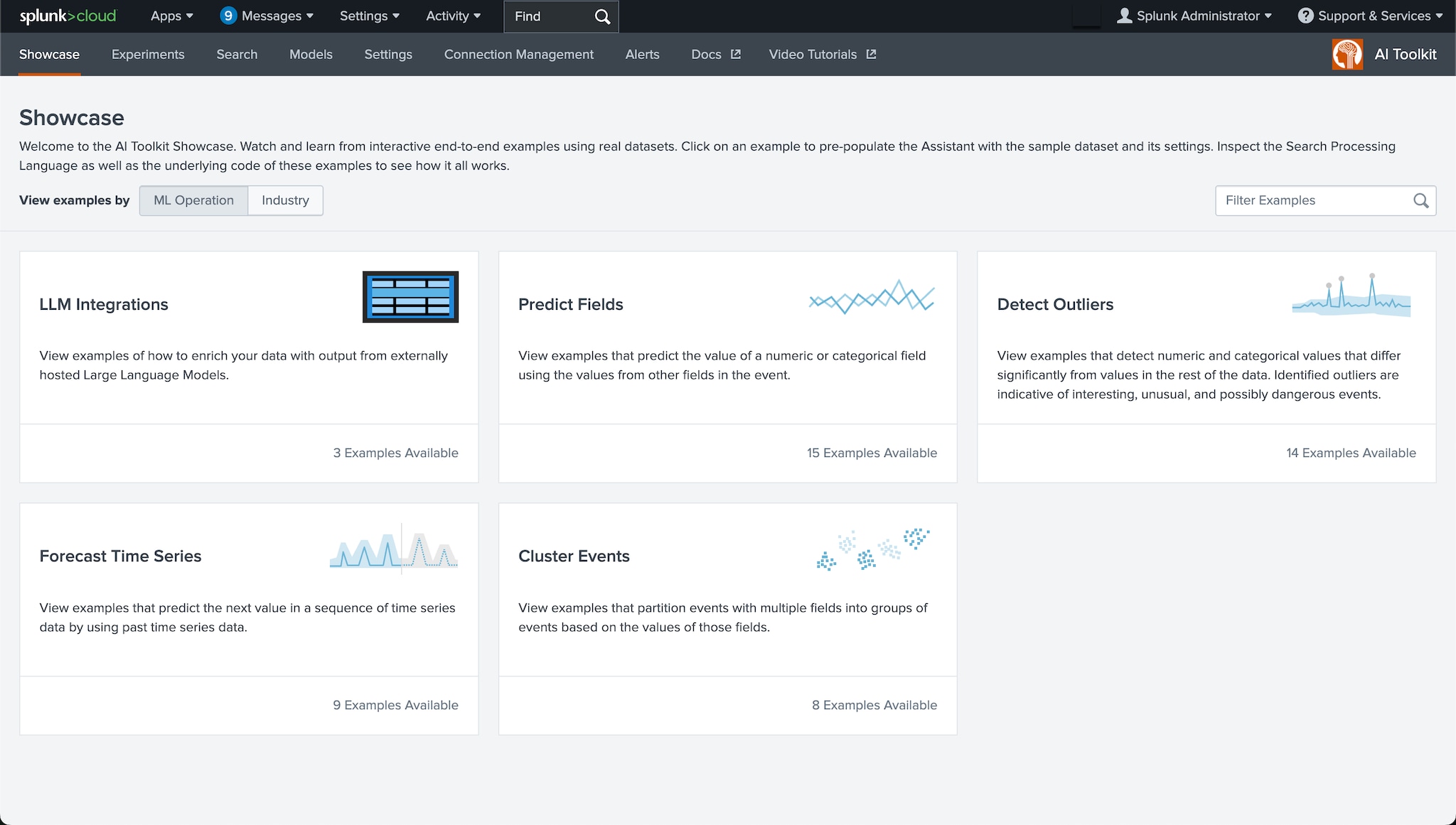
See what the AI Toolkit can do for you
SPL & open source library integration
Use machine learning SPL (Search Processing Language) commands to directly build, test and operationalize supervised and unsupervised models. Access the TensorFlow™ library through the Splunk AI Toolkit Container for TensorFlow™, available through certified Splunk Professional Services. Use any of the pre-packaged Python algorithms, or import any of 300+ open-source ones.
Faster Performance for Large Data Sets
Enjoy easier scaling, higher elasticity and faster compute on certain algorithms by leveraging Apache Spark™ to fit ML models on large data sets intuitively and easily. Access the TensorFlow™ library through the Splunk MLTK Container for TensorFlow™.
Detect Numeric and Categorical Outliers
Easily identify changes in website visits and tag odd transactions. Spot the spikes and events that contain unusual value combinations. Discover values that differ significantly from previous ones and find events that contain unusual value combinations.
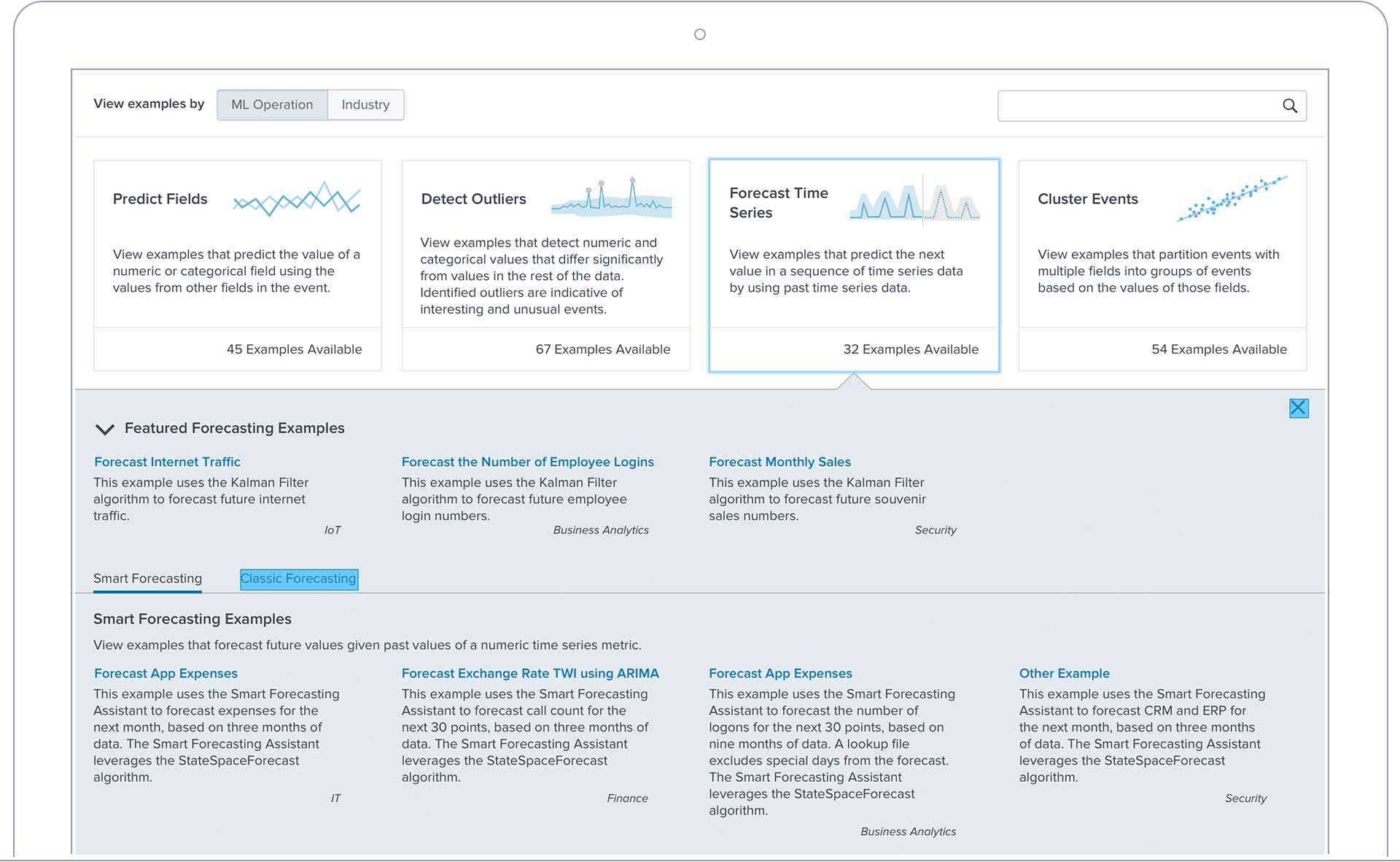
Time Series Forecasting
Make models that fit historical data and predict future numeric values, improving your organization's planning with accurate forecasts. Zero in on just how much to spend on hardware upgrades to support demand, how much to open cell tower bandwidth to accommodate local population growth, etc.
Cluster Numeric Events
Partition your data with clustering algorithms to figure out which hosts behave similarly or to identify hidden patterns, such as undiscovered trends in online purchases, anomalies in security environments and spikes in resource use.
Predict Numeric and Categorical Fields
Build predictive models around numeric or categorical events (numeric or categorical) that are crucial to your business. Use those predictive models for planning, or to uncover anomalies in your earnings, costs, demands, usage, capacity, etc.
Spot the red flags with anomaly detection
Through intensive training, AI and machine learning establish baselines for your data and detect deviations from past behavior or atypicalities that might otherwise go undetected. See how the National Ignition Facility identifies atypical behavior as it monitors the U.S. nuclear stockpile.
See the unseen in your data with clustering
There are patterns in your data that human analysts will miss: trends in ITOps and in security, and patterns in customer behaviors that suggest new markets and opportunities. Automate analysis of clusters to identify and group similar data points to help you see the signals in the noise, and make better decisions. See how pharma startup Recursion identifies high-value patterns in large sets of genetic research data.