
New Report: Observability Platforms
Get the 2025 Gartner® Magic Quadrant™ for Observability Platforms for free.

In this blog post, we will walk you through how to develop a continuous performance management playbook for your business to effectively integrate and manage performance as an integral part of your development process – enabling you to build fast experiences faster than your competition. Let’s dive in!
The worst time to learn that a business-critical performance metric depreciated is once a release is in production. Poor site performance can lead to losses in conversion rates and sends frustrated users running right to your competitors. The earlier you can detect a problem, the easier it is to resolve.
In today’s world, the ability to build fast apps or experiences is no longer a competitive advantage – it’s an expectation. Now the advantage is to build fast experiences faster than everyone else. In this increasingly fast-paced industry, the need to push new features and experiences has outgrown traditional methods of software development, in which conception, design, testing, and implementation are discrete entities, which can be potentially spread out over a long timeline spanning weeks or months.
In response to the race to the new release, these cycles of delivery and deployment have condensed into near continuous mini-cycles complete with more frequent releases, some even as short as every twenty-four hours. Continuous delivery and deployment require a paradigm shift with regard to development, integration, and feedback cycles. As these cycles shorten, development and deployment can respond rapidly as business requirements and industry trends change from day to day.
Shifting from the more linear concept of the waterfall model, the phases of build > test > fail or succeed have condensed from days (or even weeks) into more immediate feedback for developers, thereby helping to minimize the possibility of lost man-hours (read: money) and roadblocks (read: more money) when implementing new code changes. With continuous development and deployment, developers have greater control and visibility into defects, enabling them to remediate any potential issues before go-live.
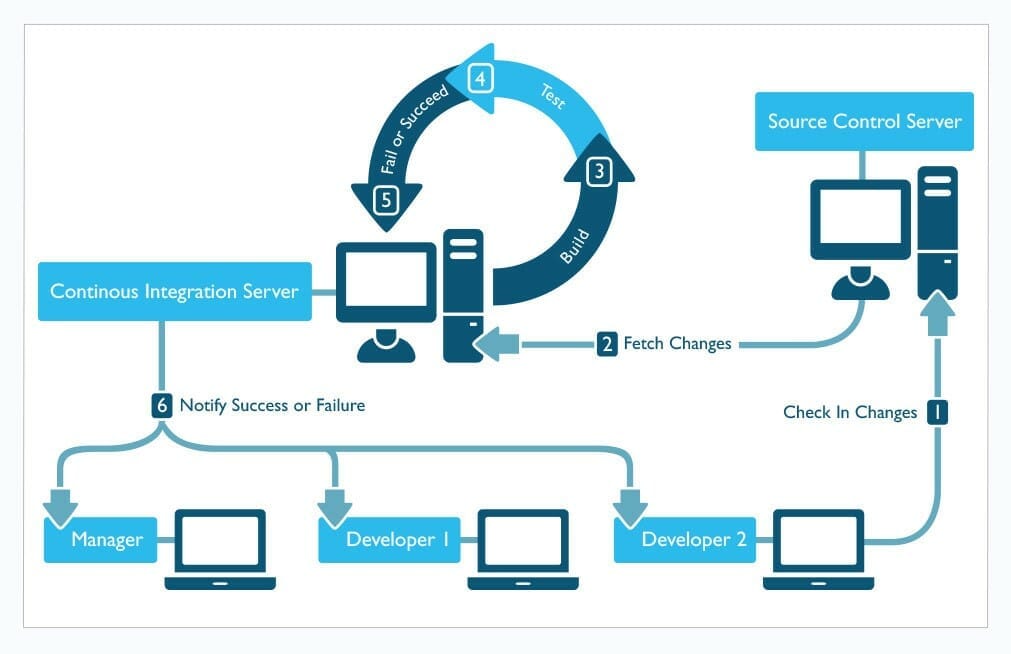
Source: Carnegie Mellon University’s Software Engineering Institute
As these phases continue to condense, one key component is the importance of evaluating the performance impact of a new feature at every stage of the software development lifecycle. To be able to move fast in today’s world, you must have confidence in your abilities to test, review, and deploy your applications without negatively impacting your end-user experience. Remember, it doesn’t matter how fast your development cycle is if you’re putting out flawed code that negatively affects your application’s performance. Your development cycle has to be both fast and dependable.
For example, can you imagine a release without extensive functional testing? Finding out that something failed after go-live is a worst-case scenario. In a more ideal scenario, you would test the entire app and fail the build for any critical use cases that don’t function properly. At a minimum, your developers should have transparency into what functional errors exist, consequently providing the tools for a cost/benefit analysis to decide which errors are acceptable for go-live.
In this burgeoning realm of continuous development and deployment, moving quickly with confidence requires that organizations learn to automate as many of their development activities as possible. This might include using a continuous integration server to automate and test the build process.
This also means going beyond the concept of the simple functionality binary (i.e., Does the feature work? Yes or No) to a more refined concept of functionality and performance. We agree with Andy Still that:
Performance…is a consequence of legitimate activity and once resolved should stay resolved. To that end, once the methodologies for addressing performance issues are understood they can be applied in multiple situations. These elements are not beyond the capabilities of a good developer, given time and space to do so.
Moreover, we know that performance metrics can directly affect business goals (e.g., conversion rate) with an impact equal to functionality defects. Given this knowledge, implementing a build without transparency with regard to its effect on performance metrics no longer makes sense. Integrating and automating testing as part of a build or continuous integration system is critical to ensuring consistent and repeatable insights. Performance best practices have become standard practices, yielding better products that perform better.
To remain competitive, organizations must consider phasing in the features of continuous performance management, especially with regard to automation.
Let’s talk numbers: Did you know that the revenue impact from a 10% improvement in a company’s customer experience score can translate into more than $1 Billion? Here’s another surprising fact: By 2020, customer experience will overtake price and product as the key brand differentiator.
What’s the main takeaway here? Gone are the days of winning business solely on price or name recognition. Users want it all and they want it delivered fast. User experience is becoming a main driver of business and as such companies can no longer afford to slide it onto the bottom of the pile of priorities. In an increasingly competitive market, a positive user experience translates into customer satisfaction, brand recognition, and revenue.
Think about the last bad experience you had with a website. What did you do? Did you wait it out, waiting patiently for the page to load, or did you head over to a competitor’s site? How did you view that company after your bad experience?
If your site hasn’t loaded in three seconds, you will have lost up to 40% of your viewers.
It’s obvious user experience is important, and keeping users happy means creating experiences that are fast, easy to use, and reliable. After all, you don’t just want people to visit your site once, you want to keep them coming back for more. This means being proactive about the user experience by incorporating automated monitoring solutions.
Traditionally, the majority of the IT monitoring money budget has been spent on monitoring the bottom of the technology stack (i.e., infrastructure) with most server monitoring solutions focusing on application uptime and hardware performance such as transaction logs and storage. While uptime is absolutely important, this type of monitoring, known as back-end monitoring, doesn’t allow for evaluating the true quality of services being delivered to users. Business and IT stakeholders say they get the majority of the value (around 80%) from the end-user monitoring data they collect.
Furthermore, as companies begin to rely more and more on third-party hosting providers and content pulled from decentralized sources, it makes less sense to devote budgetary resources to monitor only server and network functions. Finally, as the price for quality servers and network hardware falls, the likelihood that infrastructure is the bottleneck also decreases.
As users demand more and more from sites, the complexity of the systems used to deliver content has expanded. Gone are the days of hosting a static site from a central server, with a simple shopping cart or a few news articles. The demand from today’s users requires a lot of moving parts and just monitoring the infrastructure won’t cover it.
What’s a savvy technology business to do? Flip this traditional monitoring convention on its head: Reevaluate your technology stack by inverting the traditional method of monitoring. Start with a user-first approach to maximize attention on the biggest drivers of business – the user experience:
1. Start with the User First: Start by focusing on key performance indicators (KPIs) for user experience like time on site, SpeedIndex, and the conversion rates of critical business flows or call-to-actions.
2. Move on to Transactions: Monitor transactions between the application and the user and identify which transactions are causing issues with user satisfaction.
3. Turn Your Attention to the Application: Check for software bottlenecks or limiting third-party applications on the high traffic areas of your site.
4. Evaluate the Hardware: Finally, focus on infrastructure and hardware, including servers and networks for disk and CPU failures, security issues, network problems, etc.
Gone are the days of colossal self-contained, stand-alone applications and singular business processes. Whereas once developers had to spend days and weeks writing functionality into an application, now they can quickly integrate functionality using a host of APIs (application programming interfaces) and microservices that enable them to create systems that are more flexible, modular, and easier to maintain.
Let’s not forget about the Internet of Things (IoT), where the end user might even be your refrigerator or your car. According to Statista, in 2012 the number of connected devices reached 8.7 billion, with numbers estimated to reach over 50 billion by 2020.
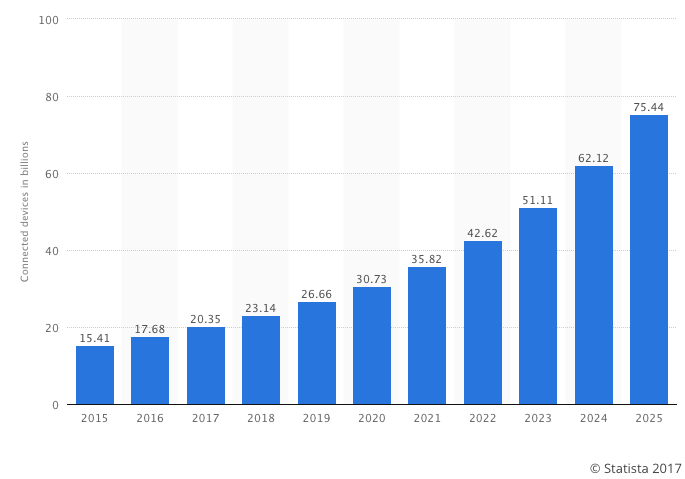
Source: Statista
We’ve already explored the limitations of relying solely on back-end monitoring to evaluate the user experience. In this section, we’ll concentrate on front-end monitoring, which focuses on the application from the user side and includes web performance KPIs such as transactions per user request, bytes downloaded per transaction, browser-related issues, etc.
As if you needed more convincing about the importance of front-end monitoring, the image below illustrates the surprising disproportion between back-end and front-end times. Back-end time is defined as the time it takes the server to get the first byte back to the client and includes database lookups, remote web service calls, etc. Front-end time is everything else – executing JavaScript, rendering the page, loading resources, etc. You can see from the diagram below that the front-end time counts for the majority of wait time. In his Performance Golden Rule, Steve Souders estimates that 80-90% of the time users spend waiting on a page to load is due to the front-end.
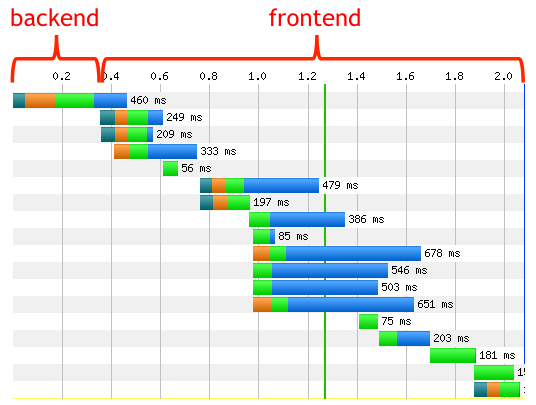
Source: Steve Souders
Let’s take a look at the two forms of front-end monitoring: synthetic monitoring and real user monitoring.
Synthetic monitoring is defined as measuring the performance of your web application using simulated traffic with set test variables, such as network, browsers, locations, and devices. In this instance, the users are simulated and follow a specific path or behavior to simulate actions real users would take within the application. Because this method is defined by paths, synthetic monitoring is more helpful for heavily traveled pages and user flows. Synthetic monitoring is good identifying major performance problems and service disruptions, testing pre-production changes, or for baselining performance. Consider synthetic monitoring as a way to proactively monitor for problems before they affect actual end users.
As the name would suggest, real user monitoring (RUM) tracks real-world user interactions with your site. RUM is a JavaScript tag you can include in your site to provide high-level performance metrics including response time, server time, access location and device type. RUM is helpful because it captures the performance of real users, no matter what pages they visit. This type of monitoring is helpful for larger websites with content that updates frequently.
Ideally, you would use a combination of synthetic and RUM. We recommend starting with synthetic monitoring because it can be used in pre-production environments, shifting your performance monitoring earlier in the process to proactively head off any problems with the user experience before go-live. And because you define the parameters, synthetic monitoring also provides a cleaner baseline for identifying performance regression and performing root-cause analysis should problems arise later on.
You can follow up synthetic monitoring by adding RUM as your budget opens up. RUM is helpful in tying real-world website performance to your business KPIs and in identifying areas of your site that need performance improvement. You can also use your RUM results to help evaluate the ROI of your synthetic monitoring systems as performance problems and service disruptions are eliminated from the later stages of your software development lifecycle through pre-production testing.
So, you’ve decided after all of the awe-inspiring (or potentially terrifying) statistics and colorful graphics to go with a monitoring solution. Great! But how do you pick the one that’s right for you? We have a few guidelines that might help:
1. Purchase for Value Added to Your Problem: Avoid just looking at the overall feature set. Ask yourself the simple question “Does this solution solve my problem?” If the answer is no, move on.
2. Avoid Feature-to-feature Comparisons: Quite often it will be more like comparing apples to oranges. Try to take the big picture approach to evaluate overall value and the total package.
3. Consider Support for Key Business Results: Are you an eCommerce site owner who needs insight on conversion rates, or are you a SaaS provider who needs to monitor your SLAs? Make sure the solution you choose can support the KPIs you want to monitor and improve.
4. Look for a Tool with Actionable Insights: Do you need to reduce the render time of your web app to drive more conversions? Great! Look for a tool that provides actionable insights and recommendations. If your solution monitors the problem, but it doesn’t help you improve it, then it doesn’t align with your business needs.
5. Treat the Complexity of the Solution as a Feature: How quickly can a solution be implemented and how soon can you expect to receive value? What’s the total cost of ownership – does it require professional services to implement and manage or can Gary down in DevOps handle it? Is support included in the cost? Does the vendor have references to validate its customer service?
We’ve examined the importance of monitoring and improving site performance from an end user perspective, and what can happen when the user experience is neglected. Now, let’s switch into action mode to answer the when, how, and what of performance monitoring.
In an ideal world, software developers would spend their limited time designing and implementing new features and functionality. But in the messy real world of application development, much of their time is taken up resolving defects. And the later these defects appear in the development cycle, the costlier they become. According to IBM’s Systems Sciences Institute: The cost to fix an error found after product release was four to five times as much as one uncovered during design, and up to 100 times more than one identified in the maintenance phase.
Moreover, we find that the majority of defects, 25% and 35% respectively, creep in during the design and coding phases of the SDLC. In the past, developers had to manually search for these errors, spending hours on making assumptions, and then predicting and locating the source of a bug. However, as applications expand to include third-party functionality, distributed content, and microservices, this task of defect prevention and remedy becomes more and more complex. And in the race to build fast experiences faster than everyone else every second counts.
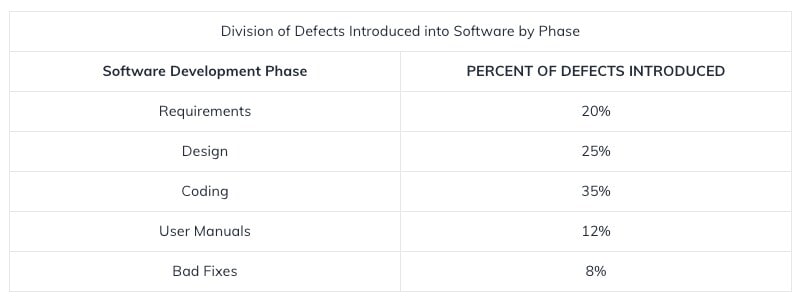
Source: Computer Finance Magazine
Also, recall as you begin to focus on the user experience, you must make the paradigm shift to move away from the simpler functionality binary question of “Does the feature work?” (Yes or no) to the more complex questions of functionality and performance. From both an improved user experience and a cost-benefit perspective, you need to shift to a more proactive and preventative approach by progressing the initial functionality question to include: “How well does the feature work, and does it affect the performance of my site?” Much like health, in software prevention is the best cure.
In examining both the cost of a defect once it reaches the maintenance phase and the percent of defects introduced during coding, it makes the most sense to move performance monitoring to earlier phases in your development lifecycle – into the phases of development and implementation. To detect and correct performance problems before they impact users, you need to shift your battle plan to include monitoring as a part of the software development process, rather than just the software maintenance process.
Moving monitoring into non-production environments means that you’ll need to select a synthetic (active) monitoring solution. Remember that synthetic monitoring simulates user actions and traffic to identify problems and evaluate slowdowns before the problem affects users and customers. Synthetic monitoring is best used to simulate typical user behavior or navigation to monitor the most commonly used paths and business critical processes of your site.
We recommend using the three best practices below as a starting point to make the shift into monitoring performance during your development phase:
Monitor Pre-production Environments: To get a better handle on defects earlier in the process, you need to monitor performance in your pre-production environments. Problems can also arise when development and operations try to reproduce issues in different environments, so you’ll want to use the same monitoring solution in your pre-production that you use in your production environments.
Additionally, ensure that your teams are using the same set of KPIs to evaluate both environments. With that said, try not to compare your development and production environments as apples to apples. Use your monitoring solution to establish baselines for both environments and understand how these baselines relate to one another. Know that regression in one development will lead to regression in production, even though the regressions likely are not identical.
Track Code Changes within the Solution: Help identify the causes of regression by tracking code changes in the tool itself. When choosing a monitoring tool, make sure the system can annotate development changes and track performance changes before and after deploys.
Evaluate Performance Regression Often: Look for performance regressions with every meaningful engineering event. Define the severity of defects you want to track to cut down on alerting noise and hide low or known issues. Set alerts to notify you if performance degrades or improves after a deploy.
Shifting your perspective on when and how to monitor will also have an effect on what you want to monitor. Historically, web performance monitoring has focused on availability, initial response times, uptime, etc. Again, those are all great stats, but moving into a more proactive position requires that you reevaluate how you are assessing performance. While you should use the same KPIs that you use in production in your pre-production environment (such as those listed above), make sure you ask and understand all the KPIs.
For example, as an eCommerce provider, you may want to track the time to an interactive because this is when people can add items into a cart (read: sales and revenue). However, your Ops team may only be concerned with general availability and page load timings. Start to grow your monitoring strategy beyond general performance KPIs, such as render time, load time, page size, and number of resources, and make sure you’re also establishing KPIs that align with your business needs.
So far, we’ve examined the importance of the user experience and incorporating performance data to improve the customer experience, but those are only part of the picture. Monitoring for issues and analyzing performance is great, but if your technology doesn’t help you prioritize and optimize content that is negatively impacting performance, you’re only halfway there.
Step one involves mapping out and enforcing your internal performance best practices. With hundreds of front-end performance optimizations out there, the task of defining your best practices may seem daunting at first. Don’t worry, just start small: Ask a few questions – similar to the way you defined your business KPIs. Remember that when it comes to web performance, one size definitely does not fit all. Use the questions you come up with to help define the performance best practices that best fit your business needs and the way you’ll be using your site. Begin by asking just a few questions and you can always expand your list of best practices as you go.
Additionally, consider putting together a team of different stakeholders in your organization to help determine how your best practices can fully align with and support your business needs. Get a perspective from different areas of your organization, including development, operations, and line of business. Work together to define your list and to decide the thresholds for those “mission critical” issues vs. those that cause acceptable losses in performance.
Some questions to discuss might include:
In the cutthroat world of digital business, we know that end users drive both innovation and the pace of development. And as end users demand faster response times with deeper functionality from their applications, developers have had to shift their conceptual model of architecture to begin implementing a more modular approach. This is where microservices comes in – and their popularity is on the rise: In a survey of about 1,800 IT professionals, about one third currently implement some form of microservices. This number is expected to grow exponentially, however, with over 70% of them affirming that they’ll be using some form of microservices moving forward.
If you’ve been around technology a while, you’re probably familiar with traditional approaches to application development. In more conventional architecture solutions, such as the traditional server application approach, developers typically constructed a single, large application with tiers that pass data or communicate with each other within a single domain. Even though functionality is distributed among layers, everything is packaged into a singular monolithic application. This type of architecture is great for creating reusable services and is fairly easy to test. One of the downsides of this method includes a lack of scalability, which would require cloning the entire application across virtual machines or servers. Also, with this approach, if a single application function or component fails – the entire application fails.
Microservices takes this concept of a segmented approach a step further by separating discrete processes out into individual functions that can be developed and scaled independently. With the microservices approach, developers can deploy a single service, without relying on the rest of the applications components to be completed. Whereas the traditionally designed components tend to be larger and encompass many functions within a single layer, the discreteness of microservices make them more nimble and able to be scaled quickly as load demands increase. And because microservices make use of universally accessible APIs, they don’t limit changes in technology stacks – enabling developers to be more flexible in their approach to coding.
Shifting from a more monolithic approach to segmenting out functionality through the use of microservices also improves productivity. Now, developers can produce applications even faster that are more complex and easier to maintain. Microservices also help improve fault isolation; unlike with the traditional approach, the failure of a single microservice may have less of an impact on performance.
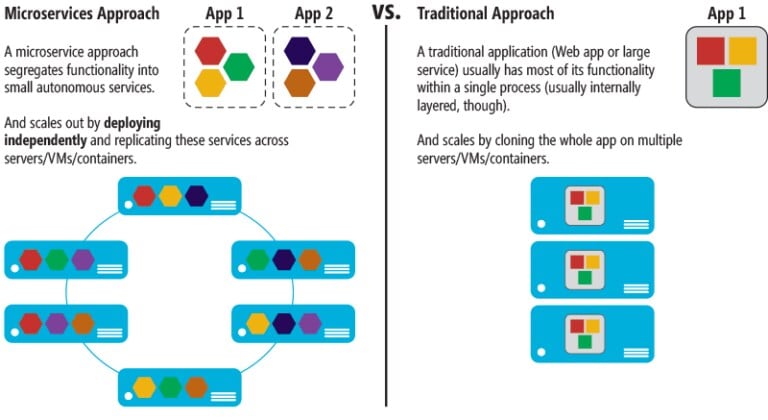
Source: MSDN/Microsoft
By this point, you understand the importance of monitoring your application from the end user’s perspective. Remember that most people will only wait about 6 to 10 seconds before they abandon a page. And after 20 seconds, half your audience will be gone.
Traditional monitoring approaches focus on evaluating a microservice’s server logs – but this only tells part of the story. Testing services in isolation doesn’t provide a clear picture of how those services are working together. Individual services may work according to normal parameters and metrics in isolation, but combined into the whole may negatively impact performance. End users don’t function in isolation; they function in user flows and transactions. Testing the entire system synthetically – predicting for user behavior and monitoring your microservice interactions as a whole – is the only way to evaluate how the entire system is behaving.
Feeling overwhelmed? Don’t worry – implementing monitoring of your microservices is easy and just takes few key steps to get started.
Keeping in mind that you need to be proactive in your monitoring (i.e., prevent problems before they reach users), you need a solution that can test for performance issues in your pre-production environments and baseline the performance of your production environment. This means you’ll want to opt for a synthetic monitoring solution over real user monitoring. Remember that with synthetic monitoring, you’ll be developing behavioral scripts to simulate user actions and your solution will monitor them at specified intervals for performance, including availability, functionality, and response times.
Implementing proactive monitoring of microservices requires a solution that can replicate complex user flows and execute the following tasks:
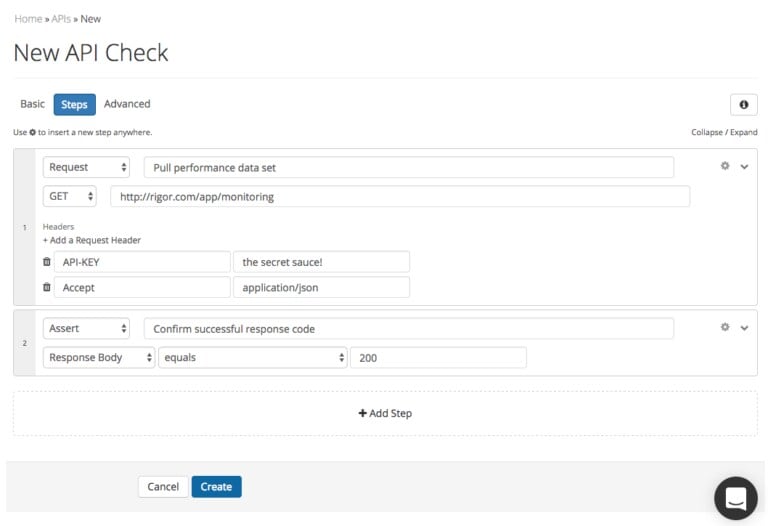

Splunk Monitoring tracks and analyzes KPIs vital to your business.
Begin by evaluating your business needs: Are you an eCommerce provider who cares about how site performance affects shopping cart abandonment and average order values? Or a content provider who’s concerned about sluggish ads negatively affecting your user experience?
Sample industry-specific KPIs include:
eCommerce:
Media/Content Provider:
Enterprise and SaaS Providers:
Not even sure what questions to start with? Use online resources, such as Google PageSpeed Insights, Yahoo!’s YSlow analyzer, and Splunk’s free performance report, to analyze your site and help build your best practices list.
Once you’ve determined your best practices, it’s time to enforce them. Use a commercial optimization tool, such as Splunk Optimization, or build an internal tool to test your best practices as a part of your continuous integration process. You’ll need a tool that can analyze your best practices based on policy parameters, prescribe a solution, and alert you of any performance errors and issues that meet your pre-defined thresholds.
Analyze Your Policies: Once you have your best practices defined, you’ll want to continuously analyze your site, remembering to analyze any ongoing development. Splunk’s Optimization service tests for hundreds of performance best practices, and results can be customized to check only for those best practices your team is implementing. You can also create custom check policies to highlight opportunities for improvement and add thresholds that match your defined limits. Then, simply run your test and if any part of a page violates your best practices, Splunk Optimization flags the defect if it meets your defined threshold for reporting.
With Splunk’s open API and out-of-the-box integrations, you can implement optimization into your build system or continuous integration processes to automate regression detection, enabling you to discover any new issues immediately – before they go into production.
Fix the Problem: As we said earlier, your analysis tools aren’t very helpful if they don’t help you fix the problem. Using the performance data gathered in Splunk Monitoring, within seconds Splunk Optimization provides a prioritized list of optimizations from a library of industry best practices that can be downloaded and implemented at the push of a button.
Create Smart Alerts: Receiving too many alerts just turn them into noise. No one wants to open an inbox full of useless messages, having to manually sort out which ones are important and which ones to ignore. Cut down on the noise by customizing alert criteria based on the thresholds you defined in your performance best practices. Set alerting windows to refine when and who to alert for the most urgent and critical issues.
As the complexity of digital applications increases, so does the size of your team. Stakeholders include designers, engineers, quality assurance, line of business owners, and third-party services (e.g., web analytics, ad providers), collaborating across functional initiatives. As such, you’ll want to include members from different parts of your organization in the optimization process. While you’re mapping out your best practices, take time to identify and map out responsibilities for key stakeholders. Use a tool like Splunk to build processes for triaging performance problems to the correct owners to expedite time to resolution and improve the regression feedback loop.
Remember that the cost to fix an error after product release is four to five times as much as one found during design, and up to 100 times more if identified in the maintenance phase. So, test and enforce your best practices early and often to avoid deploying troublesome builds into production.
Now that you’re ready to incorporate performance monitoring and optimization into your development process, you’ll want to keep a couple of key things in mind. First, realize that your monitoring solution is pretty useless if you can’t integrate it into your workflow in a meaningful way. Also, remember that in keeping end users happy and preventing performance slowdowns from reaching production, you’ll need to evolve the way you think about performance regressions. Just like functional regressions, they’re bugs that you need to identify early – before they affect end users and become costlier to fix.
Recall that Continuous Integration (CI) and Continuous Deployment (CD) is the glue that holds everything together. If you’re implementing CI and CD to automate your test and build processes, integrating your monitoring solution into them just makes sense. Accordingly, you’ll want to integrate your monitoring solution into three major interaction points in your process flow:
With CI and CD, you may be releasing code changes on a daily basis, and the faster you can provide feedback to your developers, the less chance you have of any performance degrading issues slipping through. Your build systems are a natural integration point to run tests and validate your internal performance best practices. The more you can automate – the better.
Check to see if you can use Splunk’s API to kick off an optimization scan when any code change is made to analyze how that build improved or regressed performance. Test your build as soon as changes are deployed into your staging environment. Remember, you want to test your site from the end user perspective, so this type of testing will follow unit testing for functionality. If your build passes the parameters you’ve set for internal performance best practices, you’re ready for QA and deployment into production. After you’ve gone live, use Splunk to monitor your production environment to be immediately alerted of any performance issues that may crop up as real users begin to use your application.
Again, you’ll want to reconfigure your definition of performance issues to call them what they are…bugs. Performance issues don’t need to be treated as special, isolated events, disconnected and separate inside your monitoring solution. Tasks have defining characteristics (e.g., severity, priority, information) that map well to performance alerts. For example, a performance issue causing your site to be offline has a severity of critical, whereas having too many images would be considered medium severity and priority. Integrate Splunk to pull actionable alerts into the tracking systems and task managers you already use such as Trello, JIRA, GitHub, or other IT ticketing and helpdesk systems. Triage issues directly into these systems to make sure you’re able to prioritize your performance bugs alongside functionality defects.
Notifications are only helpful when you get them where you’ll see them and when they’re targeted so you don’t ignore them. With the majority of people now spending most of their times in chat systems, like Hipchat and Slack, email is no longer the best way to receive notifications. Integrating with chat systems has the added benefit of the inherent one-to-many system, since multiple people are in a chat room or channel at once. This can help prevent partitioning of alerts and information, helping to ensure that the right people get the message quickly. You can also leverage the alerting, searching, and archiving native to the chat solution to safeguard against lost notifications. Automate reporting processes by leveraging chat bots to log performance tickets, and to allow your team to receive and to respond to operational alerts.
In today’s world of digital business, end users are king – constantly challenging organizations to build fast experiences faster. Nevertheless, in the mad dash to the finish, the winner isn’t just the one who can produce a fast experience faster; the winner must produce a fast experience (faster) that also provides a better and more reliable user experience.
Keeping end users happy doesn’t have to be a struggle. Here are six key concepts to keep in mind as you begin to evaluate how to implement performance monitoring into your continuous integration and deployment workflows:
Performance Problems are Bugs. A common definition for a bug is “unintended program behavior;” no one intends to have a site be slow! You should treat performance as an integral part of your software development lifecycle. Test performance issues the same way you would functional issues: Test early and test often. Avoid cost creep by preventing performance issues before they end up in production. Remember that the cost to fix an error found after product release is four to five times as much as one uncovered during design, and up to 100 times more than one identified in the maintenance phase.
Focus on the End User Experience. Recall that the end user experience is what’s driving your business, so measure performance from the end user perspective. This means going beyond simply unit testing for functionality. If you’re currently spending most of your time and budget on monitoring the bottom of your technology stack (i.e., server uptime and availability statistics), flip that on its head and begin to focus on monitoring performance from the end user perspective. Test for performance in your staging environment and then monitor performance once you move to production. Don’t forget: End users don’t have to be human! Remember to consider microservices, APIs, and the Internet of Things.
Shift Monitoring Left. The worst time to learn that a business-critical performance metric depreciated is once a release is in production. Don’t wait until performance becomes a problem for your end users. Monitor and test every engineering event for performance regression. Incorporate your monitoring solution into your Continuous Integration and Deployment cycles and test your pre-production and production environments using the same tools.
Be the Performance Police. Create your list of internal performance best practices by defining your business needs and set thresholds to evaluate which issues are critical and which ones are acceptable. Get perspective from different stakeholders in your organization (line of business owners, development, operations, etc.), to help guide the conception of your best practices. Automate testing of your performance best practices and integrate this stage into your Continuous Integration process. Use Splunk to build processes for triaging performance problems to the correct owners to expedite time to resolution and improve the regression feedback loop.
Don’t Forget Microservices. If you’re an organization that has already made the shift – or if you’re thinking of making the shift – to using microservices, be sure to include them in your performance testing. Remember that a microservices infrastructure exponentially increases your potential points of failure, and testing microservices in isolation only provides part of the picture. Your users don’t use microservices in isolation, so test them as a part of the whole user experience. Run API checks to quickly identify when and where a transaction failed to facilitate an efficient and meaningful effort to resolve the issue.
Let Performance Monitoring Become Second Nature. Begin to think of performance monitoring as native to your development and build processes. Integrate monitoring into all of the major interaction points of your Continuous Integration process, including your build system, bug tracking/task management, and communications. Look for built-in integration points or use Splunk's API to create integration points to automate as many processes as possible. Pull actionable alerts into task management systems and create targeted notifications by interacting with chat systems for immediate response to performance alerts.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.