Splunk, Developers, and SOA Apps
Observability Nimish DoshiWhen most people first come across Splunk, the first set of users associated with it naturally become operations, security, or compliance personnel. Splunk naturally lends itself for their use. I was speaking to some software engineers explaining what Splunk does and the connection for how it could be used for their engineered Service Oriented Architecture applications did not come immediately. I told them that one of Splunk’s T-Shirts reads “Be an IT Superhero. Go Home Early.” At that point, I got their interest.
Let’s get back to the basics for one of the reasons Splunk exists, which applies to not only SOA, but also to all phases of multi-tier deployment. The typical developer may be involved in multiple stages of SOA development that produces applications and services residing on multiple physical servers. When something goes wrong on any of these servers, the developer may get called to investigate, but for reasons of security, are not given access to these servers. So, our friendly neighborhood developer, next calls someone in operations, who zips up relevant log and trace files to send to the developer via an FTP server. The next steps involve getting the files, unzipping them, and running various home grown scripts which usually have some derivative of Perl, Awk, and SED, to search for issues. If the results are not available for this server or it turns out another server is the culprit for the issue, the whole process is repeated and can take a while to accomplish.
Along comes Splunk to automate this whole effort and make IT search as easy as using a browser based search engine. Splunk Light Weight Forwarders (LWF) are installed on every leg of the SOA process to monitor application produced data. Each forwarder sends events to Splunk indexers in a Splunk controlled automatic load balanced manner. A separate Splunk server called a Search Head, which is essentially a Splunk indexer that does not index, but participates in a distributed search, is used by the developer to find the issue. Each event has a timestamp, host it came from, source file name, and a classification called sourcetype to narrow down the search. In a matter of minutes, issues can be tracked down, for what used to take hours. A sample Splunk deployment for this set up is below.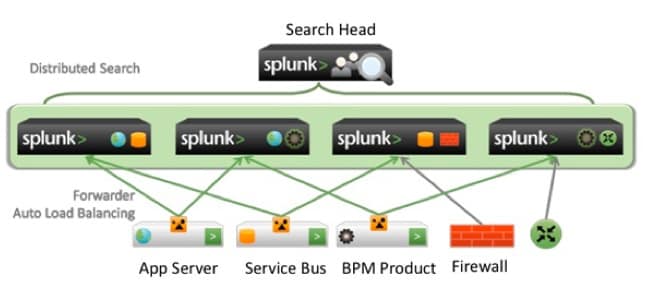
In this example, we have forwarders for an application server, a service bus, and a BPM product. This is just one example as a SOA tier could just as easily have been a web portal or MQ Series. For completeness, we also have Firewall data being forwarded. However, Splunk role base access can restrict what the developer can see and do. For instance, all application data can be put into a separate index called application and the developer can only search for data where index=application. Further restrictions such as originating host or sourcetype can also be applied to the role.
For one technical note, Splunk’s LWF are indeed light weight in that they purposely restrict the amount of network bandwidth they consume to send data to an indexer to a maximum default of 256 KBps. If you want to increase or decrease this maximum data rate, copy SPLUNK_HOME/etc/apps/SplunkLightForwarder/default/limits.conf to SPLUNK_HOME/etc/apps/SplunkLightForwarder/local and change the settings in limits.conf.
There, you have it. Software developers who are constantly called upon to troubleshoot issues in production systems and SOA deployment can go home earlier as they could have role based access to data in their area of expertise. To make this even further compelling, Splunk can also be used to monitor and alert on additions, changes, and deletions in the file system to speed up these types of investigations. This combination should help create IT Superheros.
*************************
On an administrative note, in the past, I have written blog entries on various topics such as using JavaMail with Splunk or correlating with database records. For these entries I provided links to examples and applications that covered the topics. These have all been moved to the new Splunk Community Apps page.