See how customers are using the AI Toolkit!
Splunk AI Toolkit
Run AgenticOps, foundation models, and predictive ML on Splunk
Run custom AI on the data that runs your business. No data movement, no separate stack.
Build agents on Splunk
Use Agent Builder to build and deploy governed, auditable agents on top of your data. Splunk data and tools accessible to agents through integration with knowledge bases, Splunk MCP server, and external MCP integrations.
Run GenAI inside Splunk Cloud
Run Splunk hosted models like Foundation AI Security, Cisco Deep Time Series, and GPT-OSS natively inside Splunk Cloud — no GPUs, no API keys, no data egress. Or use your third-party frontier models or self-host via Ollama.
Run ML on existing data
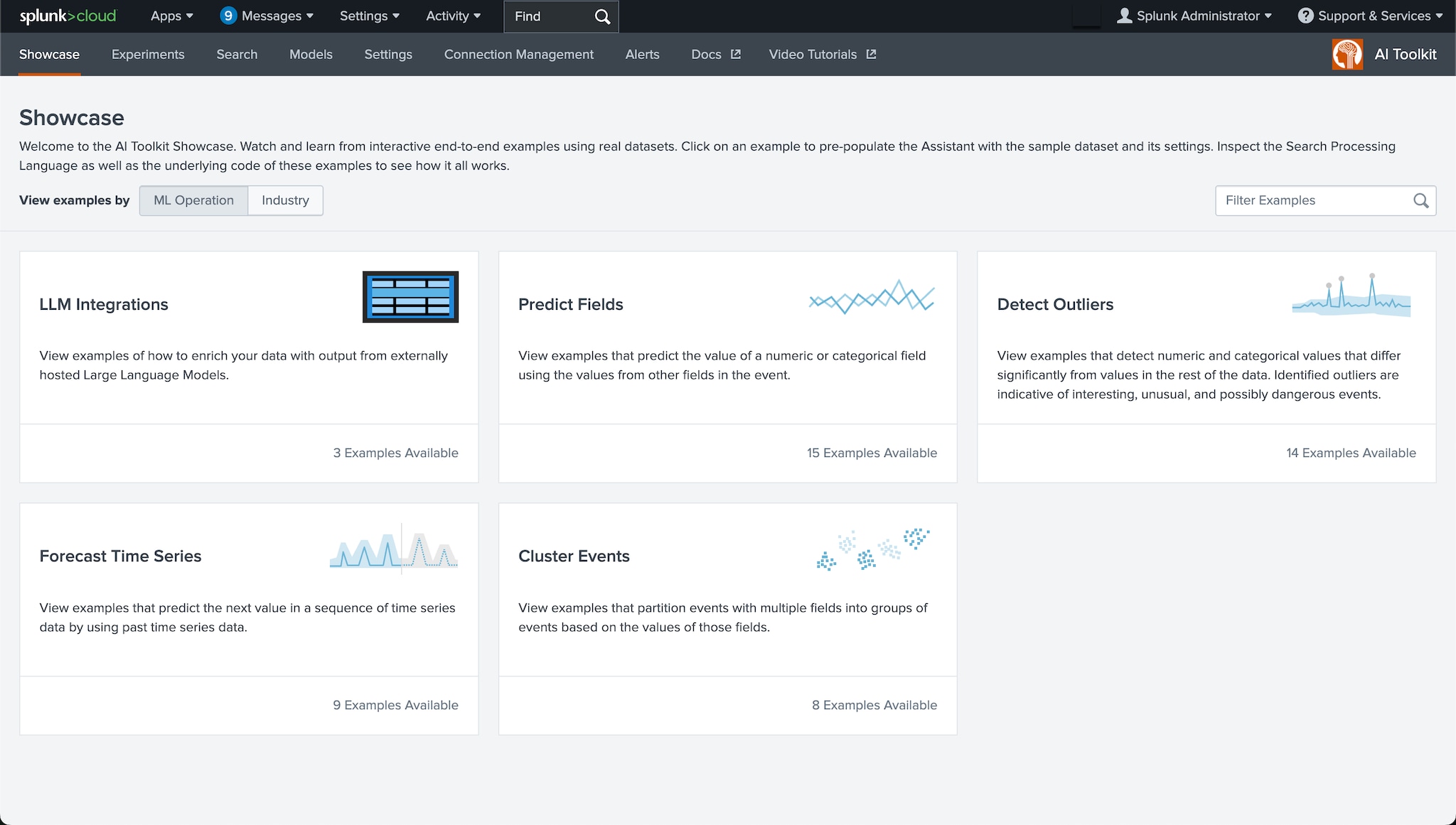
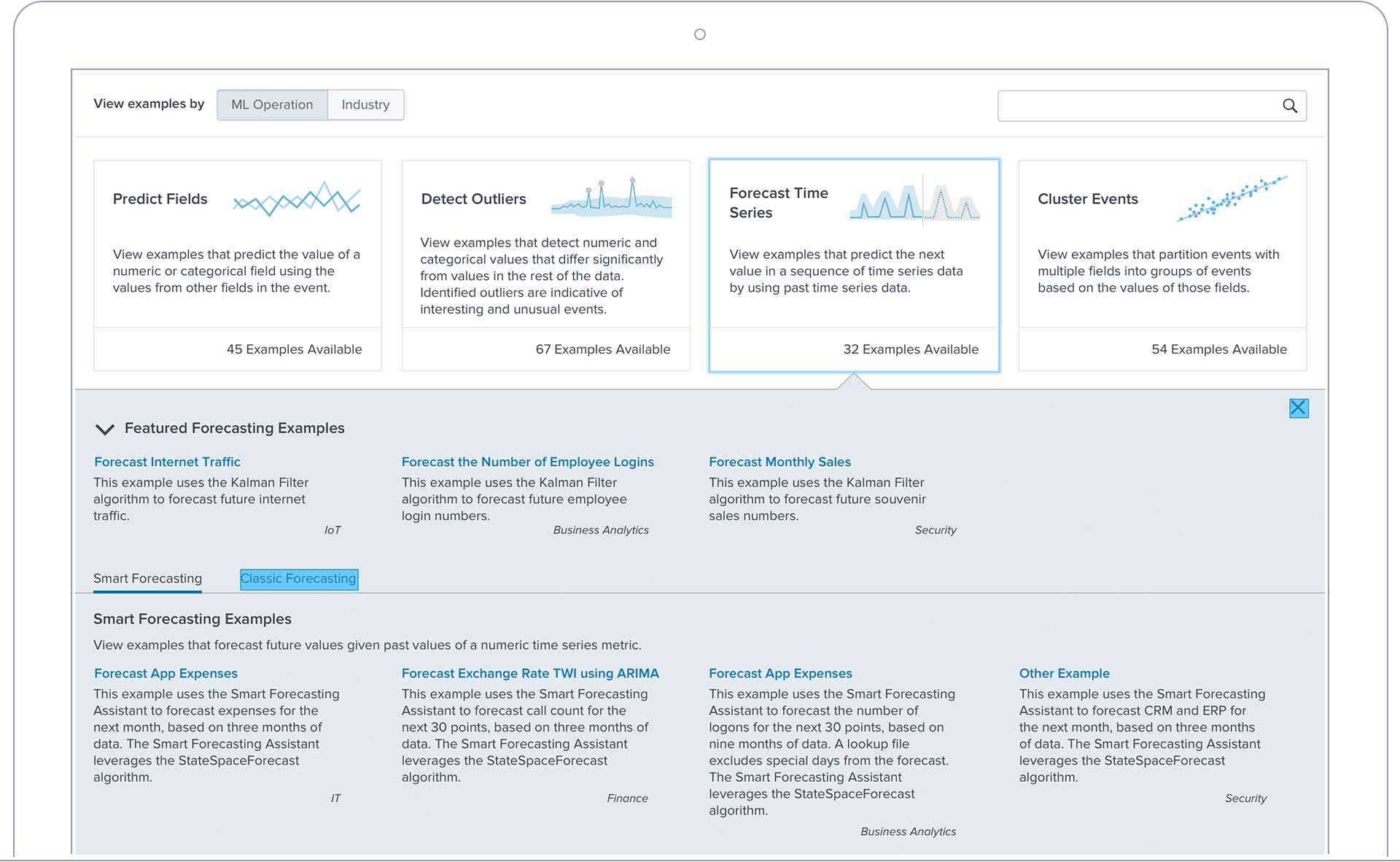
Build with hundreds of built-in ML algorithm templates or bring your own model with ONNX, SageMaker, and DSDL support. Smart Assistants guide non-data-scientists through forecasting, outlier detection, clustering, and prediction.
Features
Everything you need to build custom AI on Splunk
Save time using pre-built components.
Agent Builder
Use Agent Builder to create, test, and deploy RBAC-governed, auditable agents that use Splunk data and tools. Agents can reason with hosted models, ground decision in knowledge bases, and act through Splunk Platform and external MCP integrations.
Hosted Foundation Models
Generative AI models are hosted natively inside the Splunk Platform boundary. Use Foundation-Sec for security, Cisco Deep Time Series Model for forecasting and anomaly detection, GPT-OSS for general reasoning. No GPUs, no API keys, no data movement required.
External LLM Model Integration
Integrate any model, from frontier LLMs to custom ONNX and Amazon SageMaker builds, directly with Splunk Platform data. Use the AI Toolkit and DSDL as your inference and orchestration surface to keep existing model investments portable and scalable.
Custom ML Models
Build custom ML models using hundreds of built-in algorithms with guided and code-first workflows and multivariate support. Smart Assistants guide you through forecasting, outliers, clustering, and prediction.
Run ML and GenAI from SPL
Your models become first-class search commands across Splunk Cloud and Enterprise, and your existing dashboards, alerts, and reports continue to work unchanged.
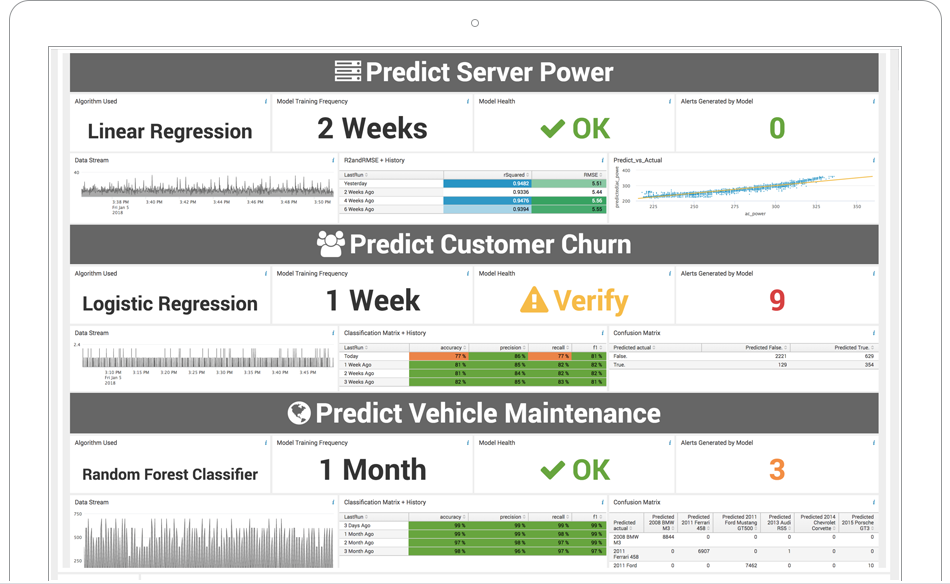
Spot the red flags with anomaly detection
Through intensive training, AI and machine learning establish baselines for your data and detect deviations from past behavior or atypicalities that might otherwise go undetected. See how the National Ignition Facility identifies atypical behavior as it monitors the U.S. nuclear stockpile.
See the unseen in your data with clustering
There are patterns in your data that human analysts will miss: trends in ITOps and in security, and patterns in customer behaviors that suggest new markets and opportunities. Automate analysis of clusters to identify and group similar data points to help you see the signals in the noise, and make better decisions. See how pharma startup Recursion identifies high-value patterns in large sets of genetic research data.
AI Toolkit FAQ's
The Splunk AI Toolkit is for everyone — from novice analysts to expert ML engineers. It provides a scalable environment to build, test, and operationalize AI:
- For security and observability, analysts: Use no-code features like Agent Builder to automate repetitive workflows and build AI agents without prior ML expertise.
- For ITOps and SREs: Use Smart Assistants to easily detect outliers, forecast system capacity, and cluster events to reduce noise.
- For data scientists and ML engineers: Use ML-SPL commands and DSDL containers to build and deploy custom models, or integrate frontier LLMs directly into your search pipelines.
Whether you are using guided assistants or orchestrating complex GenAI workflows, your models remain portable and integrated into your existing Splunk dashboards and alerts.
Splunk Machine Learning Toolkit was renamed to the Splunk AI Toolkit in version 5.6.3, and now AI Toolkit has more capabilities. All capabilities from MLTK, including Smart Assistants, ML-SPL commands, and the algorithm library, remain in AI Toolkit. New capabilities include hosted foundation models, RAG, knowledge bases, and MCP server support.
AI Toolkit runs on both Splunk Cloud Platform and Splunk Enterprise. Splunk-hosted foundation models are available on Splunk Cloud Platform only.
Download AI Toolkit from Splunkbase.