Agentic observability for the new speed of business
AI-driven detection
Automatically detect issues
Anticipate system failures, bottlenecks, and performance degradation and configure detectors to prevent customer-impacting incidents from occurring.
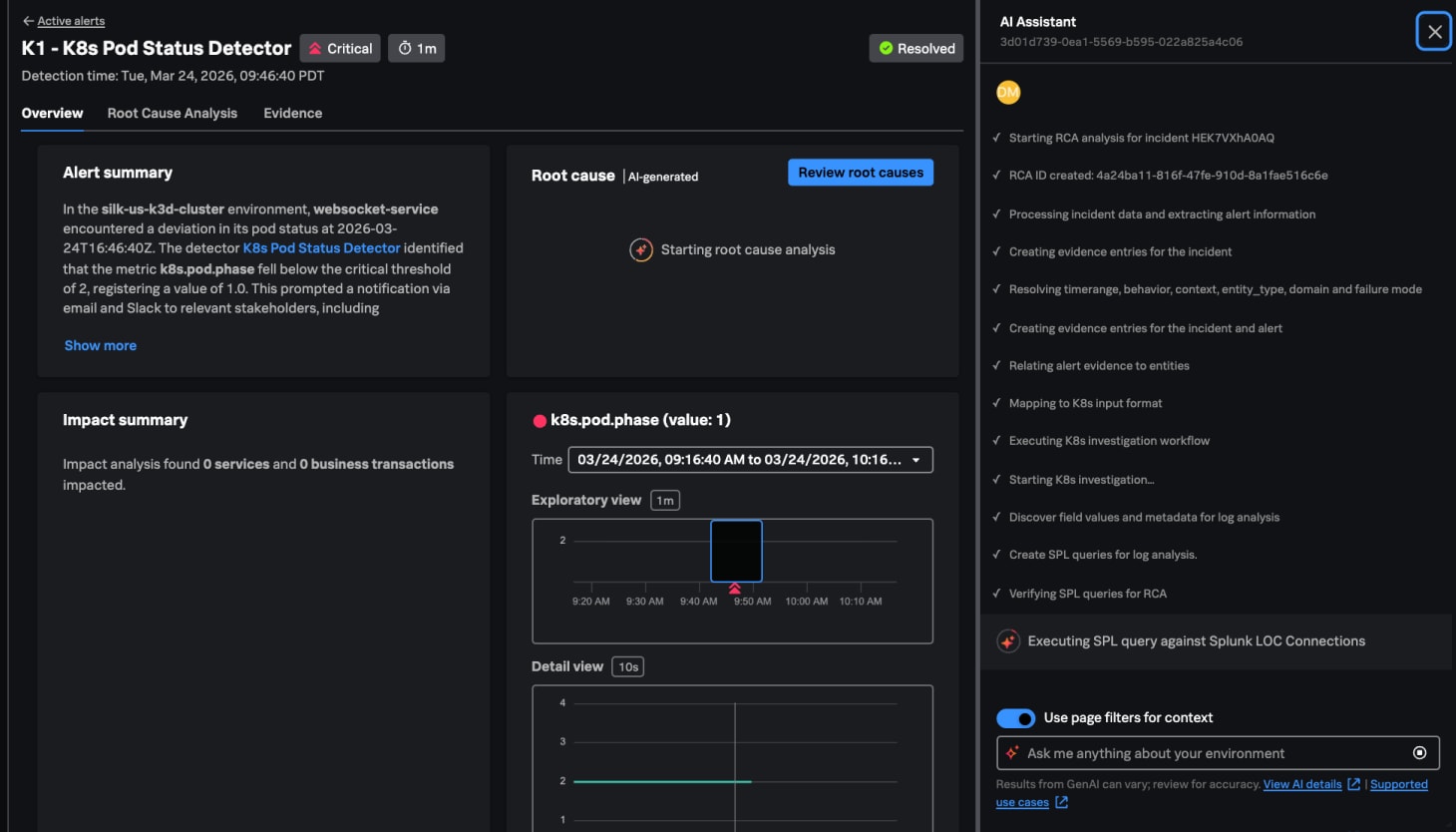
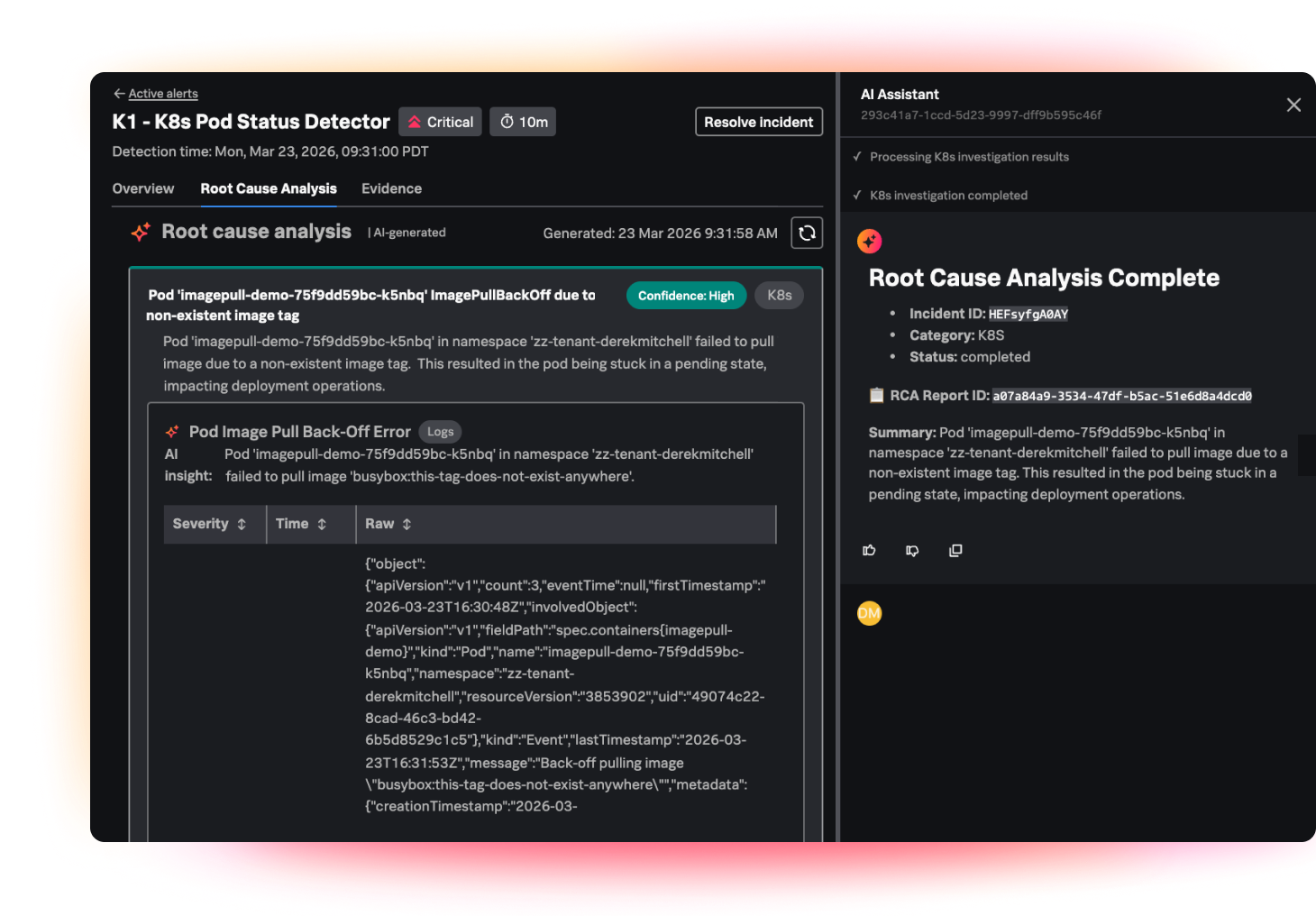
AI troubleshooting agent
Let our agent troubleshoot for you
The AI troubleshooting agent automatically sifts through all metrics, log, and trace data, identifying whether your application or infrastructure is at fault, and surfacing the most likely root causes — all in plain language, within your existing workflow.
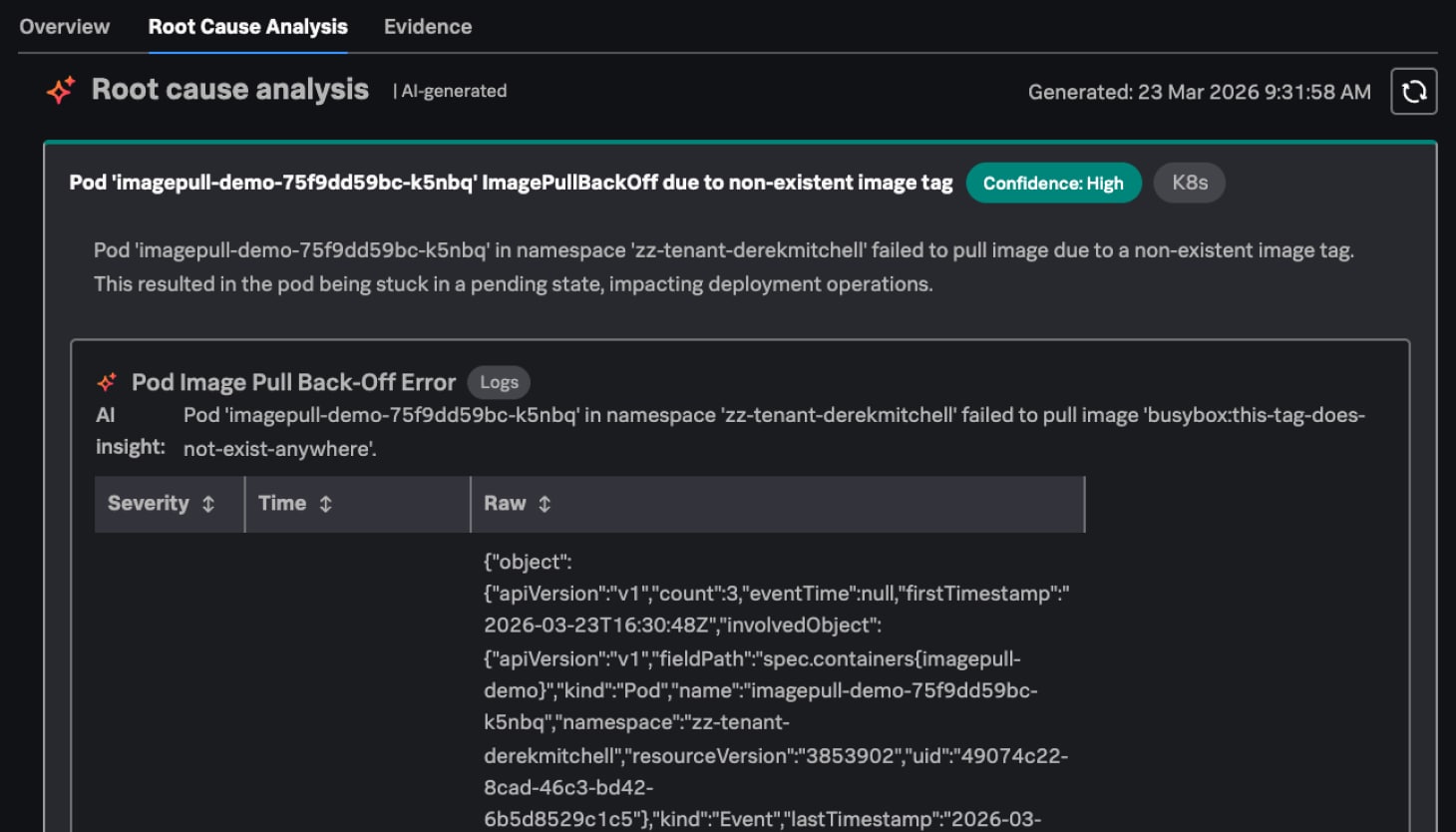
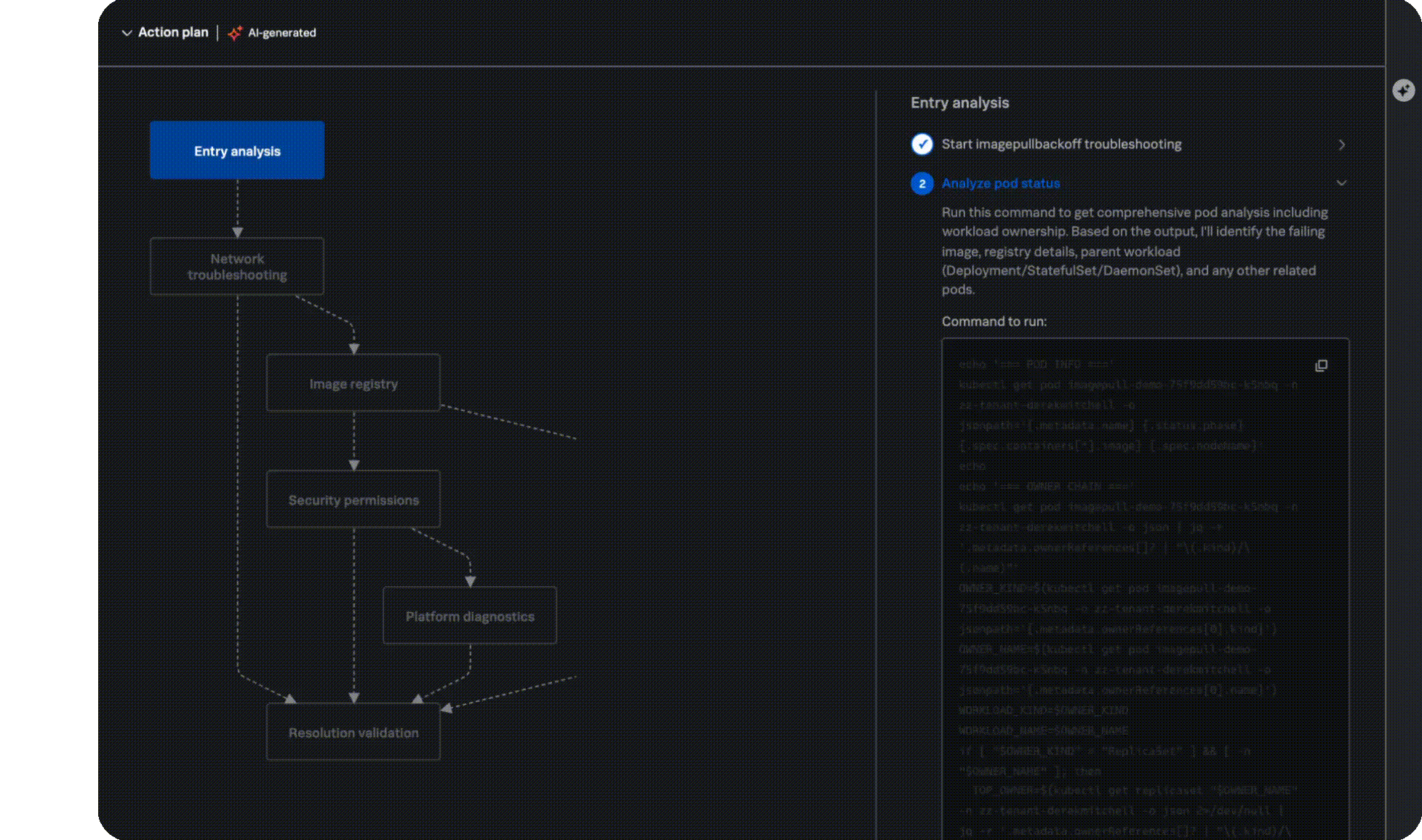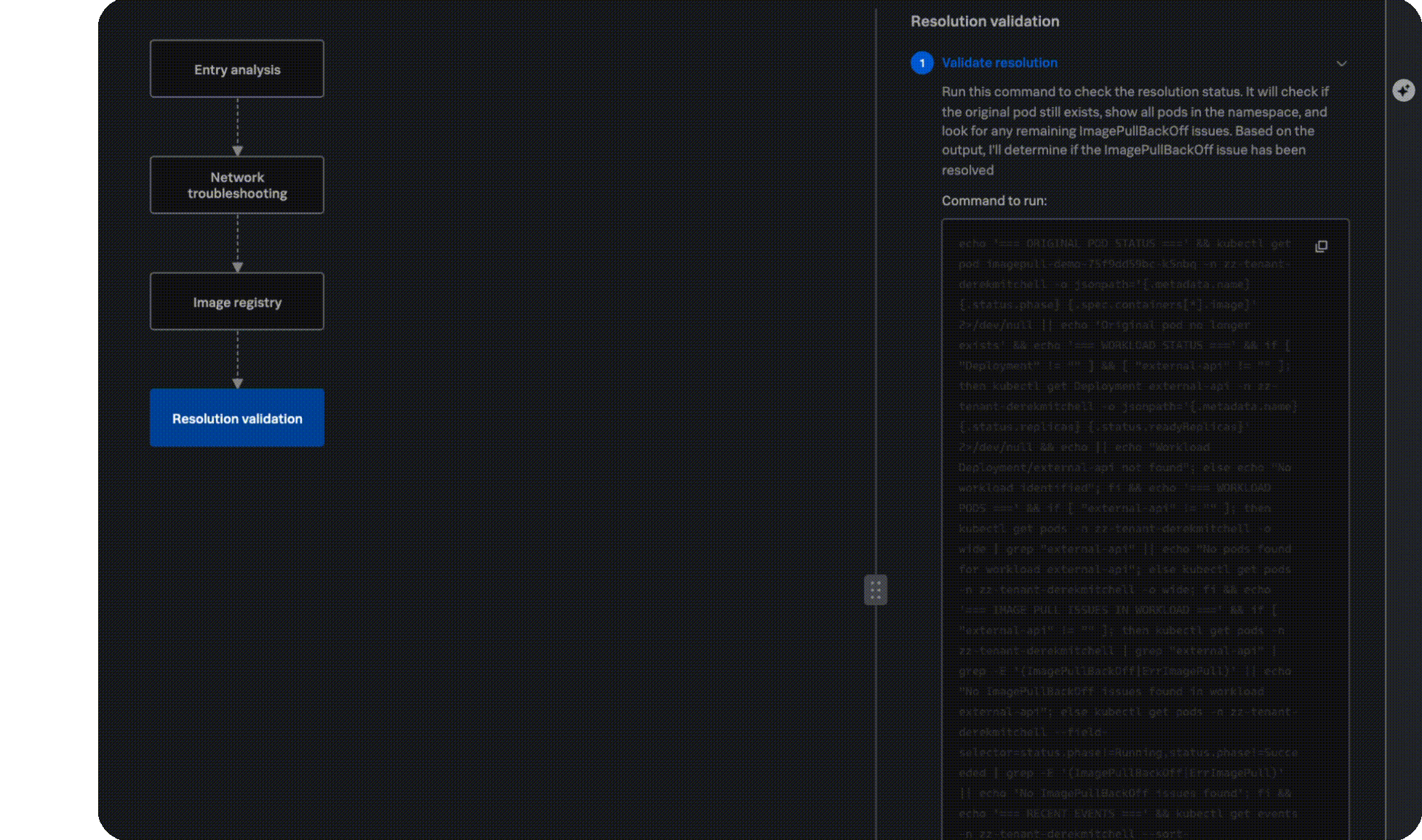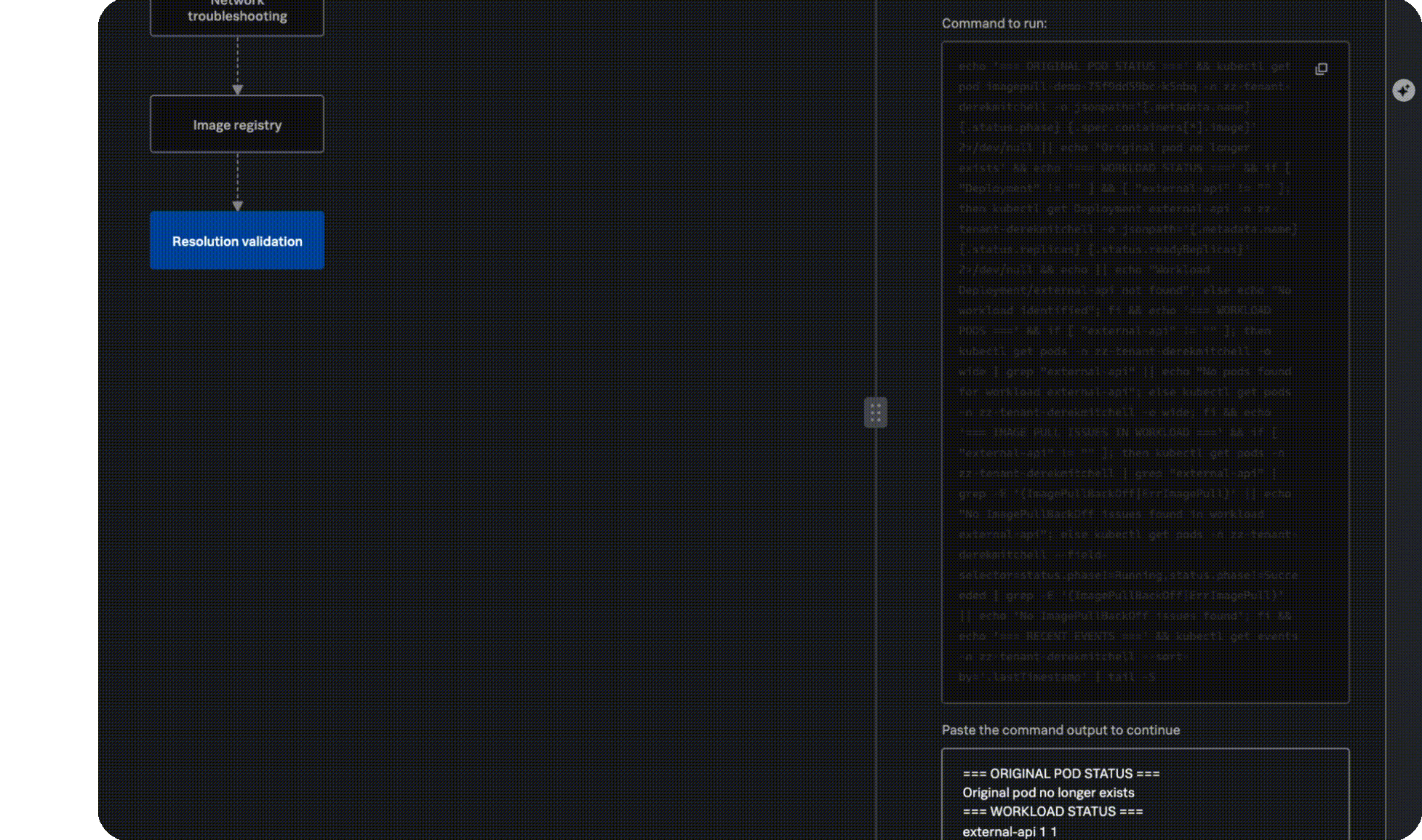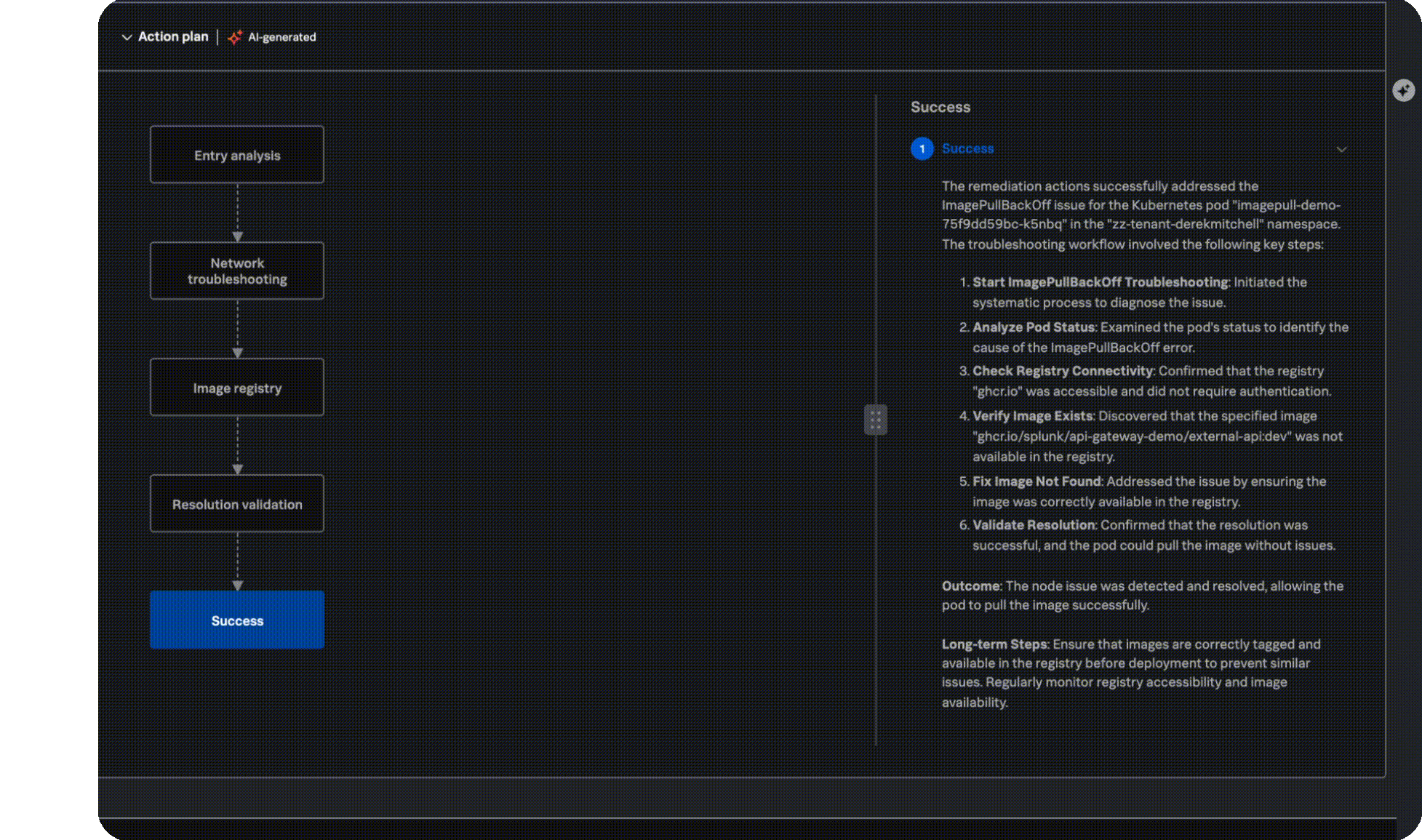
Remediation plan
Get to resolution faster
Stop context switching across multiple screens, tabs, and tools and manually reviewing tons of documentation, and instead get a ranked list of probable causes, clear impact analysis, and actionable recommendations, right when and where you need it.
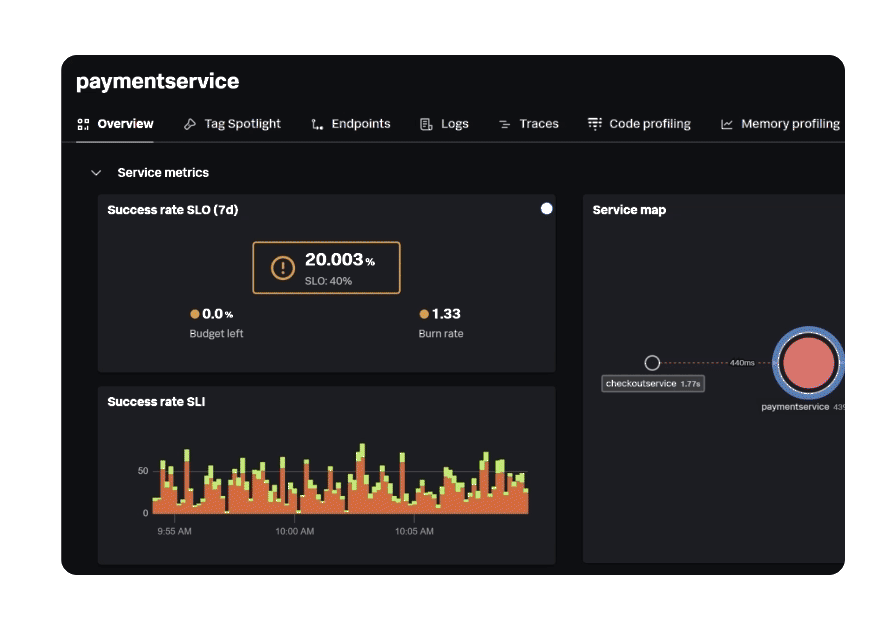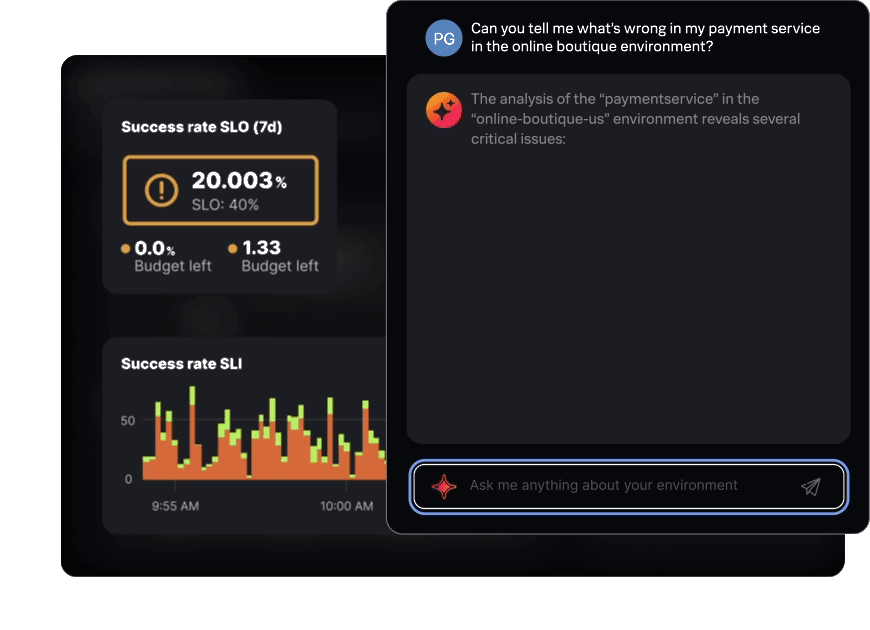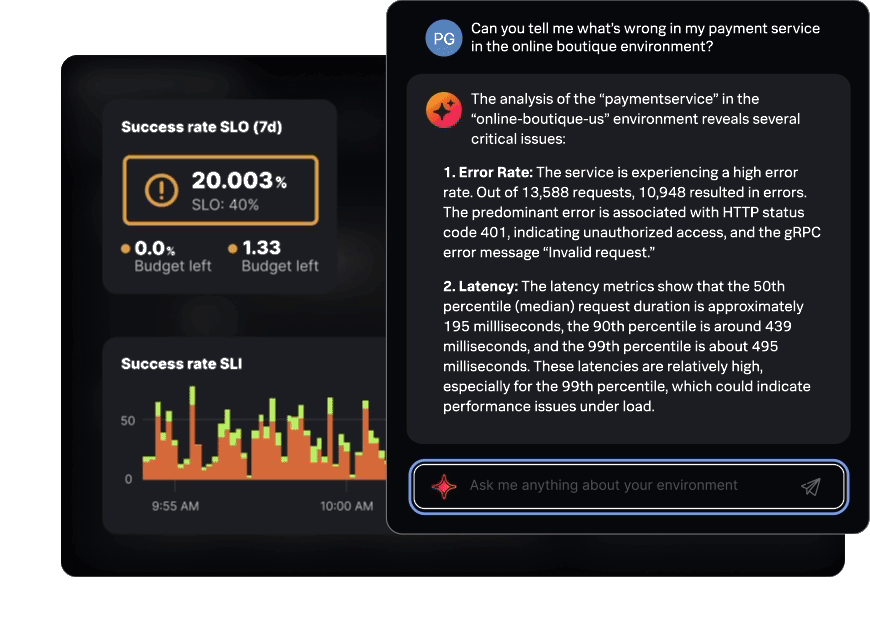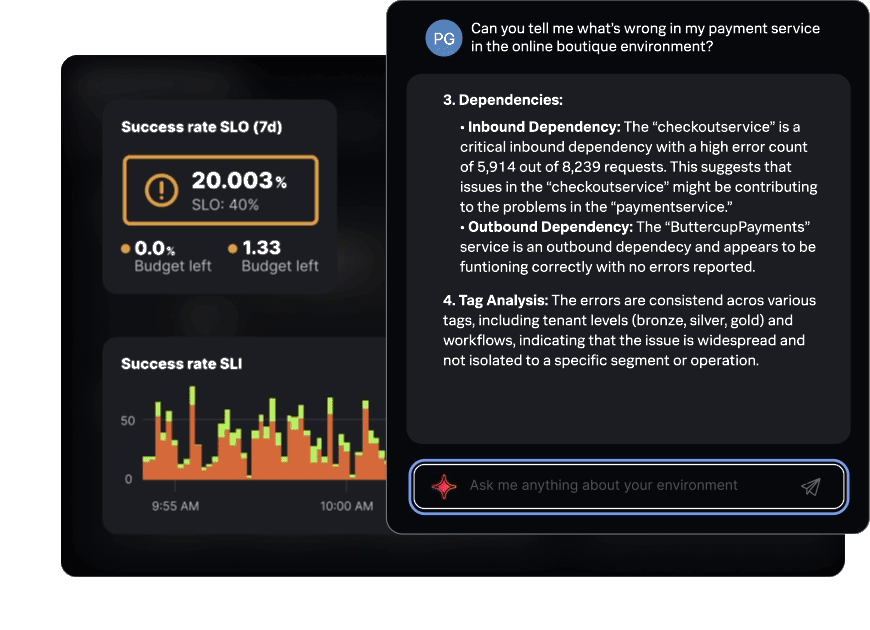
AI Assistant in Observability Cloud
Get insights and answers in plain English
Easily extract insights from Observability Cloud and accelerate investigations using natural language. If you need more help, just ask the AI assistant.

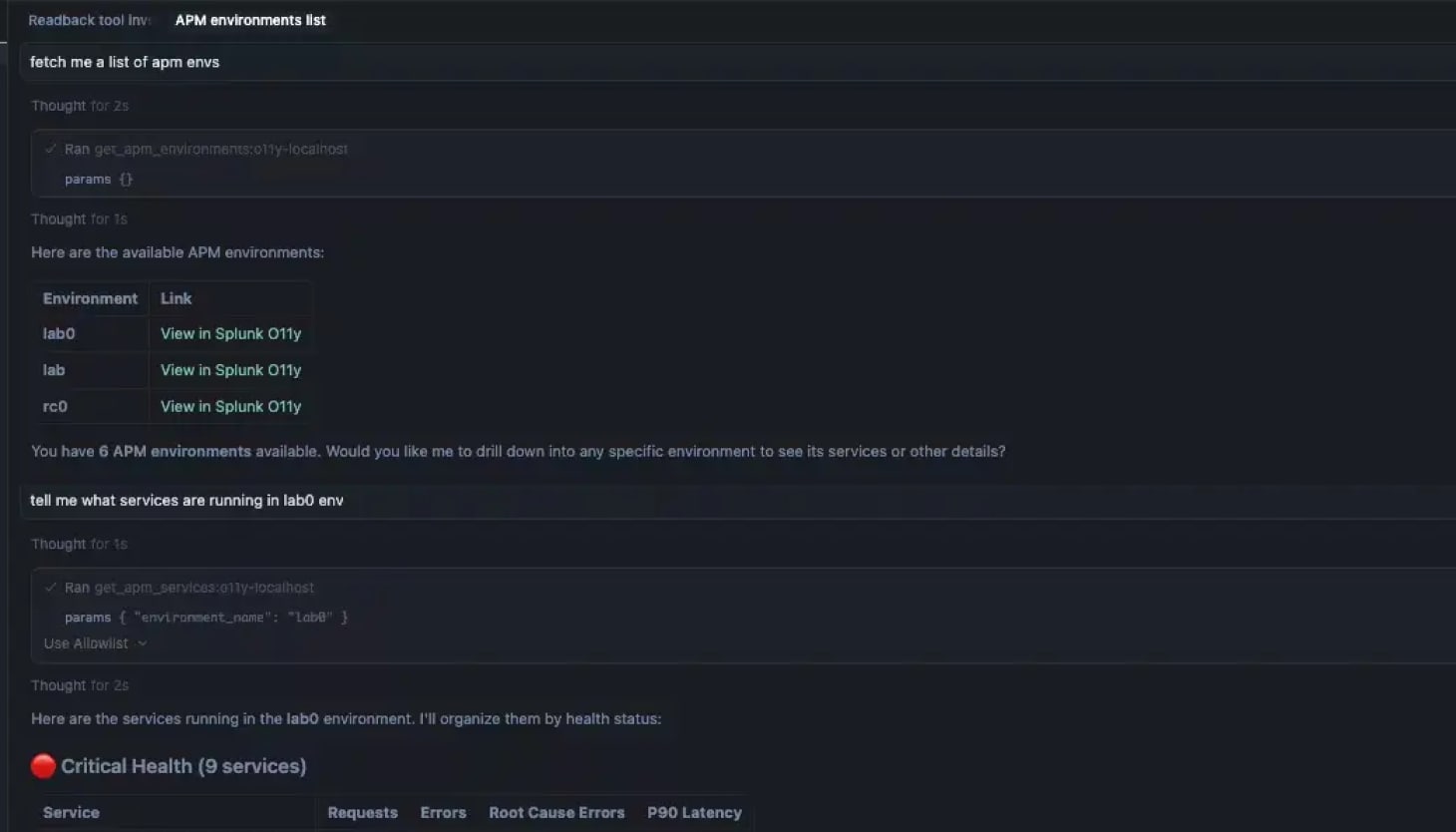
Splunk MCP Server & agentic AI
Use Splunk capabilities in one unified MCP server
Leverage a secure interface to connect your local AI agents, LLMs, tools, and data with Observability Cloud data to build custom AI workflows and debug performance issues in production without leaving your environment.