
Use search, analysis and visualization for actionable insights from all of your data.
OVERVIEW
What it is
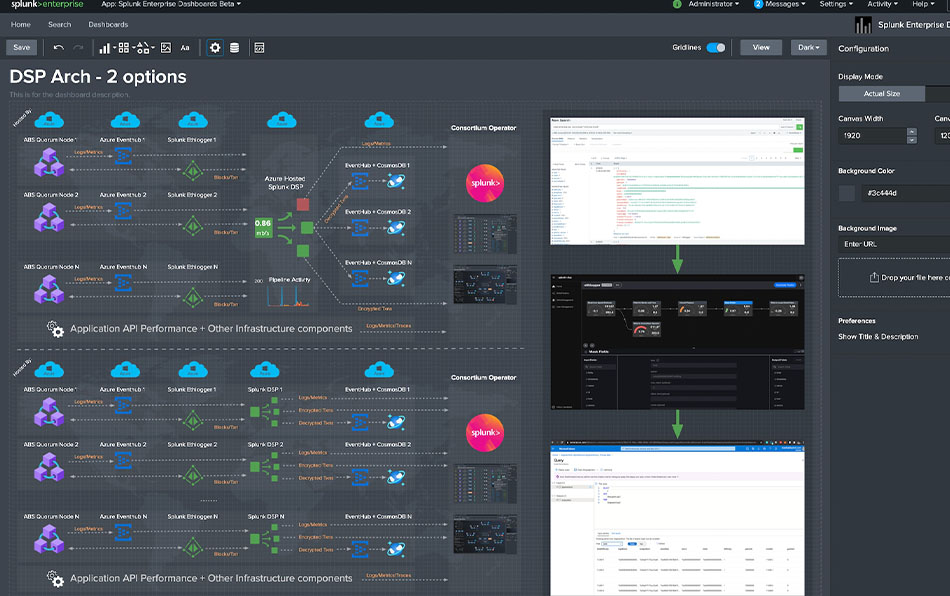
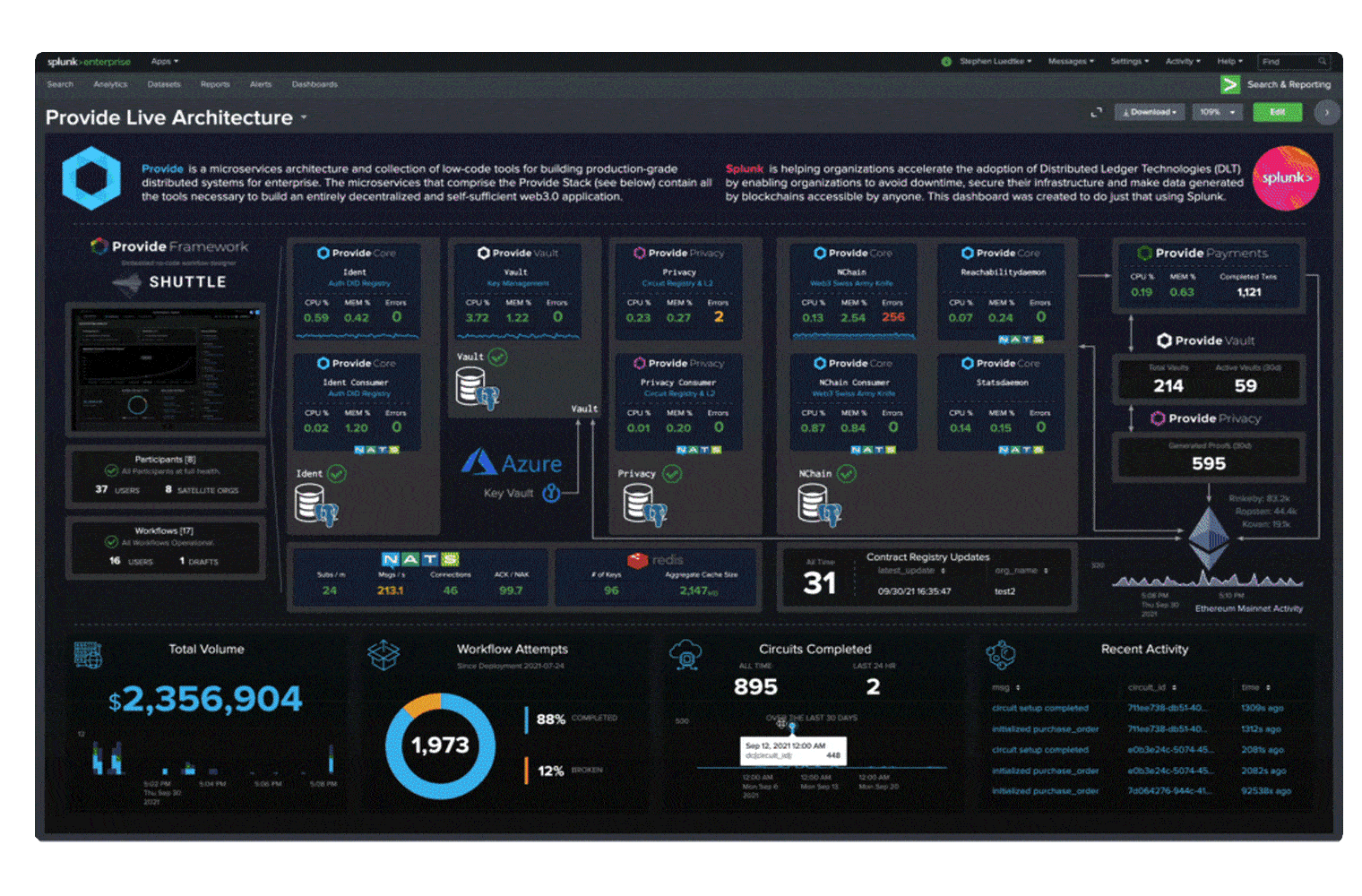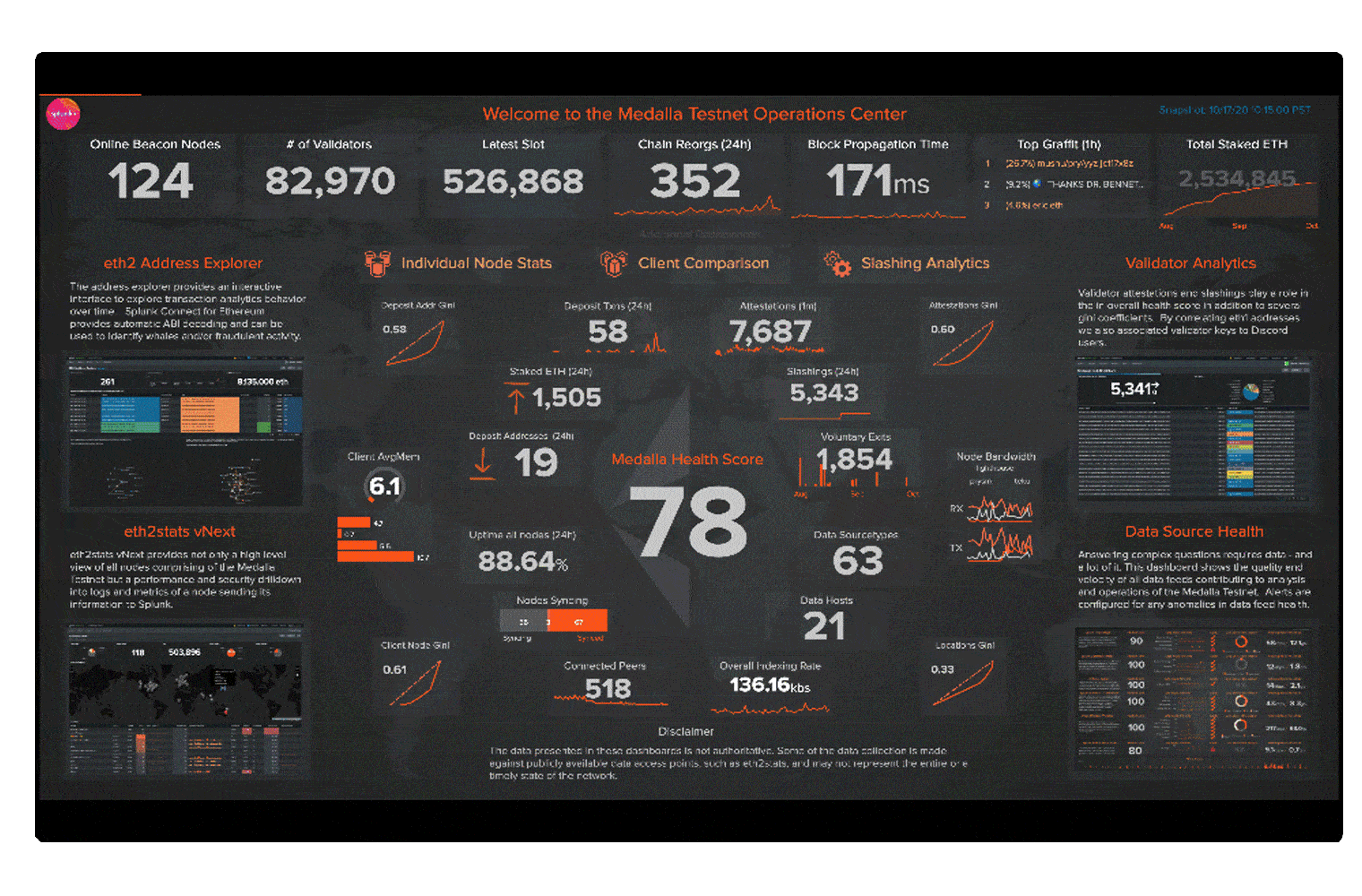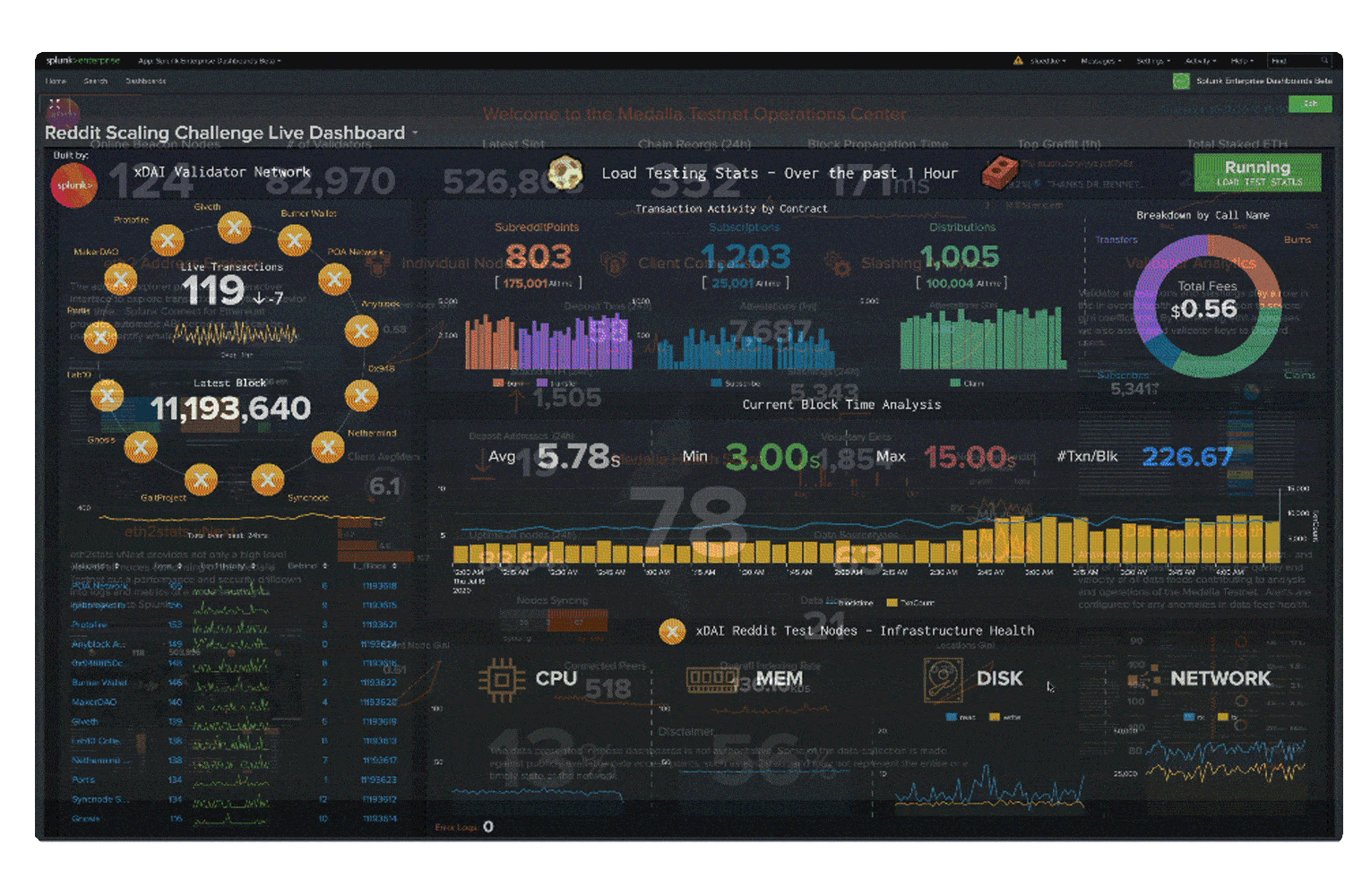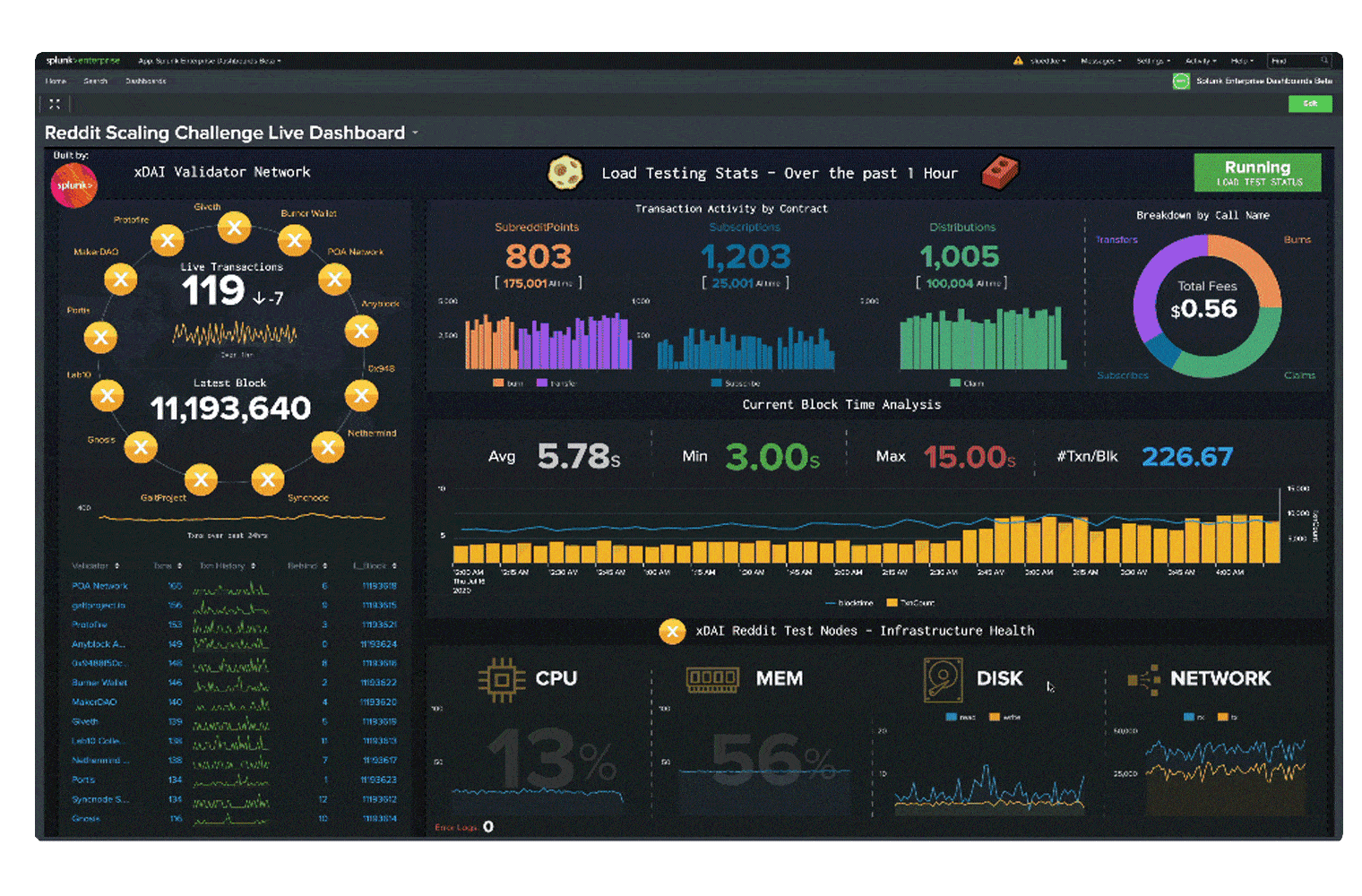
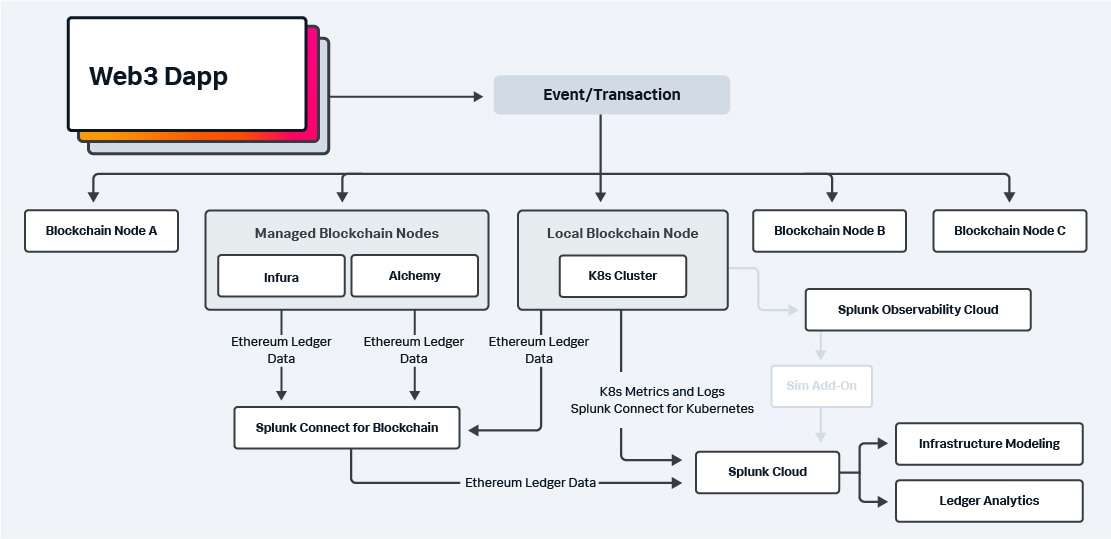
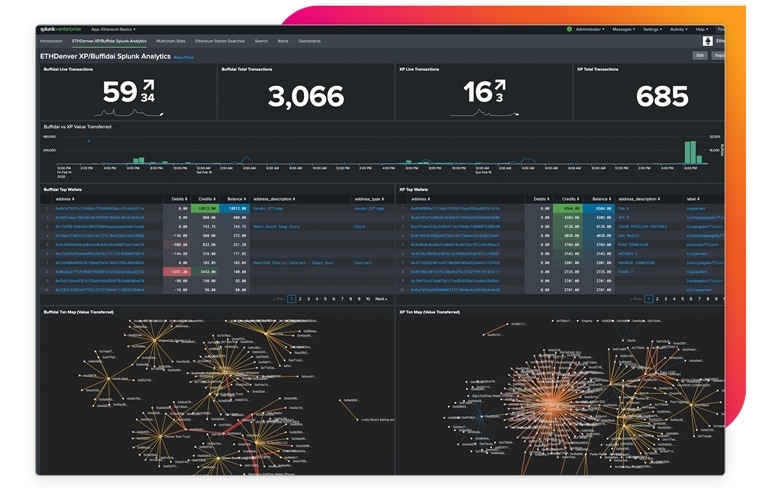
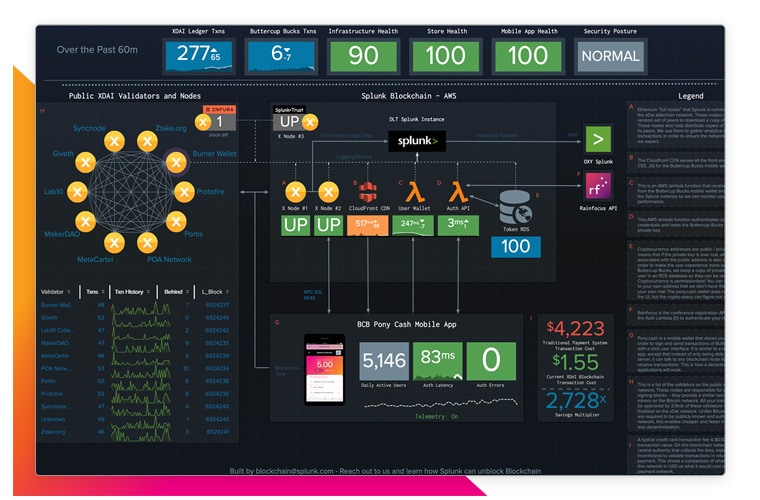
Blockchain applications and infrastructure generate lots of data in new formats. Splunk makes it easy to ingest and gain insights from this data, while monitoring the infrastructure to provide business insights on blockchain network transactions.
Why it matters
Blockchain eliminates the need for third-party validation of transactions while ensuring they are secure, reliable and tamper-proof. This decentralizes the data and distributes it across peer-to-peer networks.
Where it's going
As the world becomes more digital every day, it is increasingly clear that transactions, contracts and even physical objects of any substantial value will be represented digitally on blockchain networks.