
Downtime costs you
Learn about the costs of downtime — and how to avoid it. Get the free report.

Key takeaways
Every company has a lot of competitors, each trying to outdo the others. Doesn’t it feel like a race? That’s because it is. To stay ahead, providing faster and more reliable services to customers is essential. Due to this reason, most organizations must pay attention to designing and building highly available systems.
Let’s consider some interesting stats from a Transparency Market Research report. As per the report market value for high-availability servers is projected to increase with a compound annual growth rate of 11.7% from 2017 to 2025. This growing demand clearly suggests that any company wanting to remain competitive in the market should have a good understanding of IT and system high availability.
In this blog post, we will cover what availability is, how to measure availability vs. high availability, some techniques, challenges, and more.
Splunk IT Service Intelligence (ITSI) is an AIOps, analytics and IT management solution that helps teams predict incidents before they impact customers.

Using AI and machine learning, ITSI correlates data collected from monitoring sources and delivers a single live view of relevant IT and business services, reducing alert noise and proactively preventing outages.
Availability is the ability of systems and services to function and be accessible when needed. It shows how well a system can recover from problems and keep running smoothly.
It is a key measure in IT management. IT management is about overseeing and coordinating an organization's technology resources and availability indicates how reliably systems and services can support day-to-day operations.
Availability is often measured as the percentage of uptime over a specific period. A service usually mentions its availability in its service level agreement.
Organizations can improve system availability through various strategies. It's important to follow these as best practices as they help to increase customer trust and minimize revenue loss.
High availability is defined as the system's ability to remain accessible nearly all the time (99.99% or higher) with minimal or no downtime. This is considered as a sub-set of availability where it tries to achieve the highest possible level of availability.
While high-availability systems are not entirely immune to failures, they are designed to respond to requests as consistently as possible, even during challenging conditions. It is important to note that high availability does not measure the speed or quality of the system's output but focuses solely on its ability to remain available to users.
High availability is highly important for business-critical systems (e.g.: ERPs, e-commerce platforms, financial applications) that require them to remain operational all the time.
High availability uses technologies and practices, such as failover clusters and distributed cloud architectures, to deliver consistent uptime. It's always beneficial to have knowledge of these tips so you can apply them practically in the real world.
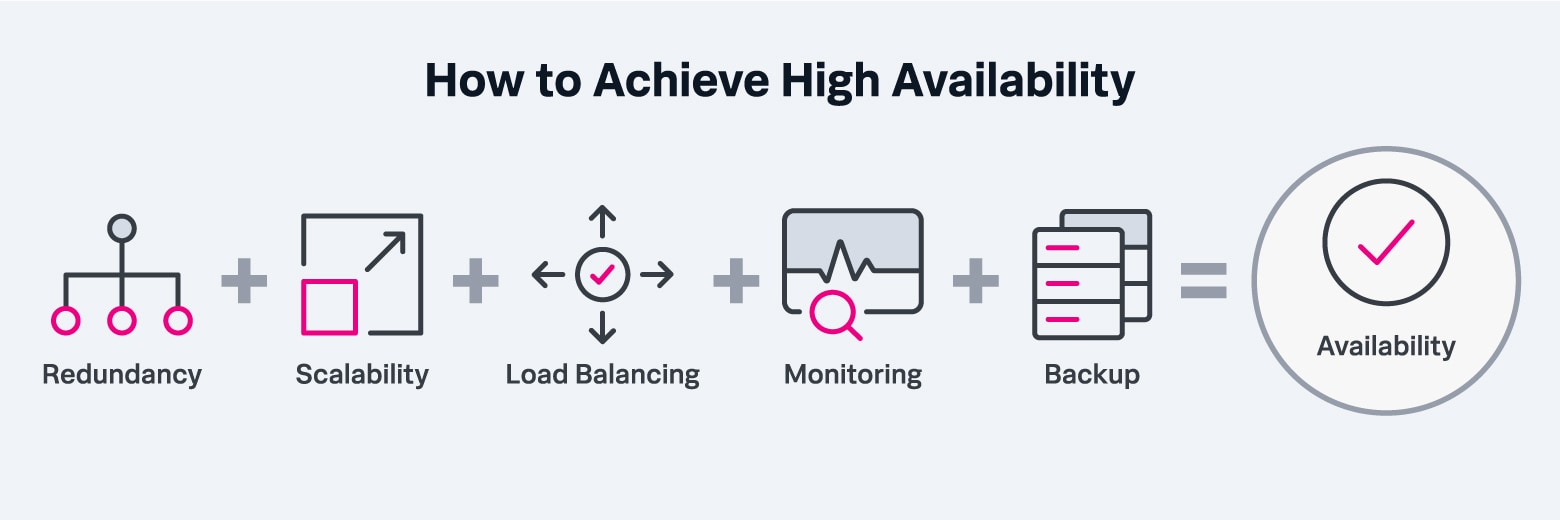
Achieving high availability does not require dozens of tools. Splunk can help you do it easily, while minimizing tool sprawl: see how.
Availability or high availability can be measured as a percentage or uptime metric.
Availability/High Availability = Total Service Time – Downtime / Total Service Time
For example, let's consider an electronic disaster management system that alerts sudden earthquakes for a country. If this system faces two hours of downtime during a certain time in the day, its availability score will drop to 91.7%.
From this number, it’s clear that it has a significant gap for improvement. As we all know it's highly dangerous for a system like this to go offline even for a few hours because it can cause life-threatening incidents. Usually, high availability systems target to have this number in around 99.9% which is the industry standard.
Clustering is one of the most used methods to create highly available systems. In clustering your system will be spread across multiple nodes. Organizations can decide how many nodes they are going to have in their architecture.
A cluster setup can distribute the workload it gets among these multiple nodes. So that if one server unexpectedly goes down or purposely shuts down for some maintenance another server in the cluster setup will automatically take over the responsibility to handle operations.
Clustering can be used for on-premises products as well as for cloud-based solutions. Certain cloud providers like Azure and AWS also provide built-in clustering solutions. With these solutions, systems can dynamically scale catering to increasing user demands and maintaining high availability.
(Related reading: cloud monitoring.)
High availability and fault tolerance work in slightly different ways. High availability prioritizes minimizing downtime with quick recovery mechanisms and fault tolerance goes further to provide uninterrupted operation even during a failure.
One key difference is in how they handle failures. High availability systems rely on techniques like failover and clustering to quickly recover and keep services running. In contrast, fault-tolerant systems are built to avoid interruptions entirely, using active redundancy. Technologies such as RAID for data storage, replication protocols, and fault-tolerant servers like Stratus or HPE NonStop are commonly used to create systems that can handle failures without any visible impact.
High-availability systems are typically simpler and more cost-effective. Fault tolerance, however, involves more complex setups. Their architectures include continuous replication, error containment mechanisms, and dedicated fault detection tools, which make it more resource-intensive but highly reliable for critical systems where downtime is not an option.
Availability monitoring is the process carried out to continuously observe the status of a system to guarantee that it functions as expected. Whether these systems are on-premises or cloud-based, monitoring tools periodically check system uptime and responsiveness.
Availability monitoring is widely used in critical systems such as:
For example, businesses like Amazon or Facebook rely heavily on availability monitoring to prevent outages. Beyond simple checks, advanced monitoring can be used to test service accessibility from different locations, analyze response times, and identify the root causes of failures.
You can use one of the tools like Pingdom, SolarWinds, and Datadog to implement availability monitoring. With these tools, it is very easy to obtain real-time alerts, analytics, and global performance data.
Organizations can gain a lot of benefits by implementing availability monitoring. Some of these benefits are:
Availability monitoring consists of six key components. These components work together to monitor uptime, performance, and overall service health.
IT environments are becoming more complex. Especially with hybrid cloud setups, it can be difficult to track all system components effectively. Also, monitoring tools can generate large volumes of data by creating alert fatigue for IT teams. Moreover, it requires significant effort and expertise to maintain accurate and meaningful metrics across diverse systems and services.
Managing diverse platforms and tools. Enterprises often rely on multiple monitoring systems for specific network components. This can lead to inefficiency due to different formats and logins by creating a situation called a "swivel chair" activity. Also, multiple tools can generate excessive false-positive alerts.
Geographic distribution adds another layer of complexity. With servers and devices spread across multiple locations and time zones, it becomes difficult to achieve a unified view of system performance.
"Five 9s" refers to a system's availability of 99.999%. This means that a system is up, and it runs almost all the time with its downtime limited to about 5 minutes and 25 minutes in an entire year.
This metric is considered the gold standard for reliability in IT which represents near-continuous uptime. Achieving five 9s guarantees that systems are robust and capable of handling failures with minimal disruption.
The jump from one 9 (90%) to five 9s (99.999%) represents significant improvements to reduce downtime. For instance, while 99% availability calculates to about 87.6 hours of downtime annually, five 9s reduce this to mere minutes.
To achieve this level of availability it requires advanced infrastructure e.g.: failover mechanisms, redundancy, proactive maintenance as even small inefficiencies or disruptions can quickly add up and compromise the target uptime.
Five 9s is essential for services where downtime can have serious consequences. This is useful in areas like emergency response systems or financial transaction platforms. For example, emergency medical services cannot afford interruptions, as delays could result in life-threatening consequences.
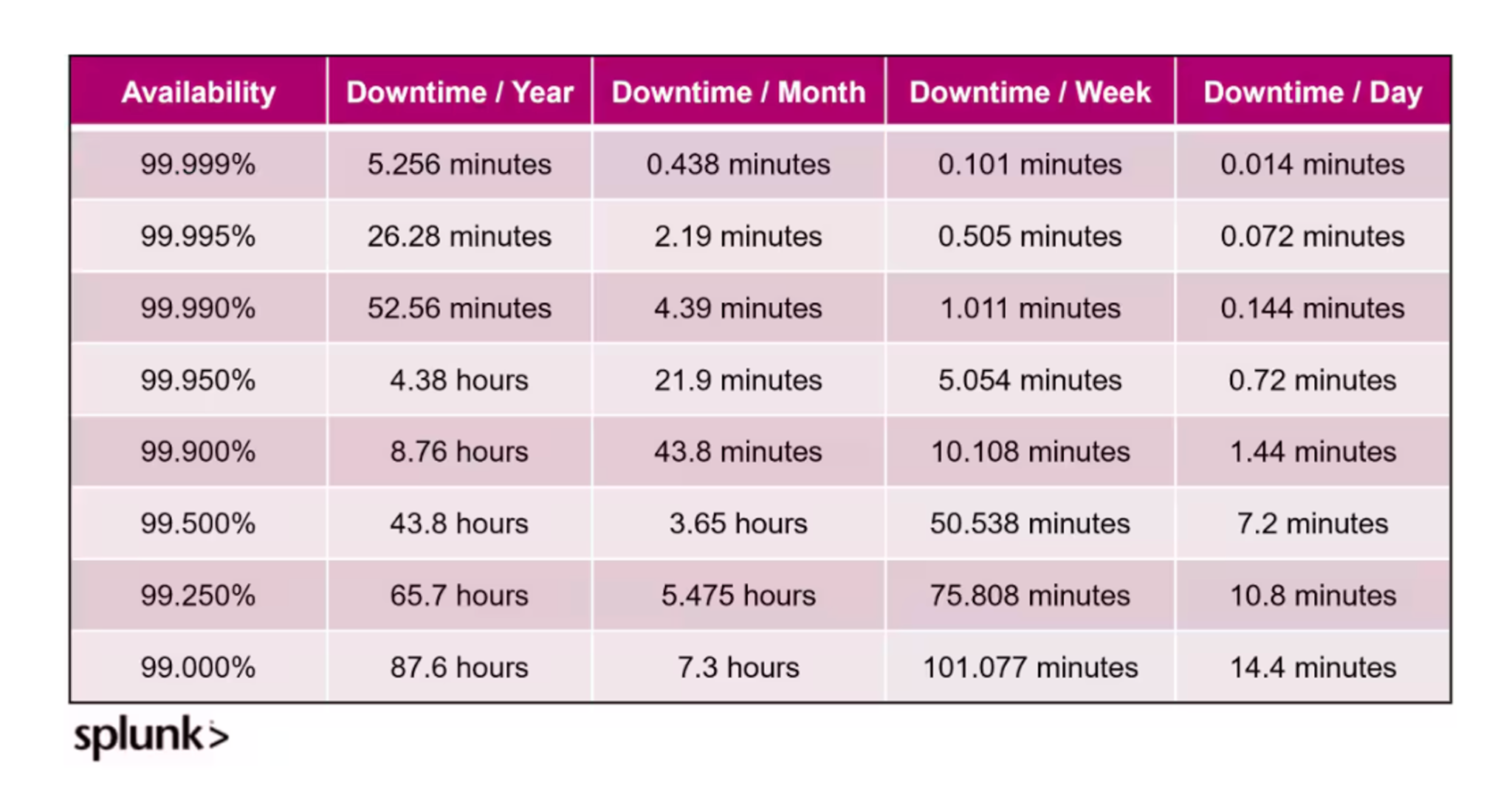
For instance, 99.9% availability with three 9s calculates to about 8.76 hours of downtime annually, while 99.999% which has five 9s reduces downtime to over 5 minutes per year. This difference shows why organizations are interested in higher availability.
Availability and downtime are two opposite aspects of system performance. As explained above availability is defined as the percentage of time a system is up and running. Downtime represents the periods when it is not accessible.
In simple terms, higher availability means less downtime. It is important to achieve minimal downtime to meet both customer expectations and business goals.
Downtime can occur for various reasons:
Some previously decided downtimes are planned to keep systems secure and updated while unplanned downtimes can have significant consequences.
For example, in industries like e-commerce, even a few minutes of downtime can lead to massive revenue losses — an average of $9,000 per minute or $540,000 per hour. This is easily notable in e-commerce companies (e.g.: Amazon) where an hour of downtime could cost your business so much.
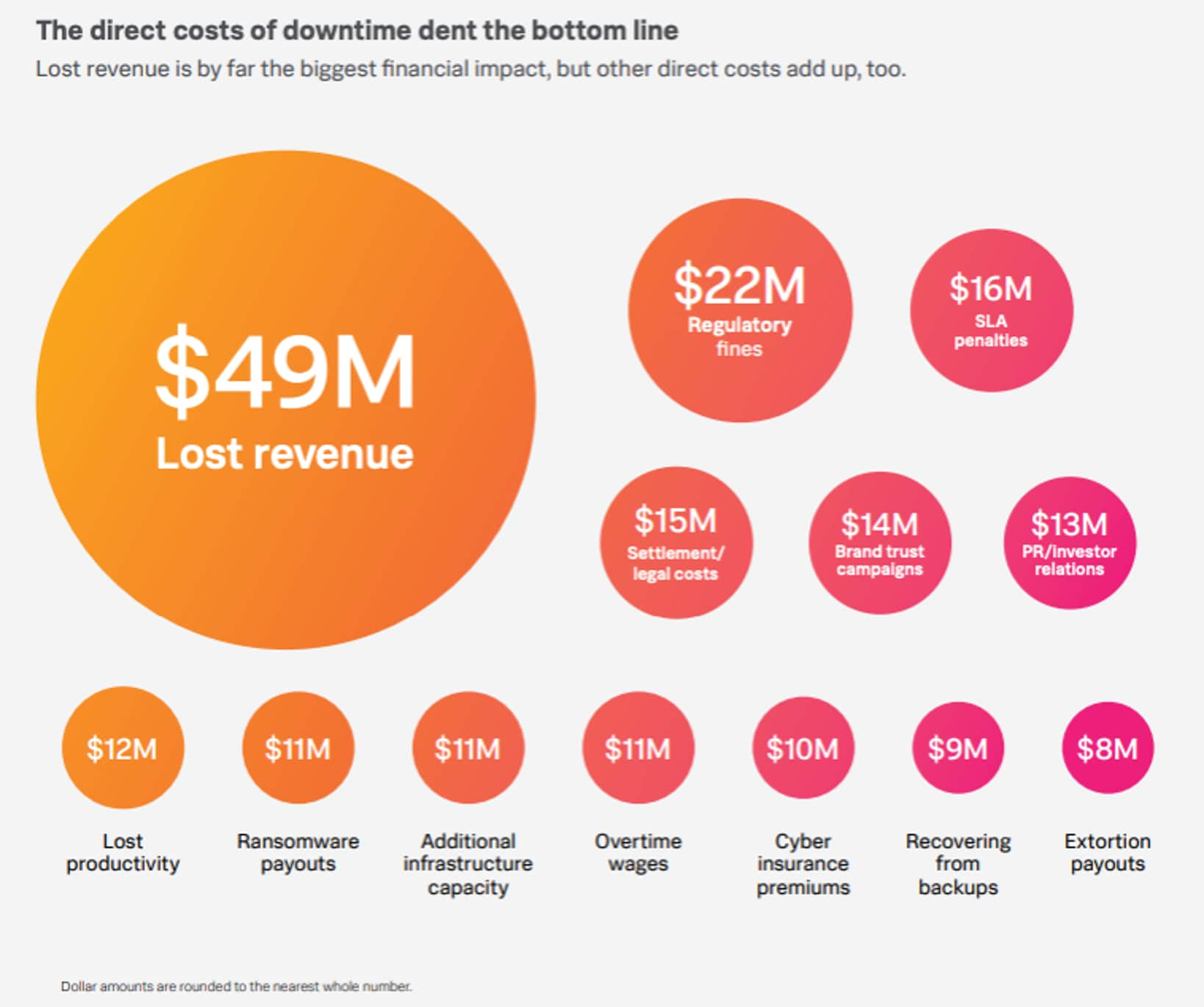
What’s behind the $9,000 lost per minute of downtime? Lost revenue tops the list of direct costs.
(Check out The Hidden Costs of Downtime.)
Downtime carries significant financial and reputational costs that often go unnoticed. While lost revenue is an obvious impact, there are many hidden costs that impact organizations. These costs affect productivity, customer trust, and long-term growth. These hidden costs show why businesses need to prioritize strategies to minimize downtime.
Availability management is the process of managing IT systems, services, and applications to deliver the agreed level of performance and uptime that customers expect. It involves proactive planning, monitoring, and managing risks to prevent service disruptions, as well as troubleshooting and improving systems to maintain optimal performance.
Availability management and availability monitoring are closely related but serve different purposes. Availability monitoring is a subset of availability management. In contrast, availability management encompasses a broader scope.
Availability monitoring provides the real-time data and alerts needed to identify potential issues, which are then used by availability management to plan proactive measures. Together, they create a continuous cycle where monitoring helps to provide the required knowledge to create management strategies to meet performance and uptime goals.
businesses use various technological methods as part of availability management. These methods are important to build resilient systems. Below are some of the most effective approaches.
Design systems with isolated functional components to limit the impact of localized failures and to prevent failures from spreading. For example, isolating database operations from application logic.
Use automation to restart or reprovision failed instances and reroute traffic to maintain uninterrupted service. For example, a cloud server can automatically restart if it detects a crash.
Automate processes like backups, patching, and recovery to reduce response time and improve system reliability. For example, scheduling nightly automated backups.
Regularly perform stress tests and simulate failures to evaluate system robustness and refine response strategies. For example, using chaos engineering tools like Chaos Monkey to intentionally shut down services tests how well a system handles unexpected disruptions.
We all know about Black Friday deals. It’s a common habit for every one of us to do a lot of online shopping during that season. During this period, websites face a large spike in traffic because a lot of users are trying to make purchases simultaneously. If the system is not designed for high availability, it could crash under the load. This means the company is going to lose a lot of sales and probably frustrate their customers, who won’t come back to that site.
Major events, such as the appointment of a new U.S. president or the acquisition of a major corporation, can trigger sudden fluctuations in the stock market. These events often lead to a massive influx of users buying and selling shares on trading platforms. Without high availability, these platforms risk crashing, causing financial losses for users and damaging the company’s reputation.
Companies and organizations must anticipate scenarios like this and make their web applications ready to face them. High availability systems can manage these incidents through:
The future of system availability is focused on smarter and greener approaches. AI, green technology, and edge computing are leading the way.
AI helps predict server failures and lets teams fix problems before anything breaks. It can also move workloads during busy times to keep things running smoothly.
Data centers are adopting green tech like liquid cooling to save energy. Some even reuse heat from servers to warm nearby buildings.
Edge computing reduces delays by processing data closer to where it's created, like on IoT devices or local servers. This is especially important for industries like healthcare and autonomous vehicles, where fast responses matter.
New technologies like quantum computing, blockchain, and smarter maintenance tools will likely improve system availability even more in the future.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.