
The Essential Guide to Data
Data is complicated. Uncomplicate it — and realize all that value — with this free guide.

The sheer amount of data businesses generate today is staggering.
Yet, without an effective strategy, most of this information remains untapped, with data left in silos.
Enter the data lake — a powerful and flexible solution for modern data management that can transform raw information into valuable assets.
If your organization is seeking better ways to handle and analyze data, this guide is for you. We’ll break down what a data lake is, how it works, and why businesses in diverse industries are adopting it.
Let's begin with a basic background of what data lakes are.
A data lake is a centralized repository designed to store vast amounts of structured, semi-structured, and unstructured data. Unlike traditional systems like data warehouses, a data lake doesn’t require predefining a schema before storing the data.
This makes it an ideal solution for organizations handling diverse types of raw data. Think a data lake as a vast, open body of water where data streams flow in from multiple sources. This includes everything from databases and IoT devices to social media platforms and application logs.
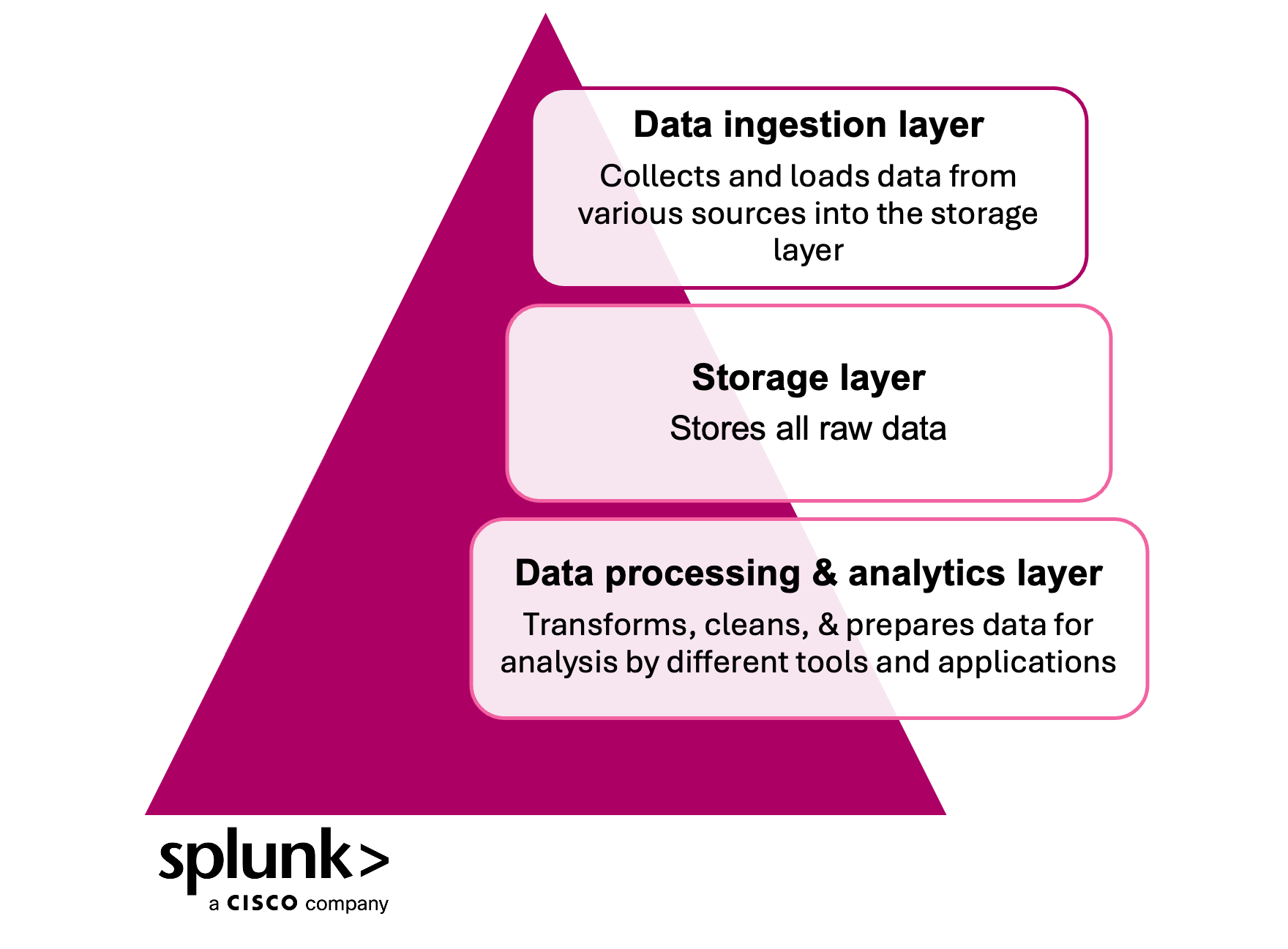
A data lake typically consists of three main components:
Other supporting components may include metadata management tools, security frameworks, and governance policies.
Understanding the distinction between a data lake and a data warehouse is critical, as they often complement one another rather than act as replacements.
This means that data lakes are able to hold unstructured data like images, videos, and text, while data warehouses are better suited for structured data like numbers and dates.
There’s also the data lakehouse, a modern hybrid architecture that combines the scalability and flexibility of data lakes with the structured data management and performance of data warehouses. It supports both advanced analytics and business intelligence from a unified platform.

These photos illustrate the fundamentals: a data lake doesn’t have an imposed structure, just like this natural lake, whereas data warehouses organize the data for particular uses.
Adopting a data lake provides several major advantages for businesses:
Data lakes enable the collection of information from frequently siloed sources into one central location. This accessibility allows analysts, data scientists, and executives to draw from the same well of information, reducing friction in data-driven decision-making.
Unlike data warehouses, which work best with structured data, data lakes can house any type of data: text, images, videos, streaming data, you name it. Organizations can innovate without being locked in by rigid schemas.
Modern solutions like AWS S3 and Azure Data Lake make it easy to scale petabytes of data without significant cost increases. The elastic nature of data lakes ensures your storage evolves along with your growing business.
For organizations exploring machine learning, big data analytics, or predictive modeling, data lakes are the gold standard.
Data teams are able to access raw data directly through the use of data lakes. This empowers them to perform advanced techniques impossible within traditional BI systems. For example, Amazon Security Lake and Splunk deliver an integrated centralized data lake for advanced analytics capabilities.
Storage solutions for data lakes are notably more affordable than high-performance databases or warehouses. Moreover, with the reduced need for extensive ETL (extract, transform, load) preparation, data lakes can provide significant cost savings.
To properly implement a data lake, you'll need a readily available solution. Several data lake solutions exist, catering to various use cases and budgetary constraints.
Some popular options include:
Splunk is not a traditional data lake but offers some similar capabilities. It’s primarily an analytics and observability platform used to collect, index, and analyze machine-generated data like logs and metrics.
While the Splunk data platform can store large volumes of semi-structured data, its strength lies in real-time search, alerting, and monitoring — especially for IT operations, security, and DevOps.
Splunk can act like a data lake in specific scenarios, such as with Amazon Security Lake or Splunk Data Fabric Search, where it centralizes and analyzes raw data. However, it’s not designed to be a full-scale, schema-flexible data lake for broad enterprise use.
(Explore the Splunk unified platform for data management, observability, and cybersecurity.)
Many organizations across industries rely on data lakes to power innovation. Here are a few examples:
Customer personalization in retail: Retail chains use data lakes to integrate purchase history, social media activity, and website behavior. This unified data can enable highly tailored shopping experiences for individual customers.
Healthcare data integration: Hospitals and laboratories store medical records, imaging data, and patient telemetry in data lakes. This enables streamlined research, predictive diagnostics, and improved patient care.
IoT and smart device analytics: Manufacturing firms leverage data lakes to analyze high-velocity IoT data from connected devices, helping them predict maintenance needs, optimize workflows, and minimize downtime.
Risk management in finance: Banks use data lakes to model customer behavior and predict risks such as credit defaults or fraud. Through the combination of structured financial records with unstructured web activity, banks can improve their overall risk management strategies.
(Related reading: financial crime risk management.)
To maximize the utility of your data lake, it’s essential to follow these step-by-step best practices:
Without proper governance, your data lake risks becoming a “data swamp,” where information is disorganized and difficult to extract. You should also establish rules for data organization, usage, and access early in the process.
Effective data governance isn’t really about organization — it’s essential for meeting regulatory compliance standards like GDPR, HIPAA, or SOC 2. Ensuring proper access controls, audit trails, and data lineage tracking helps businesses avoid legal pitfalls and maintain customer trust.
Ensure your data lake’s security by implementing robust user authentication, encryption, and compliance monitoring. Technologies like AWS Lake Formation make this process seamless for organizations.
Include metadata tagging to help users search, locate, and retrieve data efficiently. Tools like Apache Atlas can assist in managing comprehensive metadata across your lake.
Platforms like Apache Spark and AWS Glue simplify the process of extracting, transforming, and loading data without locking you into specific schema requirements. This aligns with the fluid storage philosophy of the data lake.
Make sure to keep an eye on user queries, job runtimes, and data storage costs. Try to look for bottlenecks and optimize operations to ensure the data lake evolves alongside your usage patterns.
Actively optimizing your data lake can significantly improve performance and reduce costs.
Together, these practices ensure your data lake stores data effectively and also delivers insights quickly and reliably.
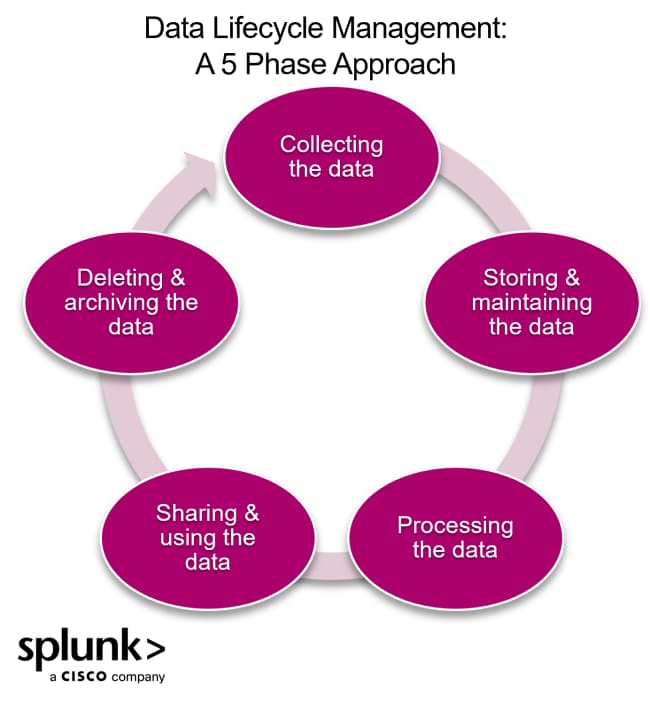
As data lakes grow, managing the lifecycle of stored data becomes crucial. Not all data holds long-term value, so implementing strategies — like archiving, tiered storage, or automated deletion of stale datasets — helps keep storage costs under control and performance optimized.
Many cloud providers offer built-in lifecycle policies to automate this process.
While the advantages of data lakes are compelling, there are challenges to consider:
As data ecosystems evolve, data lakes are becoming more intelligent and unified. Emerging trends include:
Organizations are also moving toward governed self-service models, allowing more teams to access and analyze data without heavy IT involvement — all while maintaining control and compliance.
A well-designed data lake goes beyond an advanced storage solution and presents an opportunity to unify your organization's data.
To bring in new business insights from disparate and siloed data, consider building a data lake for your business today.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.