
5 DevOps Practices
Download this free guide to advance your DevOps journey.
Key takeaways
In in order to achieve DevOps success, you must measure how well your DevOps initiatives work. Tracking the right DevOps metrics will help you evaluate the effectiveness of your DevOps practices.
In this article, I’ll explain many DevOps metrics, including their significance, the key metrics for various goals, and — best of all — tips for improving the score of each DevOps metric discussed here.
Splunk IT Service Intelligence (ITSI) is an AIOps, analytics and IT management solution that helps teams predict incidents before they impact customers.

Using AI and machine learning, ITSI correlates data collected from monitoring sources and delivers a single live view of relevant IT and business services, reducing alert noise and proactively preventing outages.
DevOps metrics are the data that aid in measuring the performance of key DevOps practices or processes such as:
These metrics enable organizations to monitor their progress — are you achieving the goals that you’ve set out? Metrics also help identify any bottlenecks that prevent you from maximizing application performance and employee productivity from DevOps processes. Utilizing these metrics will allow you to make the necessary improvements and get the maximum return on your investments.
In this article, we’ve broken down these metrics into a few categories:
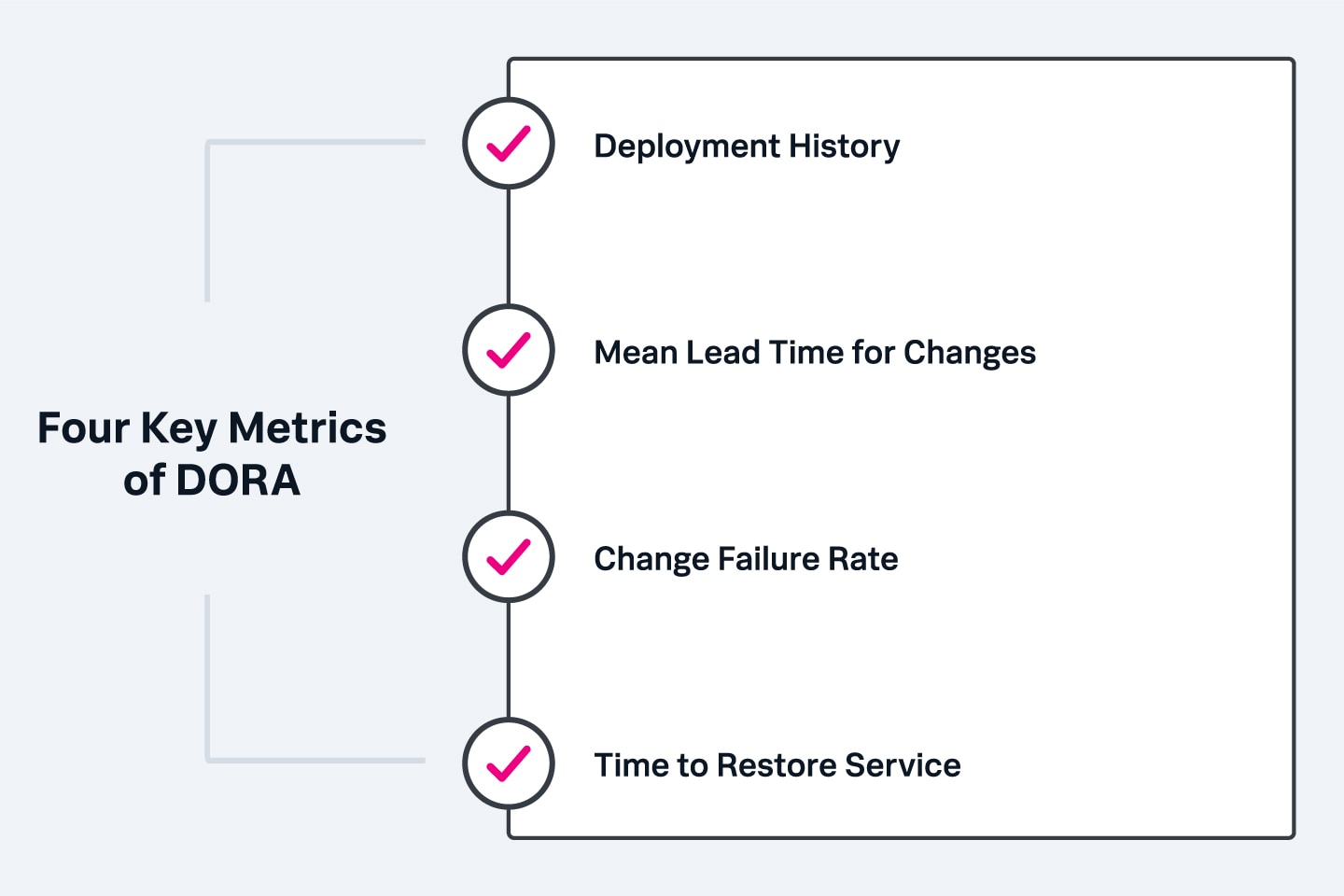
A well-known set of DevOps metrics are from DORA, Google's DevOps Research and Assessment (DORA) team. Over the years, DORA has identified what distinguishes high-performing DevOps teams. These four metrics are defined thanks to 7+ years of research on DevOps principles and their practical applications.
The DORA framework uses the four key metrics outlined below to measure two core areas of DevOps: speed and stability. Deployment Frequency and Mean Lead Time for Changes measure DevOps speed, and Change Failure Rate and Time to Restore Service measure DevOps stability. Used together, these four DORA metrics provide a baseline of a DevOps team’s performance and clues about where it can be improved.
The following section briefly explains these four key DevOps Metrics, what a good score is and how to improve them.
Change failure rate is the percentage of deployments causing a failure in production that require an immediate fix, such as service degradation or an outage. A low change failure rate is desirable because the more time a team spends addressing failures, the less time it has to deliver new features and customer value. This metric is usually calculated by counting how many times a deployment results in failure and dividing that by the total number of deployments to get an average. It does not count the bug fixes before deploying to production. You can calculate CFR by counting the number of deployments and, out of them, how many have resulted in hotfixes or rollbacks. You can calculate this metric as follows:
(deployment failures / total deployments) x 100
Change failure rate benchmarks are:
This metric is a good indicator of:
The CFR of your team should sit between 0-15% if you are following effective DevOps practices. Practices like trunk-based deployment, test automation and working in small increments can help improve this metric.
DF is a measure of how frequently you deploy changes to production. High-performing teams usually deploy code to production on-demand or multiple times a day. Deploying monthly or weekly will result in a lower DF.
This metric helps teams to:
The deployment frequency benchmarks are:
Organizations vary in how they define a successful deployment, and deployment frequency can even differ across teams within a single organization.
(Read our full guide to deployment frequency.)
Lead time is the time a code commit requires to become production-ready after passing all the necessary tests in the pre-production environment. Calculate this metric using the times of the code commit and the start of the release.
Mature DevOps teams maintain LT in hours, while medium or low-performing teams usually take days or weeks. You can improve the LT by implementing practices like trunk-based deployment, working in small batches and test automation.
Mean lead time for changes benchmarks are:
An organization’s particular cultural processes — such as separate test teams or shared test environments — can impact lead time and slow a team’s performance.
MTTR is the time it takes to recover from a total failure or partial service interruption in a production environment. High-performing teams maintain an MTTR of less than one hour, while it can be as high as a week for low-performing teams. You can calculate MTTR by considering the time an incident occurred and the time it took to resolve it.
The MTTR score depends on how quickly you can identify an incident when it occurs and deploy a fix for it. You can improve the MTTR score by continuously monitoring systems and services and alerting the relevant personnel as soon as an incident occurs. It allows them to take the necessary actions quickly.
Time to Restore Service benchmarks are:
Companies in virtually any industry can use DORA metrics to measure and improve their software development and delivery performance. A mobile game developer, for example, could use DORA metrics to understand and optimize their response when a game goes offline, minimizing customer dissatisfaction and preserving revenue. A finance company might communicate the positive business impact of DevOps to business stakeholders by translating DORA metrics into dollars saved through increased productivity or decreased downtime.
DORA metrics are a useful tool for quantifying your organization’s software delivery performance and how it compares to that of other companies in your industry. This can lead to:
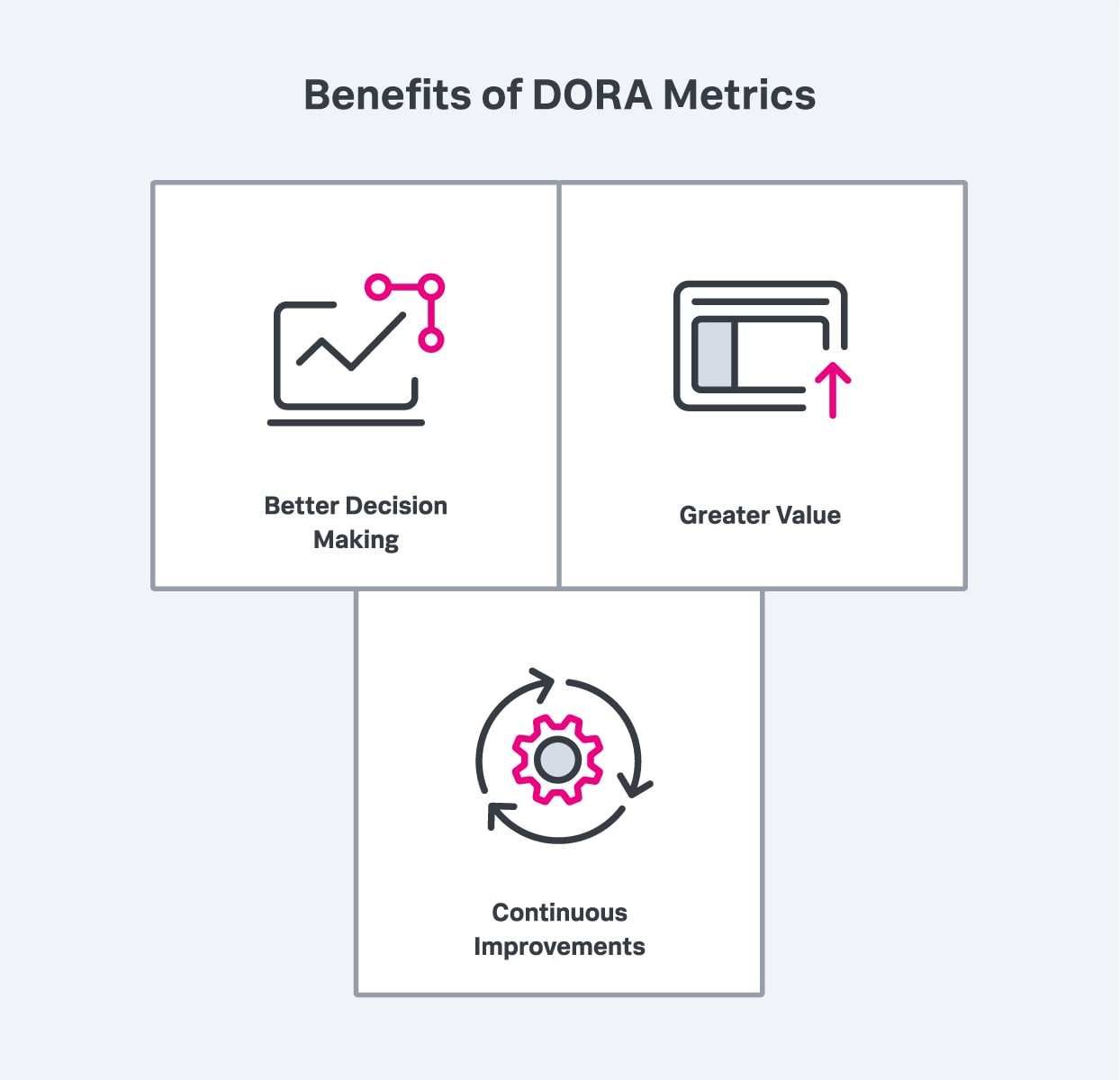
DORA metrics can lead to better decision making, greater value and continuous improvement.
Even though DORA metrics provide a starting point for evaluating your software delivery performance, they can also present some challenges. Metrics can vary widely between organizations, which can cause difficulties when accurately assessing the performance of the organization as a whole and comparing your organization’s performance against another’s.
Each metric typically also relies on collecting information from multiple tools and applications. Determining your Time to Restore Service, for example, may require collecting data from PagerDuty, GitHub and Jira. Variations in tools used from team to team can further complicate collecting and consolidating this data.
OK so DORA’s metrics give us a great place to start. Still, several more important DevOps metrics help measure the success of DevOps processes. Let's go through them in the following sections. We’ve broken these sections into metrics for tests and code quality, deployment, continuous integration, customer satisfaction and, lastly, monitoring practices.
This metric measures the number of defects that escaped from lower-level testing and were pushed into production. Your teams should maintain this value close to zero. A higher Defect Escape Rate indicates that your testing processes need more automation and improvement.
DevOps teams should find at least 90% of the defects in pre-production environments before releasing the code to production.
This metric is a good indication of your code quality. You can measure it by dividing the number of tests that failed in the CI pipeline by the total number of tests executed.
A high CI test failure rate indicates your code needs more improvement and persuades developers to execute their own unit tests before committing the code.
Code coverage indicates the amount of code tested by the automated test suite. Generally, the best DevOps practice is to maintain a higher automated code coverage as it helps detect failures quickly. However, having 100% test coverage does not ensure maximum code quality, as it can include unnecessary testing.
Cycle time measures the time between the start of working on a specific item and when it becomes ready for end-users. In terms of development teams, cycle time is the time between a code commit and when it is deployed to production.
The longer the Cycle Time, the more work in progress — and the less efficient the workflows are. Teams need to optimize and improve the efficiency of their workflows to improve the Cycle Time.
Deployment size is determined by the number of implemented features, stories and bug fixes. You can measure it using the number of story points completed for each deployment. Combine this metric with other metrics like deployment frequency and cycle time to understand the productivity of each deployment.
Deployment time is the time it takes to complete a deployment. It is a useful DevOps metric to measure the efficiency of your deployment pipelines. If the deployment time is very long, taking many hours to deploy, it indicates a potential problem and decreases the productivity of your release team.
You can improve this metric by removing unnecessary steps from the deployment pipeline and introducing parallelization mechanisms.
Flow metrics are a framework for measuring how much value is being delivered by a product value stream and the rate at which it is delivered from start to finish. While traditional performance metrics focus on specific processes and tasks, flow metrics measure the end-to-end flow of business and its results. This helps organizations see where obstructions exist in the value stream that are preventing desired outcomes.
There are four primary flow metrics for measuring value streams:
Flow metrics help organizations see what flows across their entire software delivery process from both a customer and business perspective, regardless of what software delivery methodologies it uses. This provides a clearer view of how their software delivery impacts business results.
This metric is a count of daily CI pipeline executions. High-performing teams maintain more CI runs per day, typically 4 or 5 times per developer. It indicates the proper practice of frequent releases and trusts in the CI/CD pipeline.
CI can take place many times a day, even though each of them may not be successful. The CI success rate is measured by dividing the total number of successful CIs by the total number of CI runs. It’s better to have a higher CI success rate: it indicates that your CI/CD processes are well maintained and developers perform dev testing effectively.
Of course, the goal of all of this is to satisfy your customers. Here’s what to measure.
The number of reported incidents or support tickets filed by customers indicates how satisfied your customers are with your products. This metric also helps track customer feedback on your releases and provides visibility into the severity of production issues.
Lower customer ticket volumes indicate you have the right approaches and only need slight improvements.
Application availability is the time the application is available to the end-users in its fully functional state. Application errors can cause longer downtimes, causing frustration among users who try to access your application. To improve application availability, teams must lay out strategies like:
This metric evaluates how the application performs under stress and various user loads. Teams must carry out these tests before deploying to production in a pre-deployment environment equivalent to production.
This metric enables them to identify transactions that can fail and defects when the system is under load. Then, they can optimize the code before deploying and provide a consistent user experience.
MTTD is the time it takes to detect a production failure and flag it as an issue. This metric helps evaluate the effectiveness of your monitoring and alerting systems. The lower the MTTD, the more likely it is that you can fix the issue and push it into production before it affects end users. You can improve MTTD by:
(Read all about DevOps monitoring and see how Splunk can help.)
This metric indicates how many users are accessing their systems and how many transactions are happening in real-time. There is a high risk of systems failing when there is a high load. Therefore, you can keep your DevOps team on standby to respond in case of any issues.
Once you automate DevOps metrics tracking, you can begin improving your software delivery performance. Several engineering metrics trackers capture common DevOps metrics, including:
When considering a metric tracker, it’s important to make sure it integrates with key software delivery systems including CI/CD, issue tracking and monitoring tools. It should also display metrics clearly in easily digestible formats so teams can quickly extract insights, identify trends and draw conclusions from the data.
DevOps metrics are data that enable organizations to assess the effectiveness of their DevOps practices and how they contribute to the achievement of organizational goals. The four key DevOps Metrics include Change Failure Rate, Deployment Frequency, Lead Time To Change, and Mean Time To Restore Services.
Additionally, several other DevOps metrics have been identified related to key tasks of a software delivery pipeline, including deployment, testing, monitoring and end-user experiences. These metrics can ensure successful business outcomes by measuring them with the DevOps processes organizations have implemented.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.