
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.

Oh no! You’ve been hacked, and you have experts onsite to identify the terrible things done to your organization. It doesn’t take long before the beardy dude or cyber lady says, “Yeah...they used DNS to control compromised hosts and then exfiltrated your data.”

As you reflect on this event, you think, “Did I even have a chance against that kind of attack?”
Yes, you did because Splunk can be used to detect and respond to DNS exfiltration. In fact, people have been using DNS data and Splunk to find bad stuff in networks for nearly two decades!
Since you've been an avid reader of Threat Hunting with Splunk: The Basics, you all know that good hunting starts with a hypothesis or two. So, let’s create a hypothesis! In this article, we’ll deal with the perennial topic of DNS exfiltration and we’ll show some awesome visualizations,hunting and slaying techniques.
(This article is part of our Threat Hunting with Splunk series and was originally written by Derek King. We’ve updated it recently to maximize your value.)
When we talk about DNS exfiltration, we are talking about an attacker using the DNS protocol to tunnel (exfiltrate) data from the target to their own host. You could hypothesize that the adversary might use DNS to either:
With the right visualizations and search techniques, you may be able to spot clients behaving abnormally when compared either to themselves or their peers!
If you're already sucking DNS data into Splunk, that's awesome! However, if you’re not and you haven't seen Ryan Kovar and Steve Brant's .conf presentation, Hunting the Known Unknowns (with DNS) then check it out — it's a treasure trove of information. If the work of my esteemed colleagues just isn’t your bag, then I’m sure they won’t take it personally...much.
Either way, let me tell you that these can all be excellent sources of data:
If you want to follow along at home and are in need of some sample data, then consider looking at the “BOTS V3 dataset on GitHub”. ” Note* All of the searches below were tested on the BOTSv1 data found here.
Are you a victim of DNS exfiltration? There are many questions you can use to support your hypotheses. For example, if your hosts are compromised they may show changes in DNS behaviour like:
These are adversary techniques we can craft searches for in Splunk using commands like stats, timechart, table, stdev, avg, streamstats. (Visit each commands’ Docs page for more specific information.)
In the section below, I will show you some ways to detect weirdness with DNS based on the techniques highlighted above.
NOTE: As always, we write our searches to be common information model (CIM) compliant. You may need to adjust the sourcetypes/tags/eventtypes to suit your environment!
Capturing spikes or changes in client volumes may show early signs of data exfiltration.
tag=dns message_type="Query" | timechart span=1h limit=10 usenull=f useother=f count AS Requests by src
We begin with a simple search that helps us detect changes over time. The first line returns the result set we are interested in, followed by the timechart command to visualise requests over time in one-hour time slices.
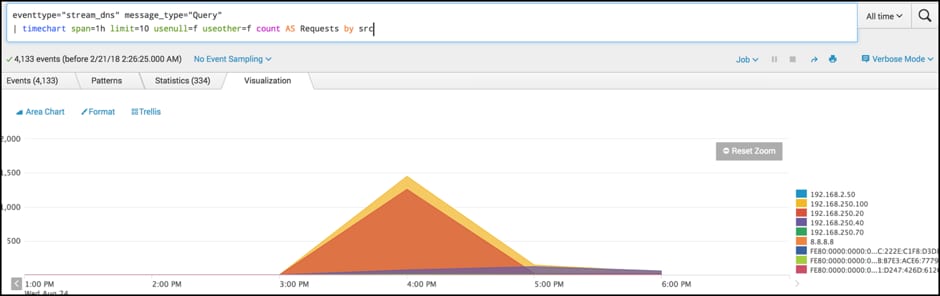
Clients with an unnecessary number of events compared with the rest of the organisation may help to identify data transfers using DNS.
Changes in resource type behaviour for a client may point toward potential C&C or exfiltration activity. Carefully observe both A records and TXT records, as these are common techniques. However, don’t be blind-sided into just these two resource types!
tag=dns message_type="QUERY" | timechart span=1h count BY record_type
Continuing to keep things steady for a start, we again begin with the same dataset and use the timechart command to visualise the record type field over time in one-hour slices. This search could be used in conjunction with the previous search by including a client IP of interest to help follow our hypothesis.
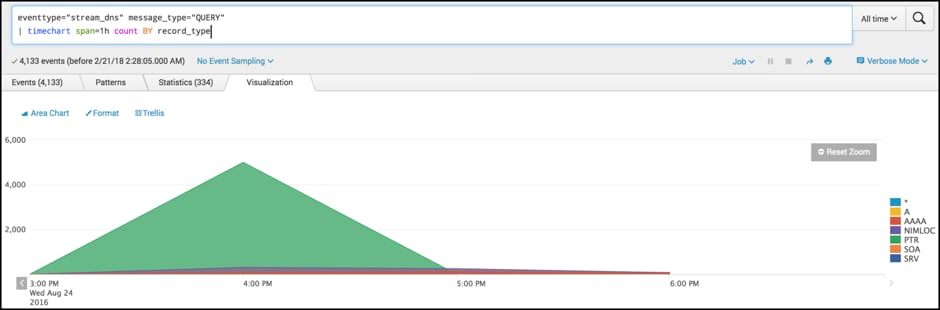
Spotting changes in behaviour early is a great way to reduce the impact of a compromised host. Using Splunk to search historical data helps to identify when a host was initially compromised and where it has been communicating with since.
Events that have significant packet size and high volumes may identify signs of exfiltration activity.
tag=dns message_type="QUERY" | mvexpand query | eval queryLength=len(query) | stats count by queryLength, src | sort -queryLength, count | table src queryLength count | head 1000
Whoa, we’re throwing in a couple more commands here. Let’s take a closer look — it’s fantastic, I promise.
We start with the same basic search as before, which you can follow along with the BOTSv1 dataset, but this time we will:
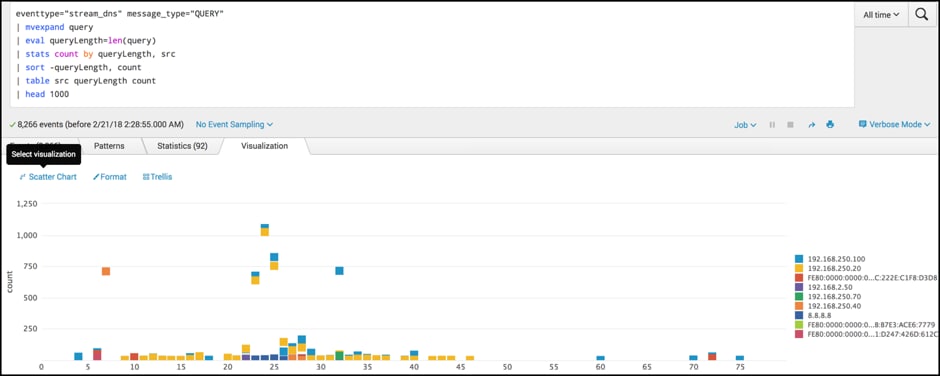
In the above example, looking for distributions that do not match the norm are identified using the scatter chart. A high number of requests, and/or large packets will be of interest.
For example, I usually visit ‘www.bbc.co.uk’ and ‘www.facebook.com’ (thirteen, and sixteen characters respectively). If, however, the malicious software opens a sensitive document that’s 5 Mb in size, chops it into 255-byte packets, and sends via DNS requests, then I’m likely to see many 255-byte packets.
Let’s take it up a notch now and look for clients that show signs of beaconing out to C&C infrastructure. Beaconing activity may occur when a compromised host ‘checks in’ with the command infrastructure, possibly waiting for new instructions or updates to the malicious software itself.
tag=dns message_type="QUERY" | fields _time, query | streamstats current=f last(_time) as last_time by query | eval gap=last_time - _time | stats count avg(gap) AS AverageBeaconTime var(gap) AS VarianceBeaconTime BY query | eval AverageBeaconTime=round(AverageBeaconTime,3), VarianceBeaconTime=round(VarianceBeaconTime,3) | sort -count | where VarianceBeaconTime < 60 AND count > 2 AND AverageBeaconTime>1.000 | table query VarianceBeaconTime count AverageBeaconTime
In this example, we use the same principles but introduce a few new commands.
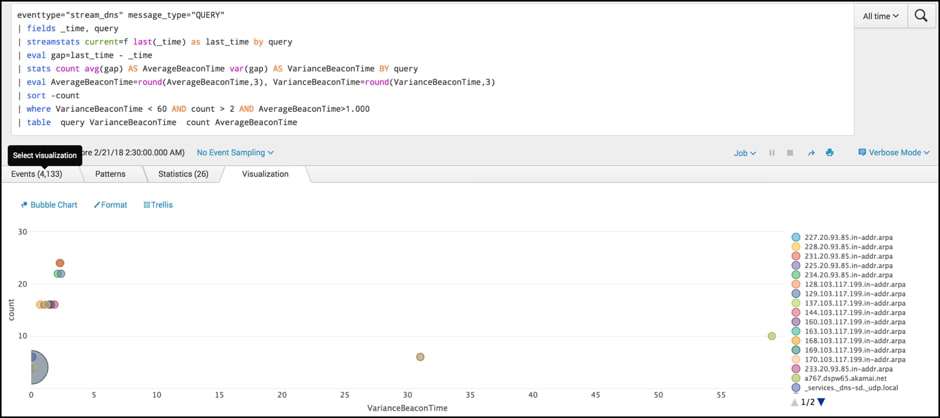
In this example, spotting clients that show a low variance in time may indicate hosts are contacting command and control infrastructure on a predetermined time slot. Say every thirty seconds or every five minutes.
Identifying the number of hosts talking to a specific domain may help to identify potential BOT activity or help to identify the scope of hosts currently compromised.
tag=dns message_type="QUERY" | fields _time, src, query | streamstats current=f last(_time) as last_time by query | eval gap=last_time - _time | stats count dc(src) AS NumHosts avg(gap) AS AverageBeaconTime var(gap) AS VarianceBeaconTime BY query | eval AverageBeaconTime=round(AverageBeaconTime,3), VarianceBeaconTime=round(VarianceBeaconTime,3) | sort –count | where VarianceBeaconTime < 60 AND AverageBeaconTime > 0
Nothing much new in this search. We look to see beaconing activity and the number of distinct hosts communicating with it, which may help us to scope multiple hosts being bad! The search only introduces one new function of our stats command:
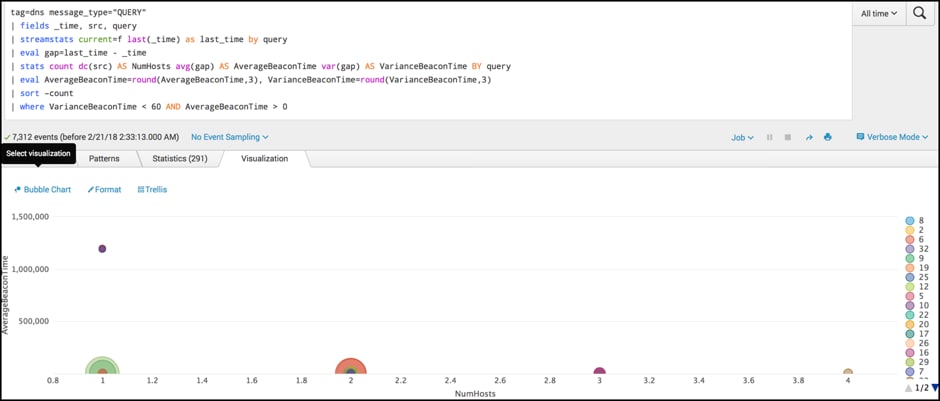
This example is very like the previous beaconing activity (i.e., looking for timing requests that are consistent), but this time we are aggregating clients that are showing the same behaviour.
Encoded information could be transmitted via the sub-domain. Looking at the number of different subdomains per domain may help identify command and control activity or exfiltration of data.
tag=dns message_type="QUERY" | eval list="mozilla" | `ut_parse_extended(query, list)` | stats dc(ut_subdomain) AS HostsPerDomain BY ut_domain | sort -HostsPerDomain
Here, we are looking to see how many subdomains are requested per domain. This behaviour may help us identify signs of exfiltration or DGA domains. The URL Toolbox allows us to parse domain names easily. Check out our "UT_parsing Domains Like House Slytherin" blog post if you want to know more.
As always, we begin with our DNS dataset of interest and create a field with a value of ‘Mozilla’. If you have read the link above, you’ll understand perfectly. If not, it’s needed for the URL Toolbox. ;-)
After ‘ut_parse_extended’ we continue to use commands we have used previously. Our stats command is used to count the distinct number of sub-domains by domain, and then the results are sorted to give us the highest value first.
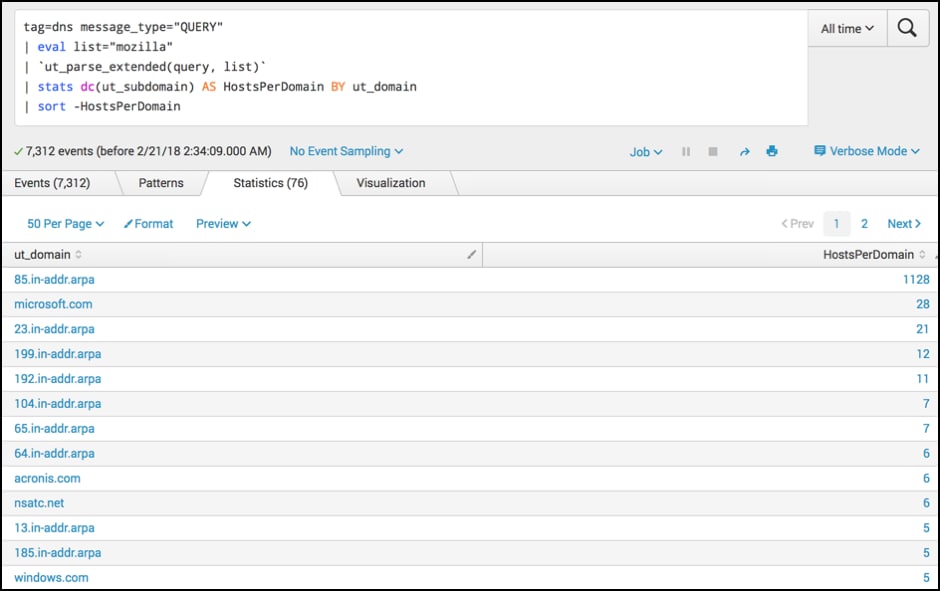
In this example, we are looking for high numbers of subdomains per domain. It's likely we will need to do some filtering for common, assumed good sites.
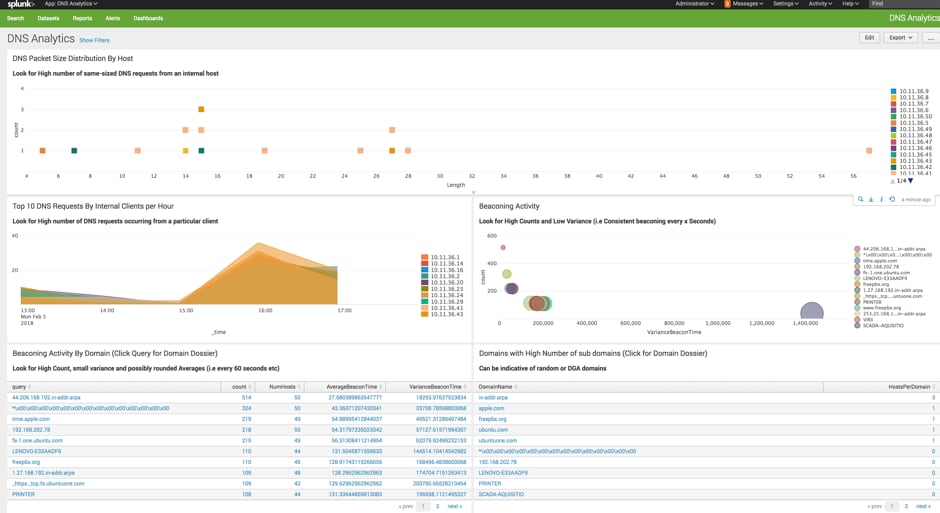
Here at Splunk, we have a saying: “Get shi stuff done!” The good news is everything above is available to download right away this GitHub repo to help you get started hunting.
Here are some additional ideas to enhance the quality of your results:
Happy hunting!
We intentionally avoided talking about randomness in this article. If you are interested in detecting typ0 5quatting or more randomness with math, then take a look at these articles:

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.