
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
As data continues to explode across the enterprise, we are finding that it is becoming increasingly challenging for organizations to keep up. A recent Splunk report, "The Data Age is Here," found that 57% of companies interviewed expressed that the volume of data is growing faster than they can manage, with 47% bluntly saying they will fall behind when faced with rapid data volume growth. The good news is that this is the perfect opportunity to leverage streaming technology, and why we are excited to announce the general availability of Splunk Data Stream Processor (DSP) 1.2!
So, what’s in the box?!?

DSP 1.2 provides users with the ability to expand data access and support for multicloud environments where data sprawl creeps in. We now include GCP Pub/Sub sources to support our customers multicloud strategy and the need to move data between multiple vendors. We’ve also added Azure Event hub to the growing list of supported destinations.
We all know IT data can be more valuable if enriched with context however, adding this context on the stream to high volume data with millisecond latency is no easy task. DSP 1.2 Lookups allow you to do in-stream data enrichment at scale, unlocking additional value in IT and Security. DSP Lookups help enrich events in your data pipeline with contextual and timely data, making downstream searches in Splunk Enterprise much more relevant and accurate. From a security perspective, this can help improve overall security posture by increasing the fidelity of incident detection and accelerating investigations for determining “who” or “what” was involved in, or affected by an incident.
 Yes – machine learning! Streaming ML unleashes your ability to learn, infer and analyze data. Unlike traditional batch ML systems where you have to train and validate models and constantly update them, our ML learns continuously so your models are always up to date. Moreover, our machine learning scales seamlessly, independent of volume and cardinality. Our first-of-their-kind algorithms on the stream that can learn with a “single pass” of data will accelerate your insights, and DSP 1.2 is adding to our growing list of algorithms, including:
Yes – machine learning! Streaming ML unleashes your ability to learn, infer and analyze data. Unlike traditional batch ML systems where you have to train and validate models and constantly update them, our ML learns continuously so your models are always up to date. Moreover, our machine learning scales seamlessly, independent of volume and cardinality. Our first-of-their-kind algorithms on the stream that can learn with a “single pass” of data will accelerate your insights, and DSP 1.2 is adding to our growing list of algorithms, including:
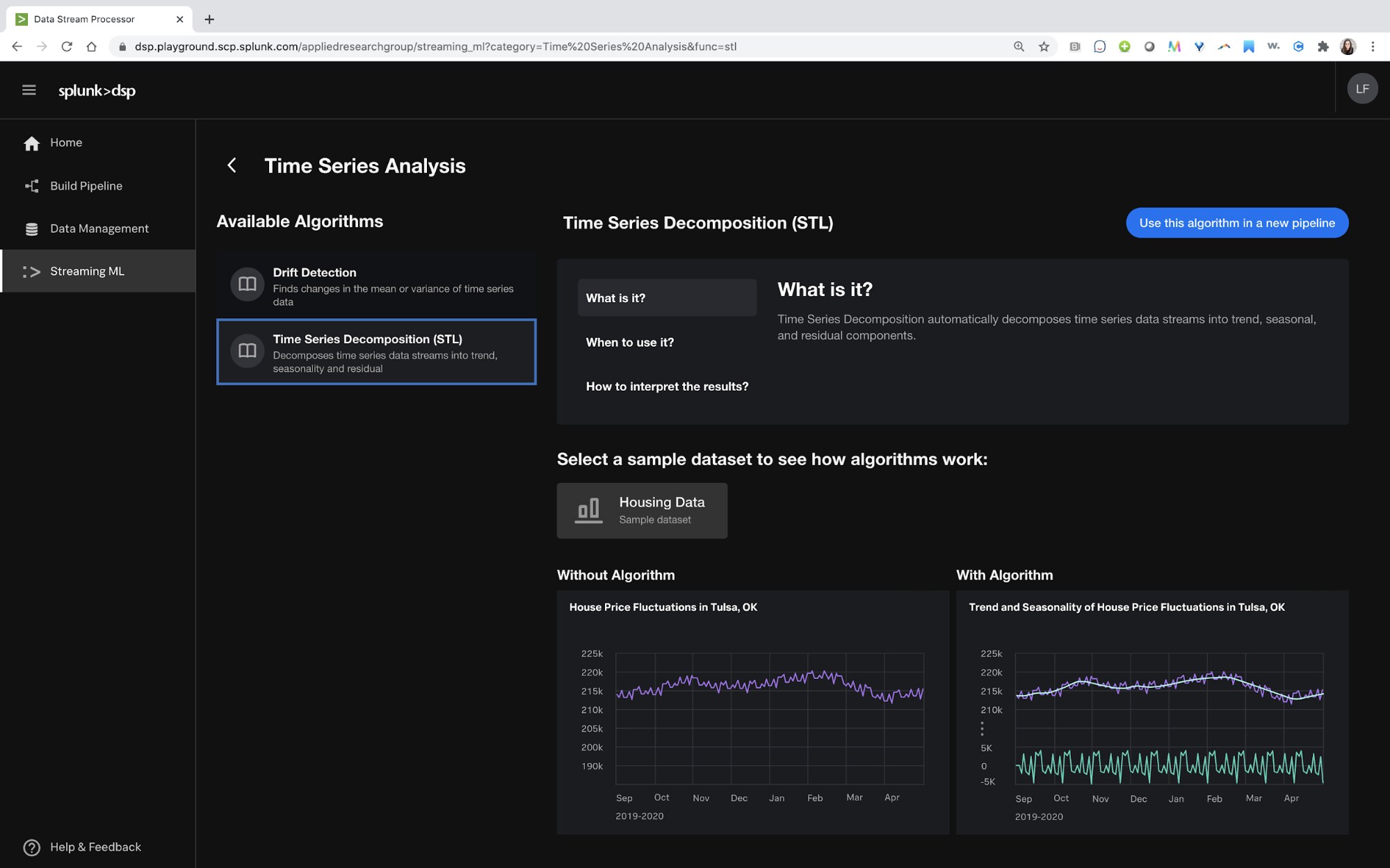
We also make applying ML to the stream easy with a dedicated ML GUI so folks who aren’t data scientists can capture the value of machine learning.
For more detail on how you can apply machine learning to the stream, check out our latest essential guide here.
For more information on Splunk Data Stream Processor, check out our webpage here.
----------------------------------------------------
Thanks!
Cody Bunce

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
