
Free Report: Observability Platforms
Get the 2024 Gartner® Magic Quadrant™ for Observability Platforms for free.

Service performance monitoring, or cloud service performance monitoring, is the practice of tracking the health and performance of cloud infrastructure environments. Using various metrics and techniques, IT operations teams can assess two areas:
Cloud environments offer enterprises less visibility and control than their on-premises counterparts, creating challenges for DevOps professionals and organizations in general to understand their cloud usage and make informed decisions that:
Cloud monitoring technologies harness the information generated by cloud data centers, and the apps and services running on top of them, to provide deeper visibility into cloud environments. This in turn allows IT teams to detect and respond to performance issues before they impact the organization’s customers.
Service performance monitoring is essential for ensuring the health and optimizing the performance of cloud-hosted apps and services, while offering a range of benefits. Performance monitoring data can help organizations to:
In the following article, we’ll look at how service performance monitoring works, outline the benefits it brings to the enterprise, and, lastly, look at some solutions and tools that can help you get started.
Modern performance monitoring continuously evaluates the health of cloud-based IT infrastructures and the applications and services running on them, becoming an essential component of infrastructure monitoring.
Organizations have to rely on infrastructure data to help identify the cause of bottlenecks and other performance issues. However, large-scale cloud environments generate overwhelming volumes of data that can obscure the cause of problems.
Modern performance monitoring strategies focus on collecting and interpreting log data to gain insights into:
Modern performance monitoring requires specialized cloud-native tools that can collect a variety of raw metrics and parse them in logical ways so that users can easily interpret and act on them. Cloud performance monitoring tools use a combination of dashboard visualizations, predictive analytics, observability, and KPI alerts working alongside on-premises monitoring systems to provide full visibility into the operation of critical services.
Predictive analytics is the application of mathematical models to large volumes of data to uncover past behavior patterns and predict future outcomes. The practice combines data mining, machine learning and statistical algorithms to provide the “predictive” element.
Predictive analytics is a key component of service performance monitoring tools. As the cloud, virtualization, the Internet of Things (IoT), and other technological advances have made IT infrastructure more complex, monitoring and troubleshooting these environments has become too challenging for humans to do on their own.
Predictive analytics overcomes this difficulty by using big data and artificial intelligence to identify patterns in the terabytes of data produced by cloud-based infrastructures and predict performance issues, capacity shortfalls, network outages, security breaches and other problems. IT teams can then get ahead of these issues to mitigate their impact on users and the business.
Predictive analytics can be used to power and enable modern performance monitoring solutions that improve cloud service performance in the following ways:
Predictive analytics requires that data is properly prepared, the right algorithm selected and trained, and other measures taken to ensure users get the desired results.
Performance monitoring tools combined with vendor expertise can help ensure predictive analytics is properly applied and creating value.
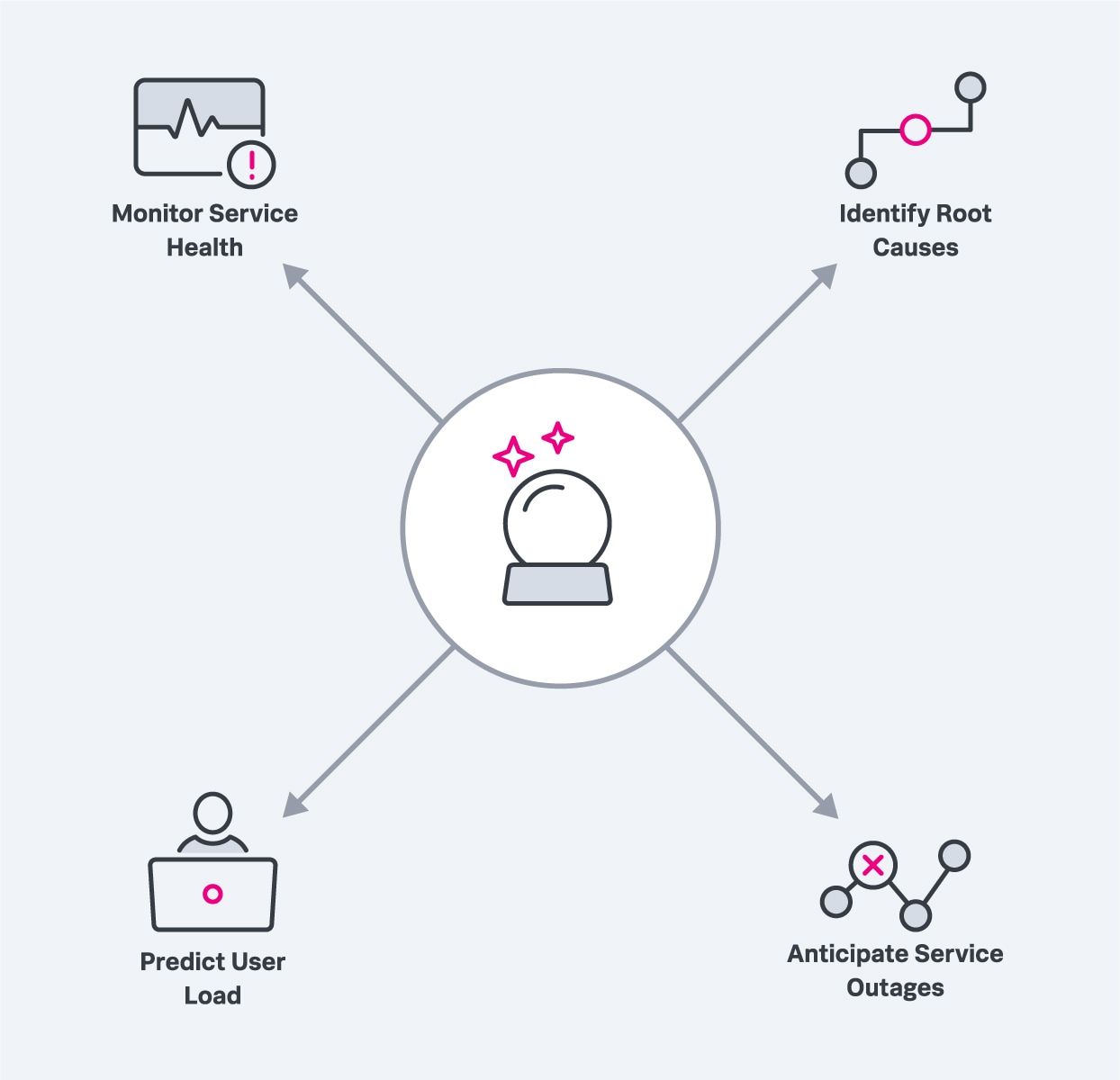
Predictive analytics enables modern performance monitoring solutions and improves cloud service performance in many ways.
Performance indicators, also known as key performance indicators (KPIs), are quantifiable values used to track progress toward a particular result or business objective. KPIs are typically used to set a standard of success so that a team or organization can work toward a common goal. KPIs differ from metrics in that KPIs define an outcome, whereas metrics are data points that can measure progress toward that outcome. Check out this blog post to learn more about SRE Metrics and the Four Golden Signals of Monitoring.
KPIs are essential for reducing the noise in cloud infrastructure data and extracting meaningful insights, so it’s important to define and monitor them at every layer of infrastructure. Some of the most important KPIs for service performance monitoring include:
Monitoring the application layer of your infrastructure provides the clearest insight into the user experience. Slow load times, frequent error messages and app crashes will frustrate customers and ultimately drive them to abandon your web applications. Application performance monitoring allows you to gauge your applications’ performance on users’ devices, providing you with critical information such as error rates, CPU usage and response times, as well as scoring systems that measure customer satisfaction.
Service performance monitoring is a component of a broader application performance management (APM) strategy, which oversees your applications’ availability, performance and user experience, and which would require buy-in from application teams in addition to IT and operations teams. Performance monitoring is a crucial APM practice as it enables organizations to understand the health of their software applications, along with the supporting systems and infrastructure, so they can continuously improve the user experience.
Both open source and proprietary performance monitoring tools allow you to evaluate the state of your cloud environment and the availability, performance and security of business-critical apps and services. Each of the major cloud providers offers its own performance monitoring toolset. There are also third-party tools that integrate with an array of cloud service providers and microservices.
Enterprises use service performance monitoring to assess the health, performance and utilization of the apps and services running on their cloud environment. An IT department, for example, might use service performance monitoring to identify strengths and weaknesses in support or diagnose underlying drivers of performance gaps. Slow response times, downtime, under-resourced workloads, and data breaches have detrimental consequences for both the applications’ users and the business. Service performance monitoring allows enterprises to be proactive by tracking resource consumption, response times, and other performance metrics as well as predict potential issues so they can resolve problems before they impact end users.
Service performance monitoring is important because the widespread move to SaaS and cloud environments means that traditional monitoring solutions designed for on-premises IT infrastructure have become less relevant. Historically, infrastructure monitoring has centered around assessing the health and performance of servers and other network hardware. As organizations have moved to the cloud, they no longer manage or have visibility into many critical components abstracted away by the cloud vendor. As the responsibility for monitoring the underlying infrastructure shifts to the cloud provider, organizations have shifted most of their focus to monitoring their services and applications. Service performance monitoring uses cloud technologies to provide the visibility needed to observe and manage these dynamic environments.
Service performance monitoring offers the following benefits:
Improved availability and reliability: Service performance monitoring allows you to proactively identify and resolve degrading performance, functionality problems, and security threats before they compromise your ability to deliver services to your customers.
To get the most from service performance monitoring, it’s important to select the most effective performance monitoring tool to meet your business objectives. To get started, consider the following best practices:
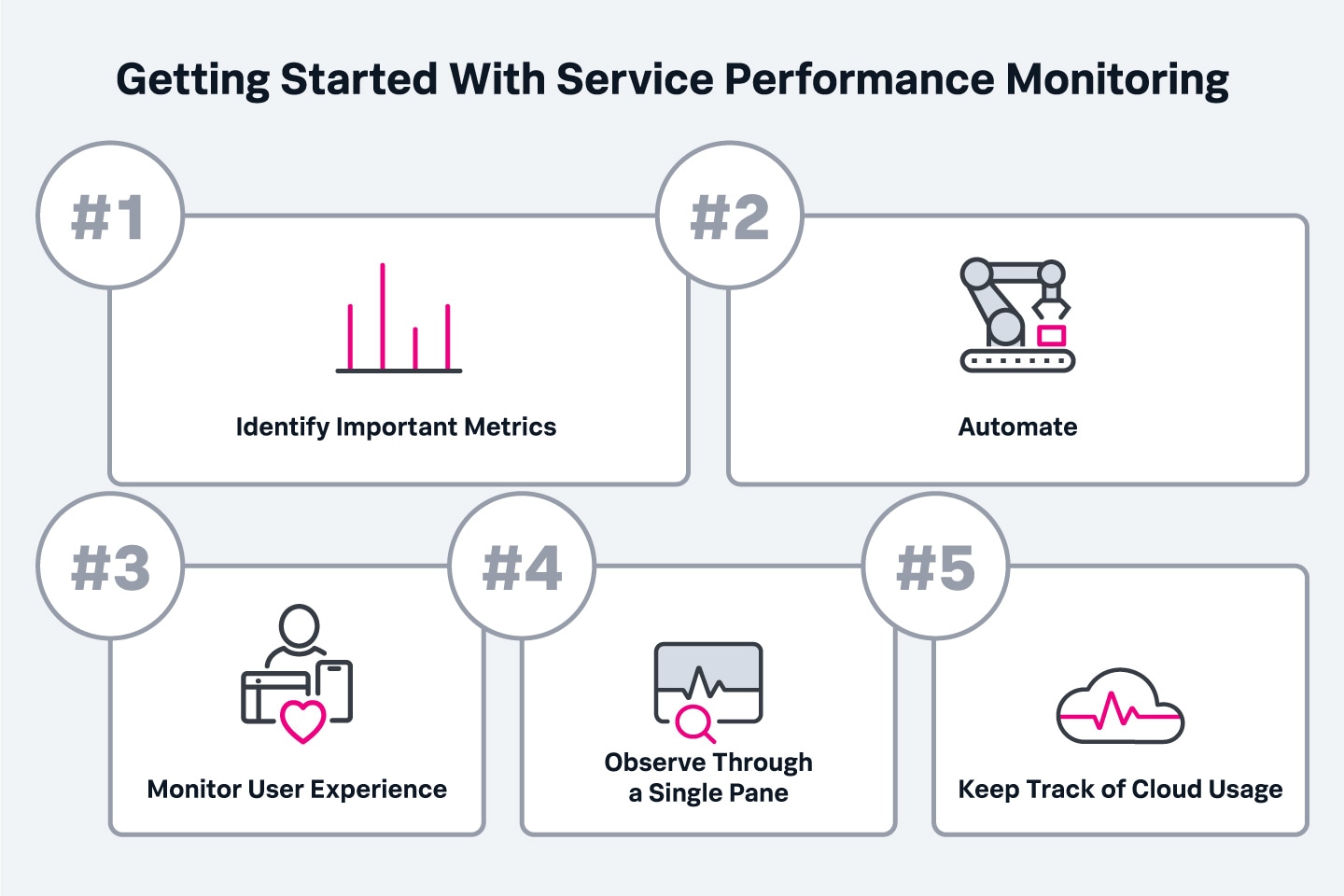
Before investing in a solution, it’s important to decide what metrics you plan to track. Tracking everything is counterproductive, so start by taking inventory of your assets and consider what data you would like to collect while prioritizing metrics that have a direct impact on your organization’s bottom line.
Performance monitoring is a continuous process that is made far more manageable through automation. You can, for example, set up logging and red-flag events to automatically push a notification when a problem, such as excessive resource usage, is detected. Many monitoring tools support automated monitoring and reporting templates.
Monitoring service performance from the inside is important, but it’s just as critical to measure your end-user experience. Monitoring response times, frequency of use, and similar metrics can provide a clearer and more complete performance picture.
You’ll want to monitor your own physical infrastructure alongside your cloud environment. Look for a monitoring solution that can report performance data from disparate sources on a single platform using consistent metrics to get the most comprehensive visibility into your IT infrastructure performance.
Cloud services make it easy to scale, but with increased use typically come additional fees. Look for a performance monitoring solution that can keep tabs on your organization’s cloud usage and the associated costs.
Cloud environments are essential for business agility, but they bring their own challenges when it comes to visibility. Without access to the underlying infrastructure, it can be exceedingly difficult to get to the bottom of service management, deterioration or disruptions that can have long-term consequences for your business. Service performance monitoring gives you the clarity you need to take back control and ensure the best experience for your customers.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.