
The Essential Guide to Data
Data is complicated. Uncomplicate it — and realize all that value — with this free guide.

The advent of the data mesh has changed the way organizations manage and utilize data. It’s not expected to go away anytime soon.
Data mesh, in short, is a popular approach to data management in the enterprise. Its primary goal is to empower teams, especially cross-functional ones.
In this article, we'll delve into what data mesh is and explore its key principles. We'll also discuss some benefits of implementing this modern data mesh approach in your organization. Additionally, we will provide insights on how to implement it successfully.
Let's have a closer look.
Data Mesh is a set of principles with a modern decentralized approach to data architecture and data management. The aim of data mesh is to empower cross-functional teams within an organization.
Unlike traditional centralized data architectures, which rely on a single team managing all aspects of the data ecosystem, a data mesh distributes the responsibility for data across different product teams. Each team takes ownership of their own domain-specific data products and manages them independently using mesh principles. This distributed approach allows for greater scalability, flexibility, and agility in addressing evolving business needs.
(Despite the names, data mesh it not to be confused with data fabric, which is an infrastructure-level layer of software that enables data to move between different systems.)
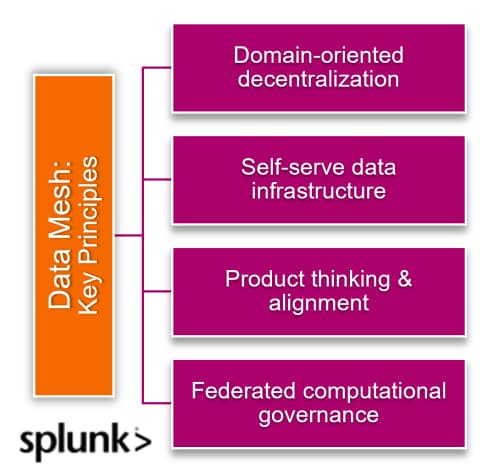
To help you better understand the several aspects of data mesh, let's explore some key principles.
Firstly, a data mesh is based on the concept of domain-oriented decentralization. It allows each product team to take ownership of its own data products and manage them independently with high autonomy and low coordination.
This approach allows product teams to focus on their core competency, quickly develop new features and services, and evolve their data stack in line with changing business needs. Here are some examples:
Next, having a dash mesh also means more autonomy is placed in the hands of different teams.
By promoting autonomy and reducing dependencies on centralized teams, organizations can empower cross-functional teams to have more control over their own data needs. This approach allows for faster decision-making, increased agility, and improved collaboration across the organization.
In a data mesh architecture, you'll also need to think of your data as a product. Treating data as a product involves:
This approach ensures that data products are treated with the same level of care and attention as any other tangible product in an organization.
Continuous improvement is achieved through feedback loops that allow teams to iterate on their data products based on user feedback and changing business needs. By staying responsive to feedback, teams can ensure that their data products remain relevant, valuable, and effective over time.
In each implementation of an effective data mesh architecture, an organization would need federated computational governance. Federated computational governance is a set of protocols and procedures to ensure data security, integrity, compliance, and privacy.
Distributing governance responsibilities across cross-functional teams helps to ensure that decision-making is inclusive and reflects diverse perspectives. This approach allows for a more agile and responsive governance framework, enabling faster problem-solving and reducing bottlenecks in the decision-making process.
Some ways to ensure effective federated computational governance include:
(Know the differences between data governance & data management.)
Now that you understand the key principles of a data mesh, let's look at some of the main benefits.
Clear ownership and accountability for data domains ensures that each team is responsible for the quality and accuracy of their own data, fostering a sense of ownership and pride. With shared understanding and collaboration across teams, knowledge can be freely exchanged, leading to more comprehensive insights and solutions.
Decentralized data management also enables faster decision-making by empowering teams to access and analyze relevant data directly.
A data mesh also enables organizations to increase the quality and availability of data.
Through a decentralized approach, each product team is responsible for ensuring that their own data sets are accurate and up to date. This reduces redundancy in the system and minimizes the risk of errors and inconsistencies in the data.
Here are some practices that can help in managing data quality in data mesh:
Data validation checks like these at the source ensure accurate and reliable data. This helps improve overall data quality and eliminates the need for time-consuming manual error detection.
Consistent data standards across different teams and systems also enhance collaboration and enable seamless integration of datasets. When everyone follows the same set of standards, it becomes easier to share and analyze data across various departments. This consistency eliminates confusion, reduces errors caused by incompatible formats, and improves overall efficiency.
Data mesh enables teams to quickly experiment with new ideas using self-serve analytics tools is a key aspect of increased innovation and agility in organizations. Here are some ways data mesh will boost innovation and agility:
These teams can then access and analyze data on their own, test hypotheses, iterate on solutions, and make informed decisions more rapidly.
Fast iteration cycles due to reduced reliance on centralized data pipelines allow teams to move swiftly from idea generation to implementation. Encouragement of creativity by enabling diverse perspectives on data usage drives innovation forward. When different team members have access to relevant data sets and are empowered to explore various angles, novel insights are discovered that may not have been possible otherwise.
A data mesh architecture enables faster insights! By parallel processing distributed datasets, teams can uncover valuable information more quickly and efficiently. Redundant storage eliminates single points of failure, ensuring that data is protected and accessible at all times.
Furthermore, changes or disruptions in one team's infrastructure have minimal impact on the operations of others, reducing dependencies and bottlenecks within the organization.
The introduction of a data mesh would, therefore, boost efficiencies.
Implementing data mesh can help an organization streamline data operations, access valuable insights faster, and foster cross-functional collaboration. However, putting a strategic plan in place ensures a smooth transition.
Here are some steps organizations can take when implementing a data mesh:
The first step in implementing data mesh is to define your goals and objectives. Creating an actionable roadmap with measurable success criteria will help ensure that data mesh initiatives are in line with organizational objectives.
It also helps to identify any potential roadblocks or challenges, allowing teams to plan ahead and take proactive measures.
Analyzing existing team structures is the next step in identifying domain-driven teams. This helps you to be aware of your current organization's composition, strengths, and weaknesses and assign them according to their domain expertise.
Mapping business functions to data domains allows us to understand which teams are responsible for specific data sets and processes. This mapping helps ensure that each team clearly understands their role and responsibilities within the larger ecosystem of distributed data management.
Defining ownership roles and responsibilities is crucial in establishing data product ownership. Teams can effectively manage and govern their data products by clearly outlining who is responsible for each data domain.
Assigning product owners to oversee specific domains ensures a focused approach to decision-making and accountability. This clarity in roles promotes efficiency and empowers cross-functional teams to take ownership of their respective areas within the data mesh framework.
Working towards a self-serve data culture involves building infrastructure that encourages it too. To empower cross-functional teams with distributed data management, organizations must focus on:
These efforts not only enhance productivity but also foster a collaborative environment where teams can leverage the power of data without unnecessary dependencies.
Establishing data sharing and collaboration policies is also crucial in implementing federated computational governance.
With clearly defined guidelines and procedures, teams can efficiently exchange data and work collaboratively across domains. This ensures that the right information reaches the right people, promoting effective decision-making and innovation.
Fostering a culture of transparency, trust, and accountability is essential for successful implementation of federated computational governance. Here are some examples:
To wrap up, data mesh is a valuable approach for organizations looking to improve their data operations, access insights faster, and promote collaboration. This modern approach to data architecture provides benefits such as an empowered team, better data quality, faster innovation, and fewer bottlenecks.
If your organization is looking to transition to data mesh, make sure you define your goals and objectives first, identify domain-driven teams, establish product ownership roles, build a self-serve data infrastructure, and implement federated computational governance.
See an error or have a suggestion? Please let us know by emailing splunkblogs@cisco.com.
This posting does not necessarily represent Splunk's position, strategies or opinion.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.