
Splunk ITSI for AIOps
Discover our industry-leading approach to AIOps & monitoring.
Splunk is committed to using inclusive and unbiased language. This blog post might contain terminology that we no longer use. For more information on our updated terminology and our stance on biased language, please visit our blog post. We appreciate your understanding as we work towards making our community more inclusive for everyone.
Splunk IT Service Intelligence (ITSI) Event Analytics is responsible for ingesting events from multiple data sources and creating and managing notable events. A “notable event” is an enriched event containing metadata to help you investigate issues in your IT environment.
Event Analytics is equipped to handle “event storms," or huge numbers of events coming in at once. Because these events might be related to each other, they must be grouped together so you can identify the underlying problem. Event Analytics provides an elegant and simple way to deal with this huge volume and variety of events.
Splunk ITSI automatically groups notable events into episodes and organizes them in Episode Review. An “episode” is a collection of notable events that are grouped together based on predefined rules. You can manage the properties of episodes and determine which services are impacted by each one. You can also browse the history of similar episodes to find out what worked to resolve them, and configure automated actions to take on certain types of episodes.
The Event Analytics SDK is shipped with Splunk ITSI to help you manage episodes and create custom episode actions programmatically. You can leverage the SDK to easily build a Data-to-Everything Platform.
Splunk ITSI Event Analytics is designed to make event storms manageable and actionable. After data is ingested into ITSI from multiple data sources, events proceed through the following workflow:
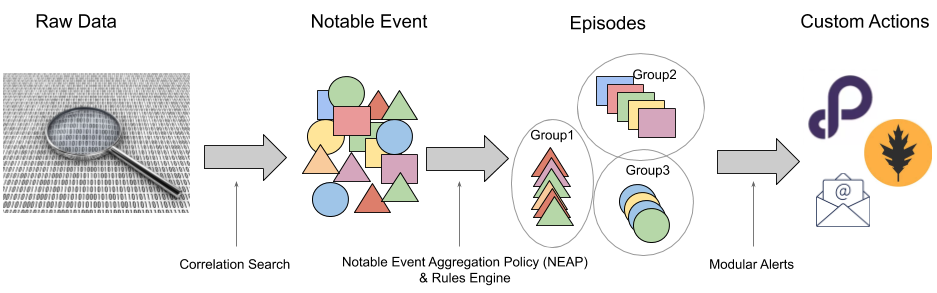
The data itself comes from Splunk indexes, but ITSI only focuses on a subset of all Splunk Enterprise data. This subset is generated by correlation searches. A correlation searches is a specific type of saved search that generates notable events from the search results.
Once notable events start coming in, they need to be organized so you can start gaining value from them. That’s where notable event aggregation policies come into play. A notable event aggregation policies determines which notable events are related to each other and groups them into episodes. Therefore, an episode contains a chronological sequence of events that tells a story. In the backend, a component called the Rules Engine executes the aggregation policies you configure.
You can run actions on episodes either automatically or manually. Some actions, like sending an email or pinging a host, are shipped with Splunk ITSI. You can also create tickets in external ticketing systems like ServiceNow, Remedy, or VictorOps. Finally, actions can also be modular alerts that are shipped with Splunk add-ons or apps, or custom actions that you configure. For more information, see "Take action on an episode in ITSI."
An episode represents a group of events occurring as part of a larger sequence (an incident or period considered in isolation). It has certain properties that you can configure, such as its severity, status, assignee, and title.
You can also configure specific automated actions to be taken on each episode created by an aggregation policy. For example, perhaps when an aggregation policy creates an episode, you want to automatically link the episode to an external ticketing system like ServiceNow, add certain comments to the episode, and send an email to specific people. You can configure each of these actions as separate “action rules” for that aggregation policy.
Customize alert actions so you can do everything necessary to react when certain properties of an episode change, or when specific types of events are added to an episode.
In summary, notable event aggregation policies define the following rules:
The Splunk ITSI Notable Event Actions SDK helps you manage episodes and events programmatically. The SDK currently shipped with ITSI has the following capabilities:
To use the Notable Event Actions SDK, you must first install ITSI. Then import the SDK libraries using the following code:
# Add path of ITSI Event Management SDK
from splunk.clilib.bundle_paths import make_splunkhome_path
sys.path.append(make_splunkhome_path(['etc', 'apps', 'SA-ITOA', 'lib']))
# EventGroup is the object to manage episodes
from itsi.event_management.sdk.grouping import EventGroup
# CustomEventActionBase is a base class of actions which contains util functions
from itsi.event_management.sdk.custom_group_action_base import CustomGroupActionBase
The code imports two classes: EventGroup and CustomGroupActionBase
Use the EventGroup class to manage episodes. For example, change episode properties, run predefined actions like linking external tickets or adding comments, and so on. The operations in EventGroup can also be bulk operations, allowing you to update several episodes with a single function.
For example, the following code closes three episodes at once:
STATUS_CLOSED = '5' # '5' is the code of 'episode closed'
itsi_episode = EventGroup(self.get_session_key(), logger)
itsi_episode.update_status(['episode_id1', 'episode_id2', 'episode_id3'], STATUS_CLOSED)
The CustomGroupActionBase class helps you create custom episode actions. It provides an interface to retrieve episode information in the Splunk modular alert code. To create a custom action, inherit from the CustomGroupActionBase class and then use the get_group() function to retrieve the episode information. For example:
class ServiceChecker(CustomGroupActionBase):
def __init__(self, settings):
super(ServiceChecker, self).__init__(settings, logger)
def execute(self):
try:
for data in self.get_group():
if isinstance(data, Exception):
# Generator can yield an Exception here
logger.error(data)
raise data
if not data.get('itsi_group_id'):
logger.warning('Event does not have an `itsi_group_id`. No-op.')
continue
group_id = data.get('itsi_group_id')
group_title = data.get('title')
# Do something with group_id and group_title
...
except Exception as e:
...
Using the CustomGroupActionBase class as the base class, implement the execute() function. It’s important to note that the action might not necessarily be taken on just one episode because ITSI supports bulk episode actions. The get_group() function returns a generator that allows you to iterate through all episodes.
The following example uses Splunk ITSI Event Analytics to automate event management:
Overview
Suppose you’re a system administrator who has a web server cluster running a critical service for your company, and you want to catch all errors in the Splunk server logs. You don’t want the alerts to flood your inbox and you don’t want the rate of errors to be too high to manage.
You also want to avoid false positives by performing some type of check before sending an email alert.
Let’s see how Event Analytics can ease the event management workflow.
First, you set up a forwarder to send log events to Splunk Enterprise and save them into an apache index.
The first step to get ITSI to catch the error events is to create a correlation search that runs every minute. Configure the correlation search to generate one notable event for every log line with a log level of SEVERE or ERROR.
Set the title and description of the notable events to be the field values from the original log with %field_value% annotation:
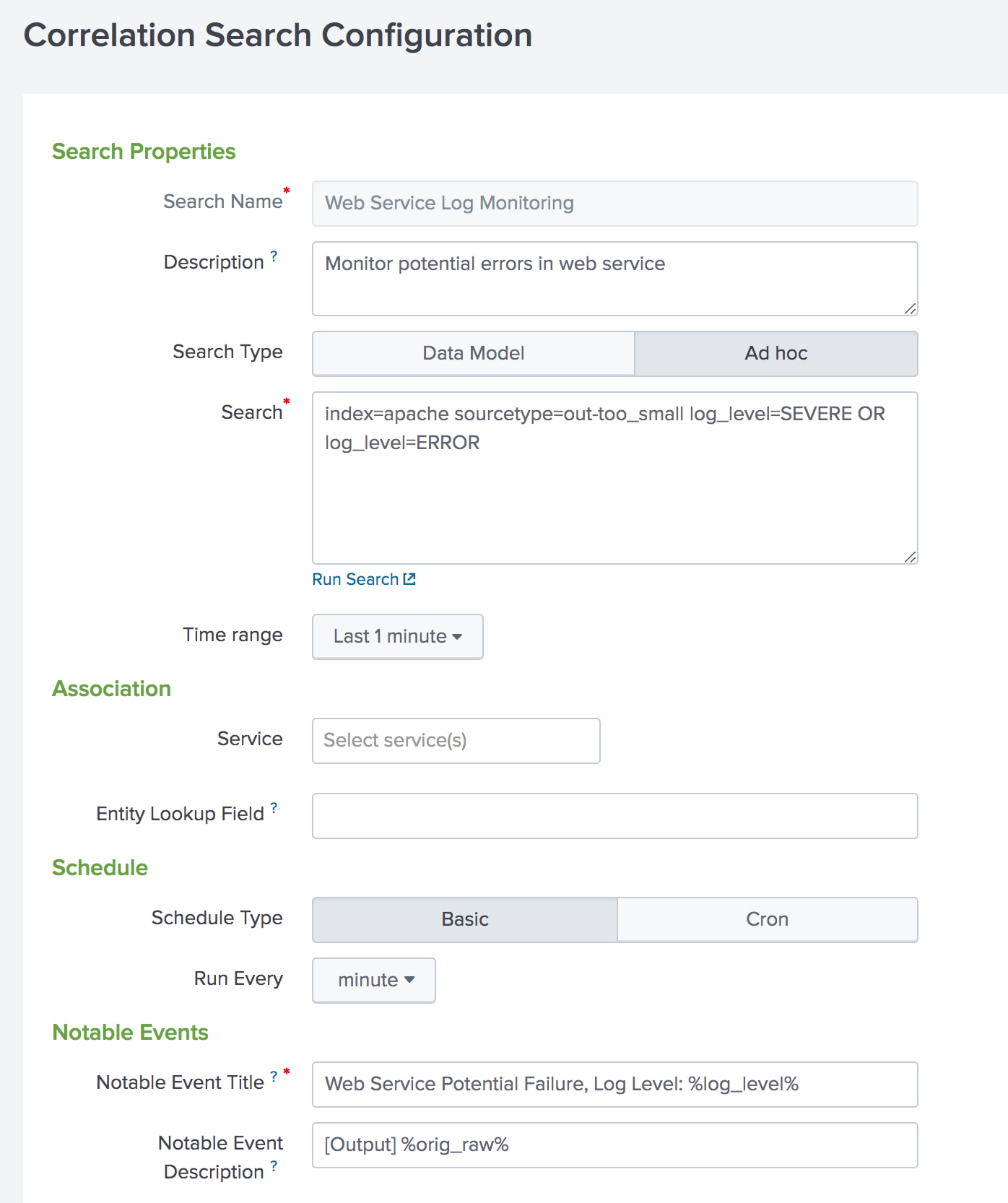
For more information about creating correlation searches, see "Configure correlation searches in ITSI" in the Administer Splunk IT Service Intelligence manual.
Now you want to configure some rules to throttle the flood of events so you only react to true failures. This is the exact purpose of notable event aggregation policies.
For every error log line from the web service, you want to verify if it’s a positive failure by sending a request to a REST endpoint of the server that generated the error log. You want to receive an email alert for every positive failure. However, since you don’t want to get buried in a flood of emails, you want to receive no more than one email every 30 minutes.
Before configuring the aggregation policy, you create a custom alert action using the ITSI Event Analytics SDK to automate the process of checking and sending emails. It’s a best practice to create a separate Splunk app for the custom alert action. For an example of creating custom alert actions, see the "Create a custom ITSI alert to check your web service"example on GitHub.
From the source code of itsi_service_checker.py, the main business logic is implemented in the execute() function:
for data in self.get_group():
...
# Check web service
if self.check_service(service_url):
groups_passed.append(group_id)
itsi_episode.create_comment(group_id,
'Service check successfully for `%s`,closing it.' % group_title)
else:
groups_failed.append(group_id)
itsi_episode.create_comment(group_id,
'Service check failed for `%s`, putting it in-progress.' % group_title)
if groups_passed:
itsi_episode.update_status(groups_passed, STATUS_CLOSED)
if groups_failed:
itsi_episode.update_status(groups_failed, STATUS_INPROGRESS)
self.send_email(groups_failed, email_addr,
"%s Episodes Failed for Service Check" % len(groups_failed),
"See attachment for relevant events")
Using the above code, you can control an episode’s state and send an email by the results of the SDK. The following rules apply:
After you create the custom action, configure the following notable event aggregation policy to automate the action:
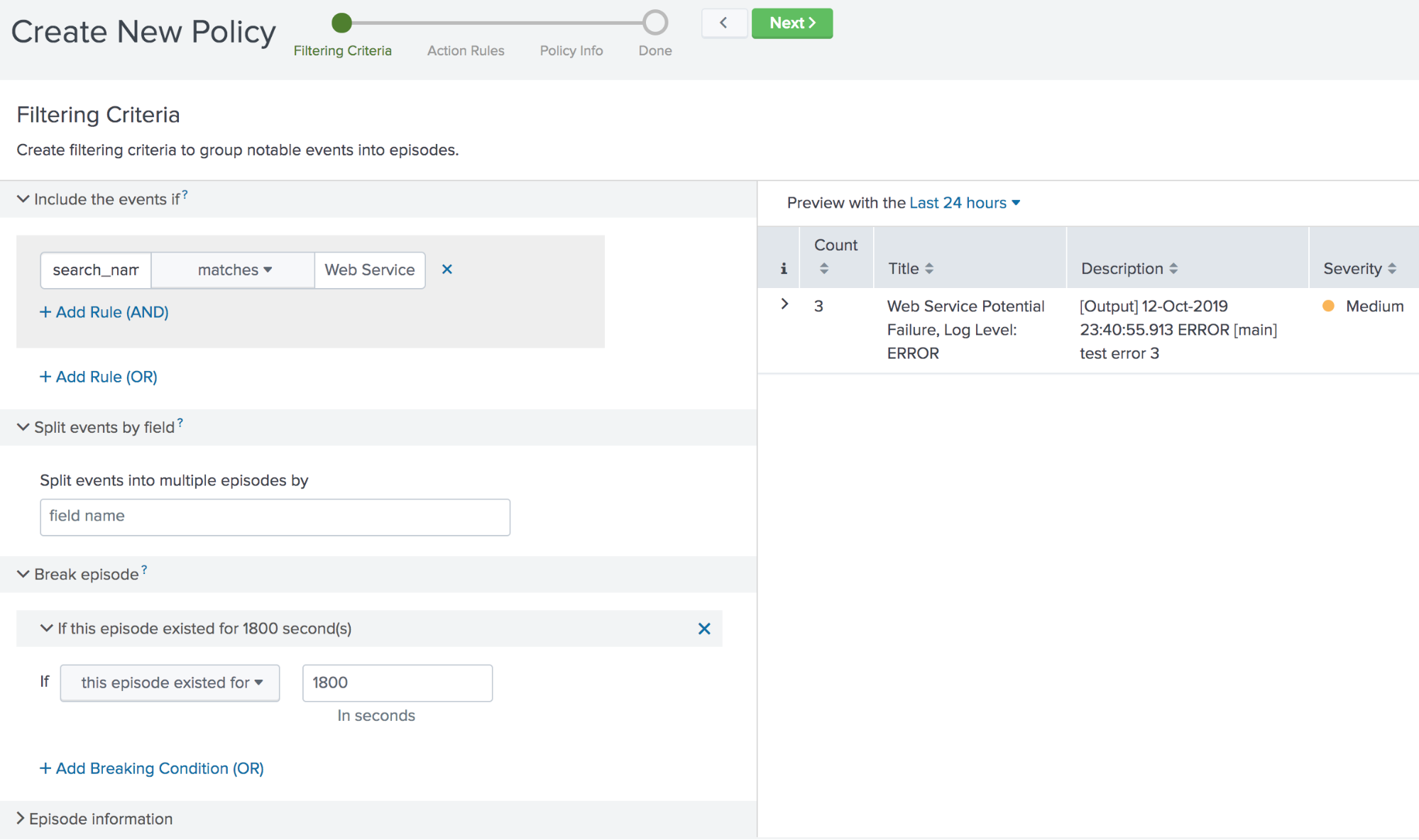
For the filtering criteria, use search_name matches Web Service Log Monitoring (the name of the correlation search you created) so the policy looks specifically at the web service log.
Set the breaking criteria to If this episode existed for 1800 seconds (30 minutes) to control the rate at which episodes are generated.
Click Next to move to the action rules. The first time an event is added to an episode, you want to check the web service.
You configure the following action rule:
If the number of events in this episode is exactly equal to 1, then Check Web Service for the episode
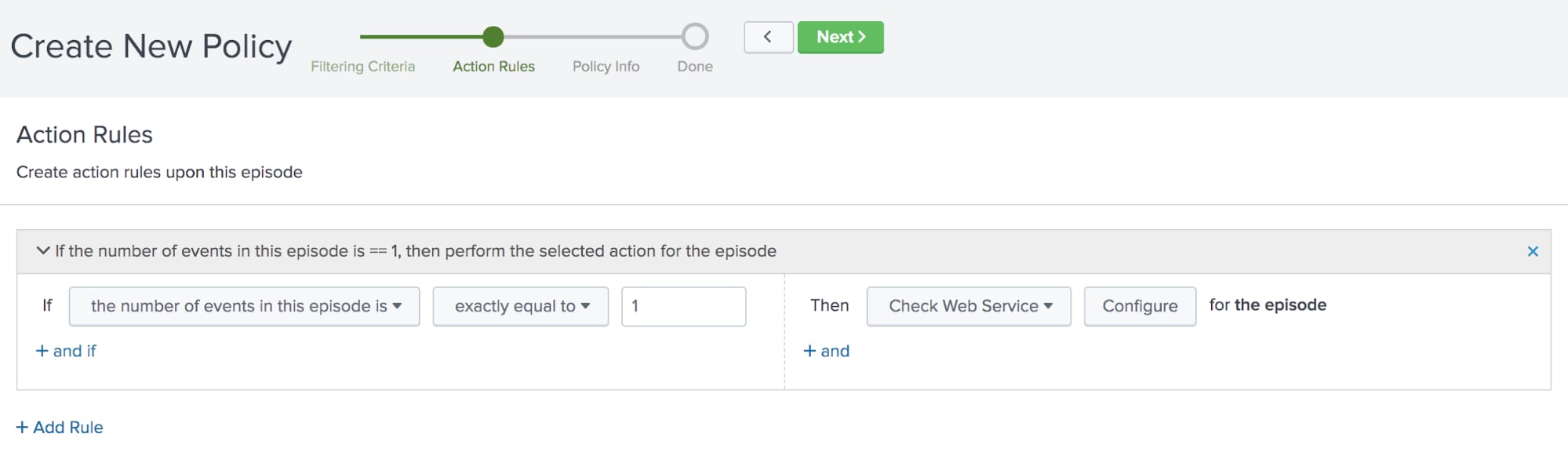
Click Configure and provide the web service URL and the email to send the alert to.
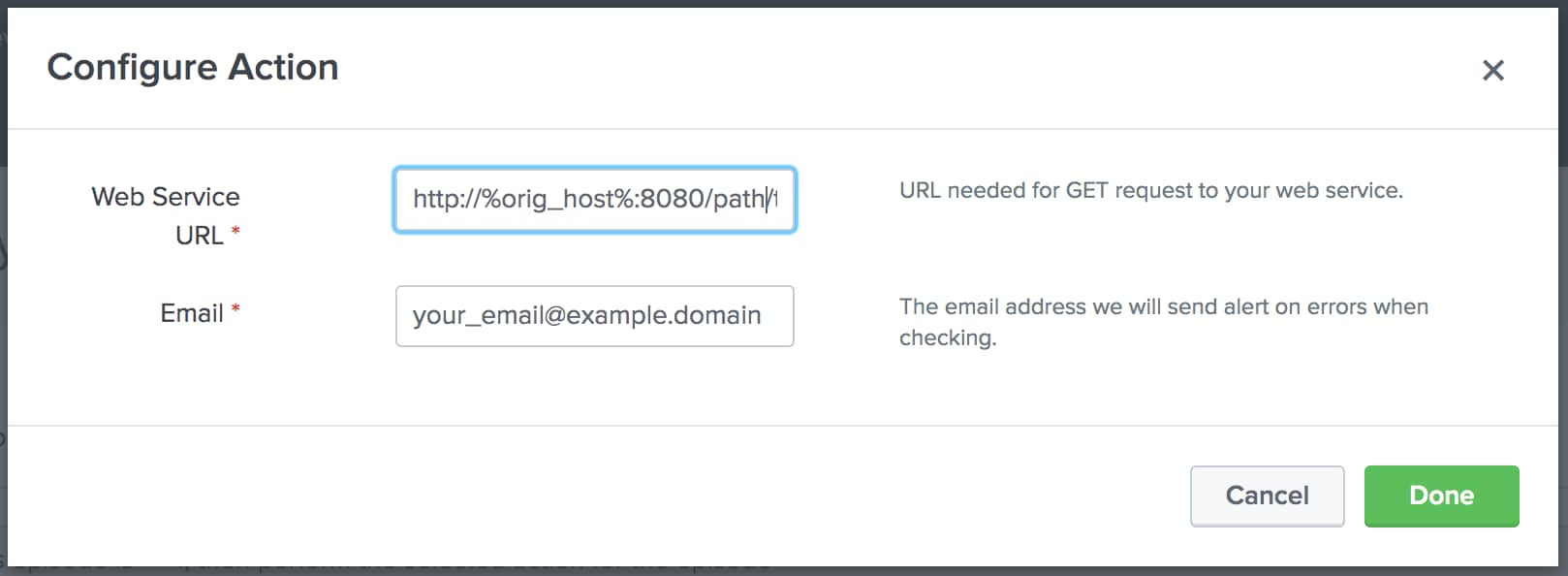
The URL in the image above contains %orig_host% which refers to the host that generated the error log event. ITSI uses %field_value% as the variable for the field that’s evaluated when the action runs. You can also use a static value, like the load balancer’s endpoint, if you just want to test if the clustered service is running.
Click Next and provide a title and description of the aggregation policy. Choose whether it should be enabled or disabled upon saving.
Click Next to save the aggregation policy. Now you’ll only receive an email when a true failure occurs, so you don’t have to worry about alerts flooding your inbox.
For more information about creating aggregation policies, see "Create a custom aggregation policy in ITSI."
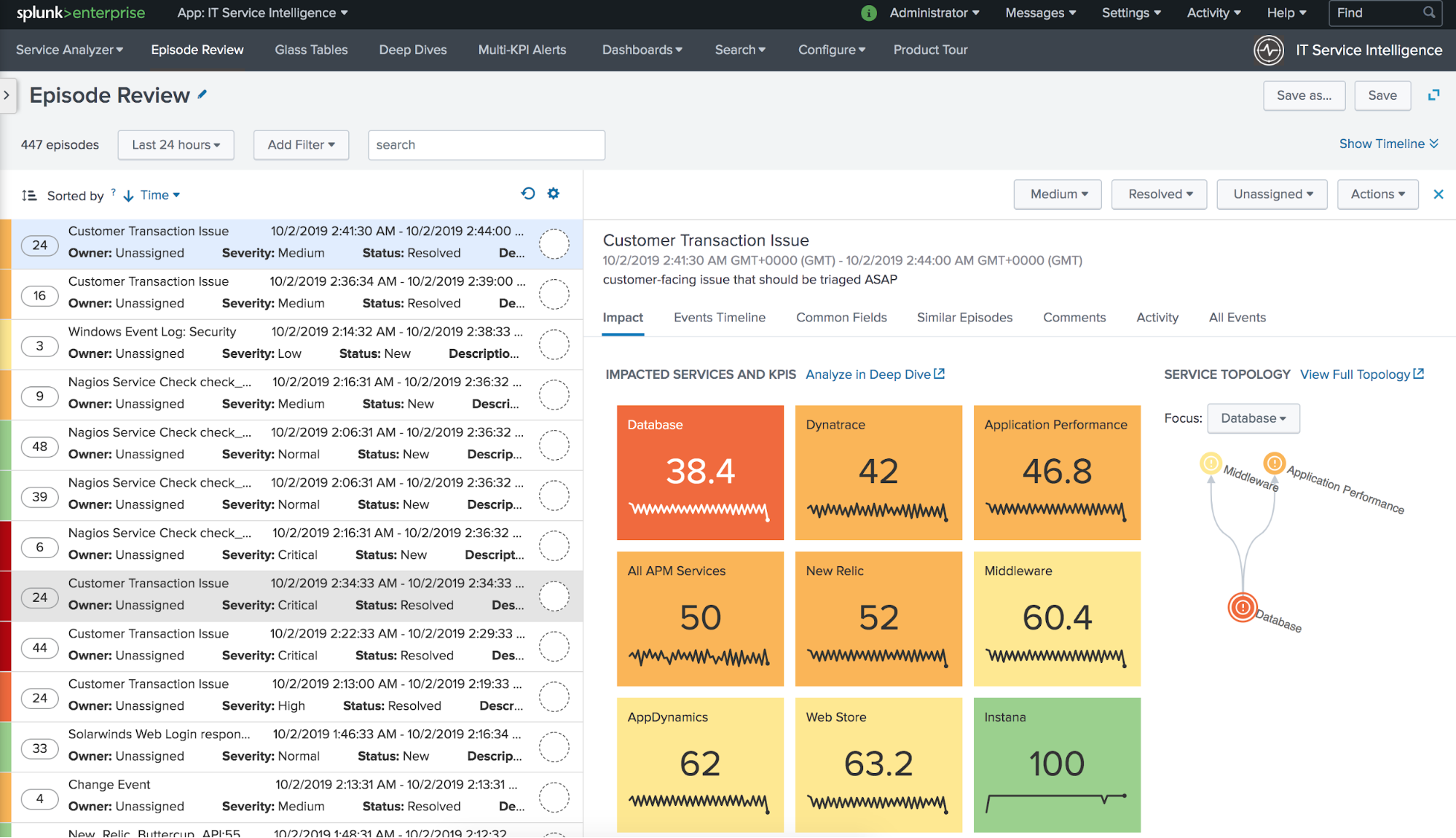
To start seeing episodes related to the policy you just created, navigate to Episode Review and filter by status and the correlation search name:
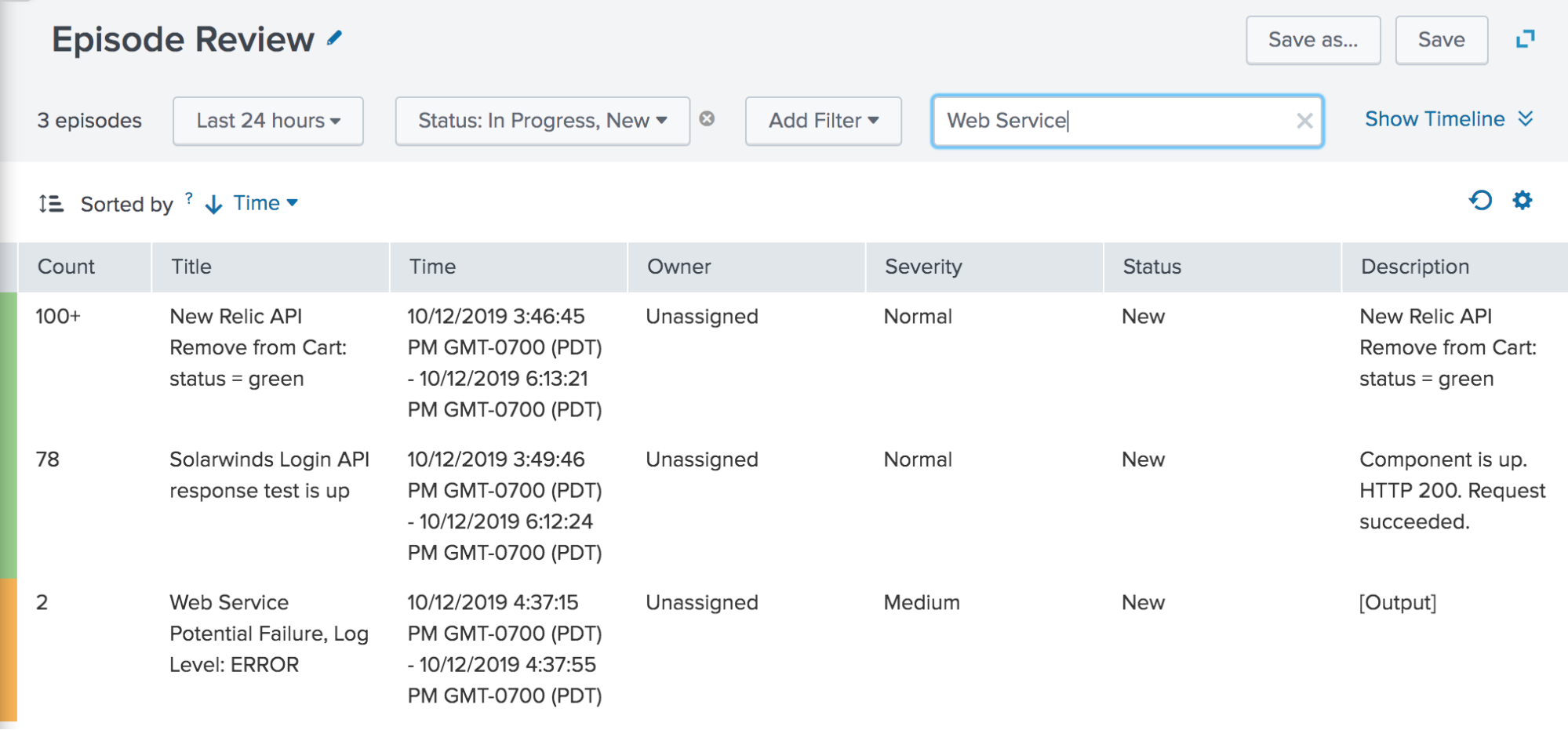
ITSI Event Analytics provides automated tools to help you control event storms and get actionable insights about your data. It’s not only useful for IT operations teams, but can also apply to all data managed by Splunk Enterprise. Use Event Analytics to automatically manage, organize, and take action on issues in your IT environment. Start your free Splunk Enterprise trial today!
----------------------------------------------------
Thanks!
Samuel Zhou

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
