
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

If you're already excited about Apache Pulsar (like we are), then prepare to get really excited, because a new feature is coming that will open up bold new horizons for the future of both Pulsar and the entire messaging space: Pulsar Functions, a lightweight compute framework for Pulsar inspired by stream processing engines like Heron and Function as a Service platforms like AWS Lambda and Google Cloud Functions. Pulsar Functions enables you to easily deploy and manage processing functions that consume messages from and publish messages to Pulsar topics.
Pulsar has already been gaining significant traction in the messaging space over the last few months for a variety of reasons: it's the only open source messaging platform that unifies queuing and streaming, was built to be multi tenant from the ground up, offers multi-datacenter geo-replication out of the box, guarantees effectively-once message delivery semantics, and much more.
With the introduction of Pulsar Functions, you can now use Pulsar as an all-in-one messaging/compute/storage system. Just deploy a Pulsar cluster and you have a ready-made compute engine with a simple interface at your disposal.
Pulsar Functions essentially enables you to write processing functions using either Java or Python (more languages to come later) and easily deploy those functions. Initially, that will involve two possible modes:
When you deploy functions in cluster mode, state storage will be automatically handled by Apache BookKeeper.
At the moment, you can use Pulsar with just about any compute or stream processing engine (SPE) that you like, such as Heron. The beauty of Pulsar Functions, though, is that you can have the benefits of an SPE without needing to deploy one.
If you've ever wanted to perform simple processing of data from your message bus but didn’t want to stand up and configure a whole stream processing cluster to do so, Pulsar Functions is the solution for you. With an extremely simple API, users can consume data from Pulsar topics, process the data using custom-built logic, and, if necessary, write results back into other Pulsar topics. In Java, for example, a user can simply implement the java.util.function.Function interface, which has just a single apply method. Here's an example:
import java.util.Function;
public class ExclamationFunction implements Function<String, String> {
@Override
public String apply(String input) { return String.format("%s!", input); }
}
In its simplest form, you don’t even need an SDK to implement a Pulsar Function! If the user needs context-related information, such as the name of the function, the user can just implement the PulsarFunction interface instead of the Java Function interface. Here's an example:
public interface PulsarFunction<I, O> {
O process(I input, Context context) throws Exception;
}
That's it!
As you can probably tell from the API, we decided to call this framework Pulsar Functions because it is literally just a function. Extremely simple and straightforward.
Users can either run a Pulsar Function via "local run" mode, which means that the user determines where the function runs (for example on their laptop),or users can submit a Pulsar Function to a Pulsar cluster and the cluster will take charge of running the function. We will discuss both modes in detail later in this post.
For now, let's discuss Pulsar Functions in a bit more detail. In the following sections, we'll provide some background information on Pulsar Functions and why we decided to develop this feature along with an overview of the Pulsar Functions runtime.
From the experiences we had in the industry, we've noticed that a significant portion of data processing use cases are simple and lightweight. Such use cases include:
We developed Pulsar Functions not only to address such use cases, but also, and more importantly, to greatly simplify deployment, reduce development time, and maximize developer productivity. We put special emphasis on simplicity due to the feedback we often get from users in the industry. We became aware of several major pain points that were plaguing users again and again:
With this feedback in mind, we outlined several goals for the design of Pulsar Functions:
| Goal | Description |
|---|---|
| Provide the simplest API available and maximize productivity | This is the overarching, guiding goal. Anyone with the ability to write a function in a supported language should be able to be productive in a matter of minutes. |
| Multi-language support | We should provide the API in at least the most popular languages: Java, Scala, Python, Go, and JavaScript. |
| Flexible runtime deployment | Users should be able to run Pulsar Functions as a simple process using their favorite management tools. They should also be able to submit their functions to be run in a Pulsar cluster. |
| Flexible invocation | Thread-based, process-based, and Docker-based invocation should be supported for running each function |
| Built-in state management | Computations should be allowed to keep state across computations. The system should take care of persisting this state in a robust manner. Basic things like incrementBy, get, put, and update functionality are a must. This dramatically simplifies the architecture for the developer. |
| Queryable state | The state written by a function should be queryable using standard REST APIs. |
| Automatic load balancing | The managed runtime should take care of assigning workers to the functions |
| Scale up and down | Users should be able to scale the number of function instances up and down using the managed runtime. |
| Metrics | Basic metrics, such as events processed per second, failures, latency, etc. should be made available on a per-function basis. Users should also be able to publish their own custom metrics. |
With these goals in mind, we developed the Pulsar Functions runtime to be the following.
Pulsar Functions are run by executors called instances. A single instance executes one copy of the function. Pulsar Functions have parallelism built in because a function can have many instances, the number of which can be set in the function's configuration.
To maximize deployment flexibility, the Pulsar Functions feature incorporates several execution environments and runtimes. The following execution environments are supported at the outset (with more likely to come later):
| Runtime | Description |
|---|---|
| Process runtime | Each instance is run as a process. |
| Docker runtime | Each instance is run as a Docker container |
| Threaded runtime | Each instance is run as a thread. This type is applicable only to Java instances since the Pulsar Functions framework itself is written in Java. |
Each execution environment incurs different costs and provides different isolation guarantees.
Pulsar Functions also provides a number of runtimes to execute functions written in different programming languages. Pulsar Functions currently supports only Java and Python, but many more languages will be added in the future!
Figure 1 below depicts the runtime for Pulsar Functions.
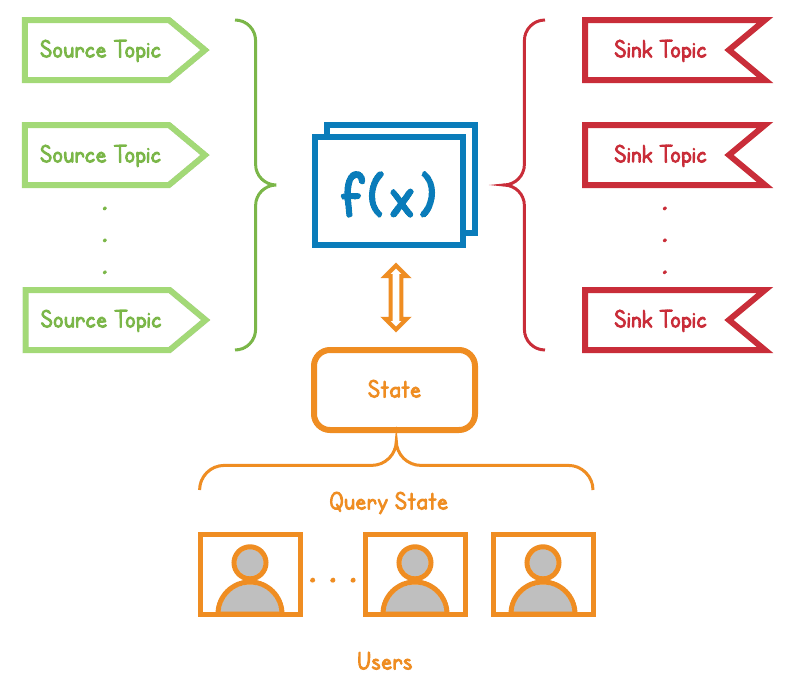 Figure 1. Pulsar Functions runtime diagram
Figure 1. Pulsar Functions runtime diagram
A Pulsar Function can consume from one or more Pulsar topics and, optionally, write results back to one more Pulsar topics. There are one or more instances of a Pulsar Function executing the processing logic defined by the user. A function can use the provided state interface to persist intermediate results. Other users can query the state of the function to extract these results.
The easiest way to run a Pulsar Function is to instantiate a runtime and a function and run them locally (local run mode). A helper command-line tool makes this very simple. In local run mode, the function runs as a standalone runtime and can be monitored and controlled by any process, Docker container, or thread control mechanisms available. Users can spawn these runtimes across machines manually or use sophisticated schedulers like Mesos/Kubernetes to distribute them across a cluster. Below is an example of the command to start a Pulsar function in “localrun” mode:
$ bin/pulsar-admin functions localrun \ --inputs persistent://sample/standalone/ns1/test_src \ --output persistent://sample/standalone/ns1/test_result \ --jar examples/api-examples.jar \ --className org.apache.pulsar.functions.api.examples.ExclamationFunction
A user can also run a function inside the Pulsar cluster alongside the broker. In this mode, users can ‘submit’ their functions to a running pulsar cluster and Pulsar will take care of distributing them across the cluster and monitoring and executing them. This model allows developers to focus on writing their functions and not worry about managing a functions life cycle. Below is an example of submitting a Pulsar function to be run in a Pulsar cluster:
$ bin/pulsar-admin functions create \ --inputs persistent://sample/standalone/ns1/test_src \ --output persistent://sample/standalone/ns1/test_result \ --jar examples/api-examples.jar \ --className org.apache.pulsar.functions.api.examples.ExclamationFunction \ --name myFunction
Another option is to place the entire configuration for the function in a YAML file, like this:
inputs: persistent://sample/standalone/ns1/test_src output: persistent://sample/standalone/ns1/test_result jar: examples/api-examples.jar className: org.apache.pulsar.functions.api.examples.ExclamationFunction name: myFunction
If you configure a function via YAML, you can use this much simpler create command:
$ bin/pulsar-admin functions create \ --configFile ./my-function-config.yaml
Pulsar Functions offer the following processing semantics, which can be specified on a per-function basis:
Check out our previous blog post for a more detailed discussion of the differences between these processing semantics.
Effectively-once processing is essentially achieved using a combination of at-least-once processing and server-side message deduplication. This means that a state update can happen twice, but that state update will only be applied once, while any duplicated state are discarded at the server side.
Here are some of the features that likely follow the initial Pulsar Function implementation in the coming months:
In this introductory post, we hope to have piqued your interest in Pulsar Functions. Please stay tuned for follow-up blog posts on Pulsar Functions that will cover individual components and features in more depth. In the meantime, check out some of our other recent posts about Pulsar:
This post features contributions from Jerry Peng, Sanjeev Kulkarni, and Sijie Guo.
----------------------------------------------------
Thanks!
Jerry Peng

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
