
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
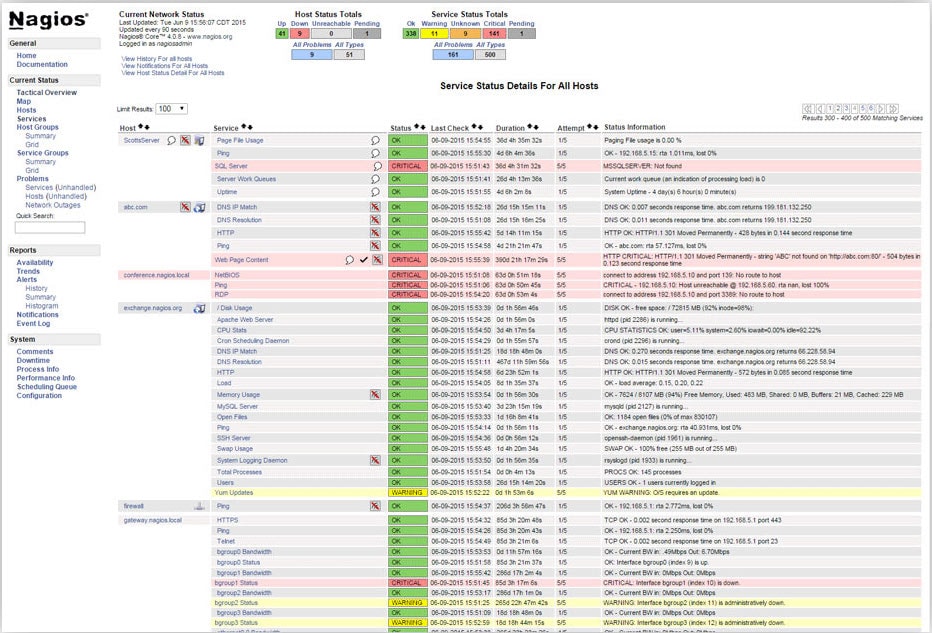
When we started SignalFx, we needed a monitoring system in place while we wrote the SignalFx system. So we did the easiest, most reliable and cost-efficient route we could think of at the time: we put Nagios in place to monitor our infrastructure and services deployed on AWS infrastructure. However, while Nagios initially provided a reliable health check of our environment, our team realized key reasons of how managing and maintaining Nagios outweighed the benefits of the tool.
This is the first post in a series on how SignalFx moved to an active monitoring system and disconnected Nagios from our alerting strategy. We’ll start by covering the key challenges faced in running two monitoring systems and highlight why Nagios became insufficient for monitoring all our environments, including critical production systems. In future posts, we’ll cover how we consolidated to one monitoring system with confidence and the benefits we experienced from the process.
At the time, using Nagios to monitor our growing infrastructure made sense:
In the beginning, Nagios worked quite well for us. Our engineers could quickly evaluate the health status of the environment based on the pulling of simple metrics by Nagios. If a node or component failed to respond to a ping or behaved out of the ordinary, the team could be notified and respond accordingly.
However, as the SignalFx monitoring platform matured, the complexity of the system and number of components – from infrastructure nodes to different services – continued to increase. This necessitated in the use of more intelligent alerting – from creating alerts based on correlations from multiple outliers sourced from different services to ones based on running analytics against outlier data to distill the underlying problem from the alert noise.
Our engineers also needed a dynamic presentation layer to more easily troubleshoot issues in the SignalFx product. For example, many wanted the ability to look at trends over a period of time and do comparisons. Neither of these features were readily available in Nagios, but could be easily accessed in the SignalFx product. We took our own experiences of what we required for a monitoring system and, as we built out SignalFx, continued to increase our usage of the product. However, as the shortcomings of available Nagios features inhibited our ability to confidently monitor our growing infrastructure, we eventually reached a point where we were on the verge of neglecting Nagios.
Maintaining two monitoring systems, Nagios and SignalFx, required significant time and resources of our team. As a result, we neglected Nagios, and this ended up creating more challenges than we had originally anticipated.
While it was easy to get started, Nagios was quite cumbersome to maintain. The Nagios configuration became increasingly confusing given the complexities of monitoring a highly scalable, distributed system built on a microservices architecture. In addition, the files we needed to maintain Nagios configuration were in a centralized directory of our SaltStack git repo that was separate from our service configuration files. This meant that every time we set up a new service or added monitoring to an existing service, we had to remember to go to two different directories in our SaltStack and to navigate two very different directory structures. While this wasn’t difficult to do, it definitely required us to remember to do two different types of configuration and directory hierarchies, which was not efficient and is easy to forget.
Built on a component-centric model, Nagios required manual configuration each time a new resource is added or removed – specific IP addresses for a specific component were defined for every new machine entering or exiting the environment. We had some of this automated but not in a way that would guarantee accurate alerts. While it’s possible to temporarily mute Nagios alerts for hosts/services undergoing maintenance, our engineers had to remember to do that in the first place via the Nagios UI. This was partially due to the fact that we had not invested in incorporating the Nagios API into our environment orchestrator. It was clear when someone simply forgot to take this step: several false alerts fired, much to the annoyance of the team.
Example of Service Status Summary Page for All Hosts in Nagios UI
Nagios also had the issue of alerting too much and not enough at the same time, and without a dedicated engineer to manage Nagios, its alerting began to be unreliable and somewhat of a nuisance. We’d receive both late alerts for things we already knew about or noisy alerts that seemed to be completely invalid. Unfortunately, this created a lack of trust in the alerts Nagios fired. So it was clear we had come to an important point – it was time to evaluate the way we were using Nagios.
As we investigated how and where we were using Nagios, it became clear the many ways to improve our usage of Nagios.
Among many other areas, we relied too much on the UI. We set up our initial implementation and did not track Nagios feature development beyond that. As a consequence, we barely used the Nagios API and had not integrated it into any of our infrastructure/developer tools.
We also needed to get reacquainted with what Nagios was actually doing. Because we had not been consistently updating and tuning the health checks in Nagios, we needed to do a full audit of our entire monitoring system to identify exactly which health checks Nagios covered and which it missed. We had began to notice from simply watching charts setup to monitor various aspects of component health that we were catching down components or hosts before Nagios issued an alert. This was unacceptable for us as we knew we needed to guarantee service availability for our customers.
We wrote plugins for most of our platform services when we originally deployed Nagios. As these services matured, updating these plugins for more sophisticated monitoring became a maintenance challenge. We did not have the desire to invest in these updates as the engineers were organically building these features into our internal monitoring using SignalFx.
However, as we evaluated the time it would take to invest in each of these areas of improvement, we naturally did not want to invest significant effort into maintaining two different monitoring systems to achieve the single purpose of monitoring our platform. We considered whether it was worth the time to see whether we could consolidate into one monitoring solution. Naturally, the path of least resistance was to see whether we could simply disconnect and replace Nagios.
The first step in the process was to do a thorough audit of what we currently had in place and what we needed to do to improve it. Based on that audit, we found that we needed to address the following issues:
While some of these issues could be addressed by simply putting more care and effort into Nagios, was it worth more engineering time and resource to put effort into it? To determine the answer to that question, we compared the alerts set up for Nagios with those set up with SignalFx. We discovered that there were duplicates of most every Nagios alerts with our system. And so, we were unknowingly already on our way to consolidation.
In the next post, we will cover the audit we conducted on our two monitoring systems and how we addressed the overlapping coverage areas.
----------------------------------------------------
Thanks!
jessica-feng

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
