
Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.
Splunk is proud to announce the release of Splunk Connect for Kafka. Leveraging the Apache Kafka Connect framework, this release is set to replace the long-serving Splunk Add-on for Kafka as the official means of integrating your Kafka and Splunk deployments. For more information on the release, please visit Michael Lin's blog post “Unleashing Data Ingestion from Apache Kafka”.
Today, we'll be looking at what Splunk Connect for Kafka is, as well as detailing the installation, configuration and deployment of the connector.
Apache Kafka’s rise to center stage in the data-centric world of the enterprise has been colossal. It's advanced the concept of the publish/subscribe message bus to a fast, fault-tolerant technology that's used for data pipelines and streaming data between services. Companies are leveraging Apache Kafka’s strengths to build the next generation of streaming applications. Kafka Connect was born out of a need to integrate these different services with Kafka in a repeatable and scalable way—it takes the complexity out of consuming topic data by providing an easy-to-use tool for building, deploying and managing integrations.
On the simplest level, data goes in to Kafka and data comes out of Kafka. Relating these concepts back to Kafka Connect leads us to Source and Sink Connectors. Source Connectors are used to import data from systems into Kafka, while Sink Connectors are used to export out.
Spunk Connect for Kafka is a “sink connector” built on the Kafka Connect framework for exporting data from Kafka topics into Splunk. With a focus on speed and reliability, included inside the connnecter is a scalable and very configurable Splunk HTTP Event Collector Client for sending messages to the largest of Splunk environments.
Okay, enough of the spiel. How do I get the connector configured and deployed?
We have two key decisions to make about how we want to send events to Splunk.
Acknowledgement vs. No Acknowledgement
As part of the Connector design we have built in end-to-end acknowledgement which can guarantee at least once delivery. The extra layer of acknowledgment—on top of HTTP Event Collector’s built-in reliability—can protect against any indexer load or network reliability issues in your environment. If speed is the priority, then No Acknowledgement would be the better choice.
HTTP Event Collector Raw vs. JSON Event Endpoint
HTTP Event Collector has two endpoints to ingest events. Using the raw endpoint has shown to net higher throughput for raw speed, where using the JSON event endpoint can allow for extra meta-data fields to be appended to events to enable greater flexibility in searching for events in Splunk after ingested.
We will touch back on these options during the configuration section.
Configuring Splunk to ingest Kafka topic data is as simple as configuring a valid HEC token across all the Splunk receiving nodes. We see different configurations for HEC in the wild, including sending events to HEC via a Collection Tier (Using Heavy Forwarders) or directly to Splunk’s indexing tier. Both are valid configurations, however, we have seen the best results achieved sending Kafka events straight to the index tier.
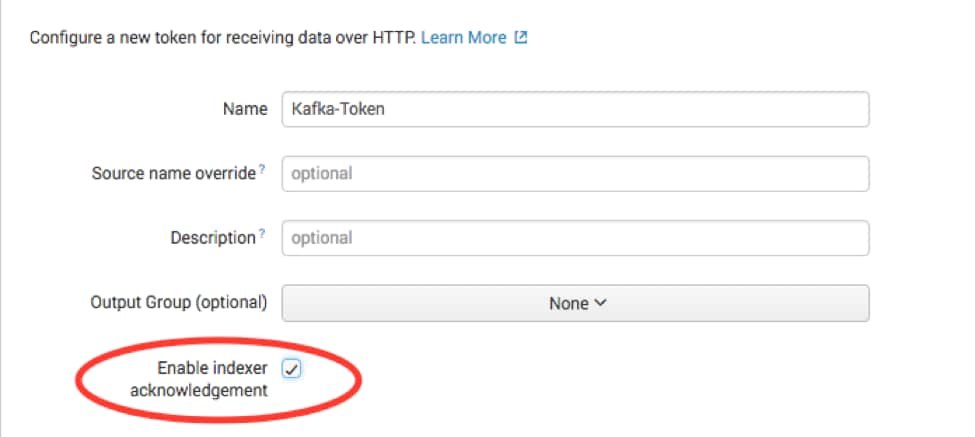
Before we can send the Splunk Connect for Kafka to deliver data to Splunk, we need to set up Splunk HEC to receive the data. From Splunk Web, go to the Settings menu, choose Data inputs and choose HTTP Event Collector. Choose Global Settings, ensure All tokens is enabled and then choose Save. Next select New Token to create a new HEC endpoint and token.
Your decision earlier of ACK vs No ACK determines your configuration for Enable indexer acknowledgment. For Acknowledgement ensure it is selected, For No Acknowledgement do not check the box.
The next screen will prompt you for some options around source type, context and index.
Select the options based on the data you are ingesting from Kafka. That’s it from the Splunk side; take note of your HEC token as we’ll use that to configure the Splunk Connect for Kafka later.
For a larger distributed environment using Splunk’s Deployment Server, creating tokens for multiple servers may be a more efficient way of configuring your HEC token. For more information on distributed deployment, please visit the "High volume HTTP Event Collector data collection" documentation.
First, we need to get our hands on the packaged JAR file (see above) and install it across all Kafka Connect cluster nodes that will be running the Splunk connector. Kafka Connect has two modes of operation—Standalone mode and Distributed mode. We will be covering Distributed mode for the remainder of this walkthrough.
To start Kafka Connect we run the following command from the $KAFKA_CONNECT_HOME directory, accompanied with the worker properties file connect-distributed.properties.
./bin/connect-distributed.sh config/connect-distributed.properties
Kafka ships with a few default properties files, however the Splunk Connector requires the below worker properties to function correctly. connect-distributed.properties can be modified or a new properties file can be created.
#These settings may already be configured if you have deployed a connector in your Kafka Connect Environment
bootstrap.servers=<BOOTSTRAP_SERVERS>
plugin.path=<PLUGIN_PATH>
#Required
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
internal.key.converter=org.apache.kafka.connect.json.JsonConverter
internal.value.converter=org.apache.kafka.connect.json.JsonConverter
internal.key.converter.schemas.enable=false
internal.value.converter.schemas.enable=false
offset.flush.interval.ms=10000
#Recommended
group.id=kafka-connect-splunk-hec-sink
Note the two options that need some extra configuration:
More detail on worker properties files and extra configurations can be found here.
*Note: Kafka users still using Kafka Connect version 0.10, there's a different process to follow to configure connectors which requires adding files to the system’s Java Classpath. More details can be found here.
After we have our properties file configured and ready to go, we're now ready to deploy Kafka Connect. If we kept the same name for our properties file, this command will deploy Kafka Connect.
./bin/connect-distributed.sh config/connect-distributed.properties
This should be repeated across all servers in your Kafka Connect Cluster.
Now is a good time to check that the Splunk Connect for Kafka has been installed correctly and is ready to be deployed. Run the following command and note the results.
curl http://<KAFKA_CONNECT_HOST>:8083/connector-plugins
The response should have an entry named:
com.splunk.kafka.connect.SplunkSinkConnector.
If we get the correct response we are ready to proceed to the Instantiate connector section.
With the Kafka Connect cluster up and running with the required settings in properties files, we now manage our connectors and tasks via a REST interface. All REST calls only need to be completed against one host since the changes will propagate through the entire cluster.
At the start of this post we noted the two design decisions that are critical in the operation of Splunk Connect for Kafka—Acknowledgements and which endpoint to use. The configuration parameters for these are: splunk.hec.raw and splunk.hec.ack.enabled.
For the remainder of the “How To” we are going to configure the connector to use Acknowledgements and ingest via the Event Endpoint.
Splunk Indexing with Acknowledgement Using HEC/Event Endpoint:
curl <hostname>:8083/connectors -X POST -H "Content-Type: application/json" -d'{
"name": "splunk-prod-financial",
"config": {
"connector.class": "com.splunk.kafka.connect.SplunkSinkConnector",
"tasks.max": "10",
"topics": "t1,t2,t3,t4,t5,t6,t7,t8,t9,t10",
"splunk.hec.uri":"https://idx1:8089,https://idx2:8089,https://idx3:8089",
"splunk.hec.token": "1B901D2B-576D-40CD-AF1E-98141B499534",
"splunk.hec.ack.enabled" : "true",
"splunk.hec.raw" : "false",
"splunk.hec.json.event.enrichment" : "org=fin,bu=south-east-us",
"splunk.hec.track.data" : "true"
}
}'
So what do these configuration options mean? Here is a quick run through the configurations above. A detailed listing of all parameters that can be used to configure the Splunk Connect for Kafka can be found here.
Congratulations! With a successful deployment in place events should be searchable in Splunk.
We're eager to hear your thoughts on Splunk Connect for Kafka, so please feel free to reach out with any feedback or questions you have. We are actively accepting issues and Pull Requests on GitHub; community contributions are most welcome.
----------------------------------------------------
Thanks!
Don Tregonning

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.