






Digital Resilience Pays Off
How resilient is your organization? Learn how to mature your digital resilience with this free guide.
As an update to .conf’s announcement of our continuous code profiling preview, we’re excited to share that today Splunk APM’s AlwaysOn Profiling is generally available for Java applications, included in APM with no additional cost. Here’s a quick walkthrough of the feature, and how you can get started now.
Code profiling helps application developers and service owners identify service bottlenecks by periodically taking CPU snapshots, or call stacks, from a runtime environment. Information from call stacks provides additional context for slow spans from transaction traces, and helps visualize bottlenecks through flame graphs, to show service performance over time. These benefits speak for themselves, but most other code profiling products incur notable performance overhead, which requires engineers to manually switch them on or off, creating a tradeoff between application performance and available data.
Splunk’s AlwaysOn Profiling provides continuous visibility of code-level performance, linked with unsampled trace data, with minimal overhead. Along with Splunk Synthetic Monitoring, Splunk RUM, Infrastructure Monitoring, Log Observer, and Splunk On-Call, AlwaysOn Profiling gives engineers more context to identify performance issues and troubleshoot faster across production environments.
Splunk APM’s AlwaysOn Profiler is constantly monitoring code performance to give you immediate context of where performance bottlenecks exist. Here are two examples of how AlwaysOn can help identify production issues.
Workflow One: Viewing Common Code in Your Slowest Traces
Engineers troubleshooting production issues often sort through example traces looking for common attributes in their slowest spans. AlwaysOn’s call stacks are linked to trace data, providing context into which code is executed during each trace.
Within APM you can easily view latency within your production environment.
By clicking into any service you’re taken to the service maps, which provide additional context on bottlenecks within that service and its dependencies.
From here, we can explore example traces.
Note: we filtered the “min” by 10,000, or ten seconds, to focus specifically on the slowest traces. We see that requests to /stats/races/fastest repeatedly respond in around 40+ seconds.
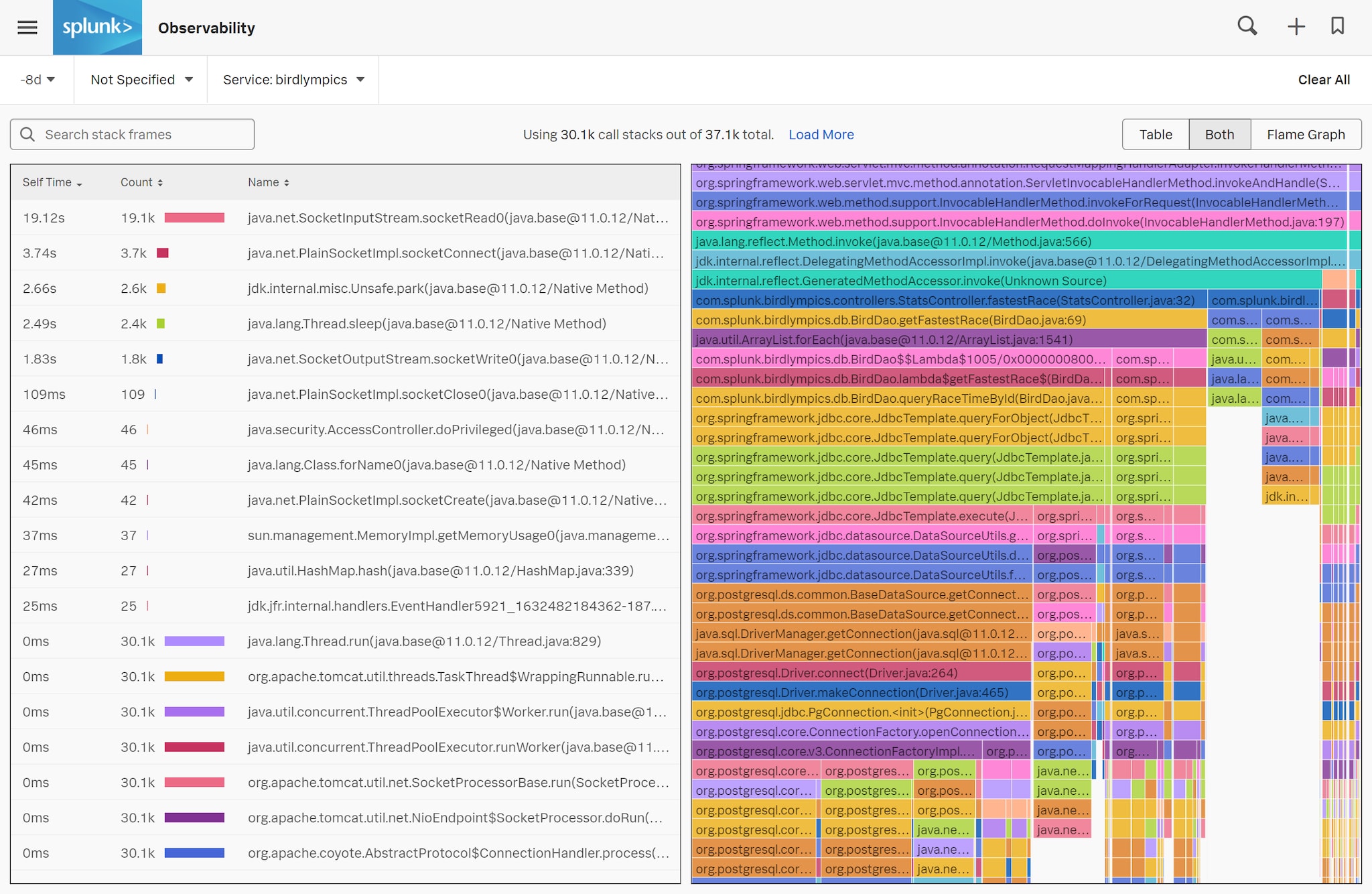
By clicking into one of these long traces, the following screen opens:
We see that while the StatsController.fastestRace operation was being executed, we collected 21 call stacks. As the java agent continuously collects call stacks, the longer the spans, the more call stacks they will have. When I open this span, I see the metadata on the left, and the call stacks that the agent collected on the right. We can use the “Previous” and “Next” buttons to flip through all call stacks:
If you see several consecutive call stacks pointing to the same line of code, it indicates that these lines take a long time to execute, or execute many times in a row. This is often a solid hint at a performance bottleneck.
Workflow Two: Viewing Aggregate Performance of Services Over Time
Before you begin optimizing code, it’s always helpful to understand which part of your source code impacts performance the most. How do you know which part is the biggest bottleneck? This is where aggregation of collected call stacks, in the form of flamegraphs, helps.
When viewing your service map, notice the AlwaysOn Profiling addition on your right side panel, which automatically shows you the top five frames from the call stacks we’ve collected for your selected time range, that already point to bottlenecks in code.
By clicking into the feature, you’re taken to a flame graph, which is a visual aggregation of call stacks collected from the time range you’ve specified. Flame graphs visualize call stacks across a time range - the larger the horizontal bar, the more frequently that line of code is found in the collected call stacks.
Upon viewing the flamegraph, focus on larger top down “pillars”, which indicate lines of code that use the CPU the most. If you want to highlight your own code classes in the flamegraph, use the filter in the top left.
Within each horizontal bar of the flamegraph, there are class names and line numbers for your code. Flame graphs point you to the bottleneck causing the slowness, and the final step in troubleshooting is returning to your source code itself to fix the problem.
Unlike dedicated code profiling solutions, Splunk’s AlwaysOn Profiler links collected call stacks to spans that are being executed at the time of call stack collection. This helps separate data about the background threads from active threads which service incoming requests, greatly reducing the amount of time engineers need to analyze profiling data.
Additionally, with Splunk’s AlwaysOn profiler, all of the data collection is automatic, and low overhead. Instead of having to switch the profiler on during production incidents, users only need to deploy the Splunk-flavored Open Telemetry agent and it begins to continuously collect data in the background.
To enable AlwaysOn Profiling for their Java services, current Splunk APM users need to do the following:
You can find more detailed instructions in our AlwaysOn Profiling documentation.
Not an APM user? Sign up for a trial today.

The world’s leading organizations rely on Splunk, a Cisco company, to continuously strengthen digital resilience with our unified security and observability platform, powered by industry-leading AI.
Our customers trust Splunk’s award-winning security and observability solutions to secure and improve the reliability of their complex digital environments, at any scale.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2025 Splunk LLC All rights reserved.