

Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

 When it comes to patient care, convenience and trust are critical to success. Healthcare startup Galileo prioritizes just that through technology that gives people 24/7 access to medical care and improves the dialogue between patients and their doctors. Galileo ensures uptime, minimizes latency, and reduces errors so patients get the help they need when they need it and can ultimately live better, healthier lives.
When it comes to patient care, convenience and trust are critical to success. Healthcare startup Galileo prioritizes just that through technology that gives people 24/7 access to medical care and improves the dialogue between patients and their doctors. Galileo ensures uptime, minimizes latency, and reduces errors so patients get the help they need when they need it and can ultimately live better, healthier lives.
As a fast-growing agile startup whose architecture relies mostly on serverless resources, Galileo needed an observability solution that could help it maintain uptime and support its increasingly complex observability needs.
I recently had the chance to hop on Zoom with Dave Kerr, a site reliability engineer (SRE) at Galileo, to talk about the innovative ways he and his team leverage Splunk and observability to help Galileo maintain its status as a trusted, affordable, and accessible healthcare app.
Can you tell us more about your role and the team at Galileo?
I work as an SRE on a team that’s tasked with building out and maintaining Galileo’s infrastructure. Since we’re a lean team, we leverage AWS managed services—this means AWS worries about the uptime and security of the underlying infrastructure and we can focus on building business-critical applications and features that allow us to deliver high-quality care to our patients.
We decided to build a largely serverless architecture because we’re a growing company and benefit from only paying for what we use. One of my first tasks when joining was to implement an observability solution, and, given our investments, I knew we needed a solution with great out-of-the-box monitoring for serverless.
Breakdown of Galileo’s Current Environment:
What drew you to Splunk for your observability needs and what products are you using?
We use SignalFx Infrastructure Monitoring and SignalFx Microservices APM for observability. There were two main factors that initially drew us to Splunk for observability. Being a large Lambda shop, SignalFx’s out-of-the-box serverless monitoring capabilities really stood out and allowed us to get up and running quickly. I was also impressed with its advanced alerting capabilities for faster problem resolution.
“The SignalFx team listened to our needs. Even as a small company, Splunk became a trusted partner to us throughout the evaluation process. It’s huge knowing that we can reach out and the Splunk team will be there.”
Breakdown of Galileo’s Observability Solution:
What were the main challenges you experienced prior to Splunk?
Before implementing SignalFx Microservices APM, we had trouble quickly tracking down problems that arose with our Lambda functions. Since Lambda functions are small amounts of code, there end up being many of them. Just last month we had 35 million invocations, which just couldn’t be monitored and alerted on through CloudWatch metrics alone. Additionally, Lambda functions mostly run asynchronously for data work, so errors were not as readily apparent to QA.
We were also struggling to locate when app slowdowns occurred as well as the cause of the performance degradation. Even worse, we only knew when the app was slow because employees were reporting it.
Finally, error debugging was mostly done by searching through logs in Kibana using Elastic stack, but because they’re batch and not streaming, it would take a long time. Moreover, with Lambdas there’s a lot of data that has to be processed, often leading to a large lag time between the occurrence of the error and the identification of the error. Without statistical breakdowns of performance and errors, we had trouble identifying anomalous behavior.
How are you using SignalFx Microservices APM to monitor your stack today including Lambda, Fargate, and other services?
Monitoring Lambda
We now monitor our Lambdas through a combination of Cloudwatch metric ingestion and the SignalFx Microservices APM tracing feature. The open source python client modules made it very easy to add tracing to the Lambda functions, which we leveraged to include the Lambdas in the service map.
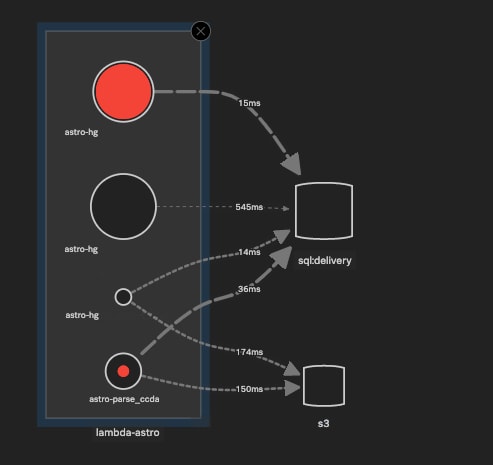 Lambda trace-map displays the different "endpoints" (where in this case endpoint = Lambda function) of the Lambda Application service (lambda-astro), and shows relative error rate, invocation frequency, and latencies for their requests to a sql database and an S3 bucket. Service and database names omitted.
Lambda trace-map displays the different "endpoints" (where in this case endpoint = Lambda function) of the Lambda Application service (lambda-astro), and shows relative error rate, invocation frequency, and latencies for their requests to a sql database and an S3 bucket. Service and database names omitted.
Alerts get sent to a Slack channel when Lambda invocation errors occur, and because of the SignalFx full-fidelity tracing, we don’t miss anomalies—and we get accurate alerts. We route alerts for clinical incidents to VictorOps for our on-call rotation and faster MTTR.
Monitoring Fargate API
We monitor our Fargate API through a combination of Cloudwatch metric ingestion, SignalFx Microservices APM and SignalFx’s out-of-the-box container monitoring. The sidecar agent allowed us to get started right away and was critical for complete visibility since we deploy in Fargate, where there are no container-level Cloudwatch metrics available.
Similarly to what we do with Lambdas, with SignalFx’s analytics-driven alerting features, alerts get sent to a Slack channel when certain thresholds for service endpoint latency and error rate are met. This allows us to quickly identify when and where errors are occurring without getting inundated with alert spam.
“One of the best features of SignalFx is the customizability of alert thresholds based on historical data. We know that we will have accurate alerts, and avoid getting hundreds of unnecessary notifications over the weekends.”
Monitoring “Monolith” + AWS Services + 3rd Party Services
Finally, even though our Flask API would be considered a monolith service, we make heavy use of 3rd party APIs for core features like authentication and payments. Using the built-in plugins for python requests module allowed us to quickly instrument tracing for all requests to external services to track errors and latency.
SignalFx API for Custom Synthetics and Events *Cool Use Case Alert*
For monitoring our web application uptime, we’ve implemented several Lambda functions that measure Google PageSpeed Insights scores and report them to SignalFx. To correlate changes in service behavior and performance with code changes, we’ve hooked up our AWS Codepipeline deployment stages to send requests to SignalFx to create Deployment events with links directly to the commit on GitHub, which is great for post-incident analysis. This insight is critical, since good page performance is essential for optimal customer experience.
 Page load time that displays 4 charts: 1) Lambda@Edge invocations for various Cloudfront features 2) PageSpeed Insights Performance Score for 2) Websites over time 3) PageSpeed Insights Time To Interactive (TTI) for 2 Websites over time 4) PageSpeedInsights Speed Index for 2 Websites over time.
Page load time that displays 4 charts: 1) Lambda@Edge invocations for various Cloudfront features 2) PageSpeed Insights Performance Score for 2) Websites over time 3) PageSpeed Insights Time To Interactive (TTI) for 2 Websites over time 4) PageSpeedInsights Speed Index for 2 Websites over time.
With the insights that we’ve gained from SignalFx, we’ve been able to significantly improve system performance.
“Using the SignalFx Microservices APM tracing feature for the API, we’ve been able to methodically reduce endpoint latencies, with some being reduced by as much as 95%”
 Latency reduction that displays median latency reduction from 2500ms to 100ms.
Latency reduction that displays median latency reduction from 2500ms to 100ms.
Adding tracing to Lambdas highlighted to developers which databases are shared by Lambda data pipelines and the API, leading to a plan to leverage the new AWS RDS Proxy once it emerges from preview. It also uncovered opportunities to move parameters store fetching and DB connection creation to outside of the Lambda handler, in order to share across invocations and avoid hitting SSM rate limits.
For both the Lambda functions and the Flask API, adding tracing allowed us to more easily track the latency and error rate of all our connectivity to 3rd party services. For example, recently the authentication platform we utilize had an incident which caused many of our API endpoints to cease functioning. Through our alerts, we identified the source of the problem and started working on a resolution before the incident was officially communicated by the vendor, which helped us to more quickly communicate this message internally and minimize customer impact. In addition, during the postmortem of this incident we utilized the traces from the incident period to identify improvements to our architecture to further reduce the impact footprint of potential outages in the future.
“Thanks to SignalFx Microservices APM, within seconds, we were able to start taking a look and comb through alerts and feature flagging to remediate the issue before our stakeholders were affected.”
As you can see, our investments in observability have not only allowed us to improve our architecture, but have had a tangible impact on how our customers use and trust us when they turn to Galileo as their go-to healthcare partner
“ Since we are in healthcare, we are also trying to facilitate live interactions between patients and doctors who are providing care—uptime, minimizing latency, and reduction of errors are all critical in keeping the trust of patients. If they are using a buggy or a slow system it’s going to appear that we are not trustworthy. The reliability of the system is of utmost importance, because people can’t afford to have a bad experience when it comes to their health.”
Follow: @galileohealth on Twitter!

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
