Splunking web-pages
Tips & Tricks SplunkHave you ever had a situation where you found information on a webpage that you wanted to get into Splunk? I recently did and I wrote a free Splunk app called Website Input that makes it easy for everyone to extract information from web-pages and get it into a Splunk instance.
The Problem
There are many cases where web-pages include data that would be useful in Splunk but there is no API to get it. In my case, I needed to diagnose some networking problems that I suspected was related to my DSL connection. My modem has lots of details about the state of the connection but only within the web interface. It supports a syslog feed but it doesn’t include most of these syslog messages. Thus, to get this information, I need to get it directly from the web interface.
Some other use cases might be:
- Integrity analysis of a website (so that you could alert if something goes wrong or if the site is defaced)
- Identify errors on pages (like PHP warnings)
- Retrieve contextual information that would help you understand the relevance of events in Splunk (like correlating failures with weather conditions)
The Solution
I wrote an app that includes a modular input for getting data from web-pages. Basically, you tell the app what page you want to monitor and what data to get out of the page. It will retrieve the requested data so that it can be searched and reported in Splunk. You identify the data you want to obtain using a CSS selector. The app will then get all of the text from under the nodes matching the selector.
Getting the Data into Splunk
Getting the web-page data into Splunk is fairly easy once you know the URL and the CSS selector that you want to use. You can get the data into Splunk in four steps.
Step 1: identify the URL
You’ll need to identify the URL of the page containing the data. In my case, I wanted to get data from my DSL modem and the URL containing the data was at http://192.168.1.1/statsadsl.html:
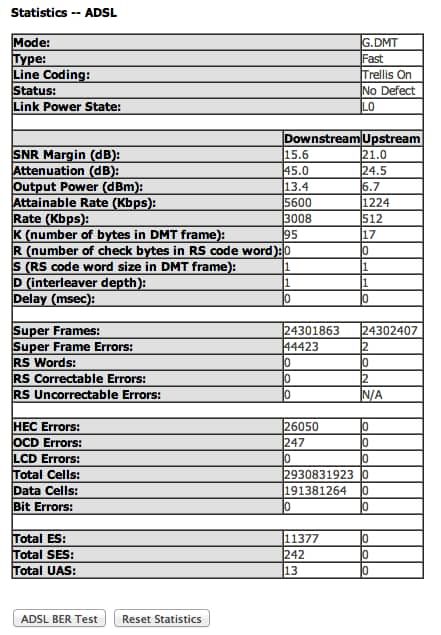
Step 2: identify the data
After identifying the URL, you’ll next need to make a selector that matches the data you want to obtain. If you don’t know how to use CSS selectors, Google “jQuery selector” or “CSS selector”. Here are a couple of good places to start:
The selector indicates what parts of the page the app should import into Splunk. For each element the selector matches, the app will get the text from the matching node and the child-nodes. Consider the following example. Assume we are attempting to get information from a page containing the following HTML table:
<table>
<tr>
<td></td>
<td>Downstream</td>
<td>Upstream</td>
</tr>
<tr>
<td>Rate:</td>
<td>3008</td>
<td>512</td>
</tr>
<tr>
<td>Attainable Rate:</td>
<td>5600</td>
<td>1224</td>
</tr>
</table>
The table would look something like this:
If I enter a selector of “table”, then the app will match once on the entire table and produce a single value for the match field like this:
This could easily by parsed in Splunk but it would be easier to parse if the results were broken up a bit more. You can do this by changing the selector to make multiple matches. If I use a selector of “td”, then I will get one value per td node (per each cell):
Note that the app will make a single field (called “match”) with values for each match. Empty strings will be ignored.
Matching “td” works ok, but I think I would like the field values near the description. Thus, I would prefer to use a “tr” selector which will make a value for each row. That would yield:
This will be very easy to parse in Splunk. Once you get the selector and URL, you will be ready to make the input.
Step 3: make the input
Make sure you have the Website Input app installed. Once you do, you can make a new input by going in the Splunk manager page for Data Inputs and selecting “Web-pages”:

Click “Add new” to make a new instance:

The configuration is straightforward once you know what page you are looking and what selector you want to use. In my case, I needed to authenticate to my DSL modem so I needed to provide credentials as well. Also, you will likely want to set the sourcetype manually, especially if you want to apply props and transforms to the data. Otherwise, the data will default to the sourcetype “web_input”. Below is my completed input which grabs the data every minute and assigns it the sourcetype of adsl_modem:

Once the input is made, you should see the data in Splunk by running a search. In my case, I searched for “sourcetype=adsl_modem”:

The data is present in Splunk and is searchable, but it isn’t parsed. That leads to the last step.
Step 4: parsing
Finally, you will likely want to create props and transforms to extract the relevant data into fields that you could include on dashboards. I want to get the value for “Super frame errors” since I have determined it indicates when my DSL connection is having problems.
I can use rex in a search to parse out the information. The following extracts the fields “super_frame_errors_downstream” and “super_frame_errors_upstream”:
sourcetype=adsl_modem | head 5| rex field=_raw "Super Frame Errors: (?<super_frame_errors_downstream>\d*) (?<super_frame_errors_upstream>\d*)"
This gets me the information that I wanted in the appropriate fields:

You may want to have the extractions done in props/transforms so that you don’t have to add rex to every search that needs the data parsed. In my case, I did this by adding the following to props.conf:
[adsl_modem]
EXTRACT-super-frame-errors = "Super Frame Errors: (?<super_frame_errors_downstream>\d*) (?<super_frame_errors_upstream>\d*)"
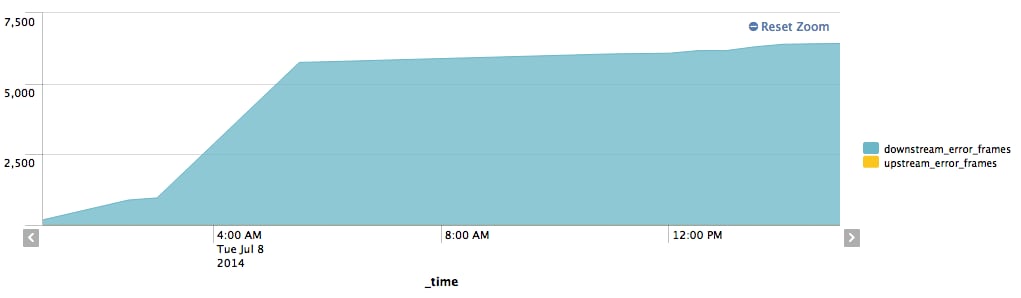
With the data extracted, I could make a chart to illustrate the errors over time:
Getting the app
If you want to use the app, go the apps.Splunk.com and download it (its free). If you need help, ask a questions on Answers.splunk.com.
Limitations
The app currently only supports HTTP authentication which means you cannot use it to capture data from web-pages that require you to authenticate via a web-form (might be supported in a later version). Also, you need to be careful pulling data from others’ websites without approval. Some websites have terms of use that disallow web-scraping.
----------------------------------------------------
Thanks!
Luke Murphey