
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

This blog post is part seventeen of the "Hunting with Splunk: The Basics" series. When I joined Splunk, I was given the moniker of "Minister of OODALoopers" because of how much I believe the feedback loop is important to network defense. Mr. John Stoner gives a succinct write-up of the value of the "feedback loop" and why organizations shouldn't leave value on the table from their IR. – Ryan Kovar
 |
No, this blog isn’t about Christopher Walken and one of his many fine Saturday Night Live sketches. In fact, I’ll start by saying that compared to the other blogs in this series, this one will be a bit lighter on thetechnical nuts and bolts of threat hunting than the others. What it will cover—as you may have guessed from the title—is something as important as the technical bits, which is the need for applying process to your hunt and to how your hunting findings are operationalized.
Just so everyone knows where I'm coming from, I'll admit that I like process. I use checklists all the time, and I was very excited when Next Steps was added to Splunk Enterprise Security...but I digress.
We can hunt all day long and find all sorts of artifacts and indicators, but if we don’t do anything with what we find, how is our hunt improving our organization’s security posture and assisting our analysts and incident responders?
The goal of threat hunting isn't to perform the same hunt over and over again. We want to learn from every hunt, and if a hunt's successful, we must operationalize it. But what does that mean? We need to provide feedback to those who can benefit from what we learned; feedback can take many different forms, but to be effective, scalable and repeatable, it should have a process associated with it. Several constituents can benefit, but for now, we'll focus on the analysts and incident responders that are part of the security operations team.
Analysts and incident responders themselves should be following incident handling processes that have been defined and refined based on their experiences. For this blog post, we'll reference the incident response lifecycle that NIST published as part of their Computer Security Incident Handling Guide so that we're using a consistent—and hopefully familiar—terminology.
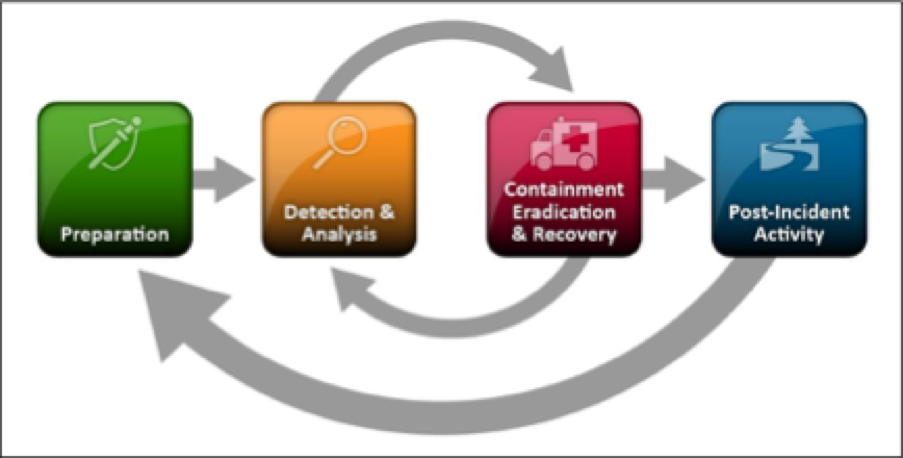
Source: NIST SP800-61r2
From an incident handling perspective, analysts focus their time and attention on the Detection & Analysis phase. A process should exist to take artifacts and indicators that are identified during our hunt, and inject them into the tools that analysts use for monitoring. If our organization leverages a methodology to assess intrusions—like the Lockheed Martin Cyber Kill Chain—detection of the intrusion in different phases of the kill chain will determine how analysts can use these indicators to monitor for additional or future intrusions, as well as assisting incident responders in the proper course of action to take.
While threat hunting can take place across all phases of the kill chain—allowing us to be proactive in our hunting—we still need to have a process to provide feedback of our findings to multiple teams so they can act. To help flesh this out further, let’s take an example when something happens during the Command and Control (C2) phase of the Kill Chain.
During a hunt, if we identify C2 traffic is exiting our network to a specific callback domain or IP address, that information is incredibly valuable to our analysts. This information has direct applicability to a current incident that may be created because of that indicator, or it may provide additional context to another incident that is currently being investigated. Additionally, that information could be ingested into our monitoring and detection systems so that the next time this indicator is seen, it can be more easily recognized and time to detection can be decreased.
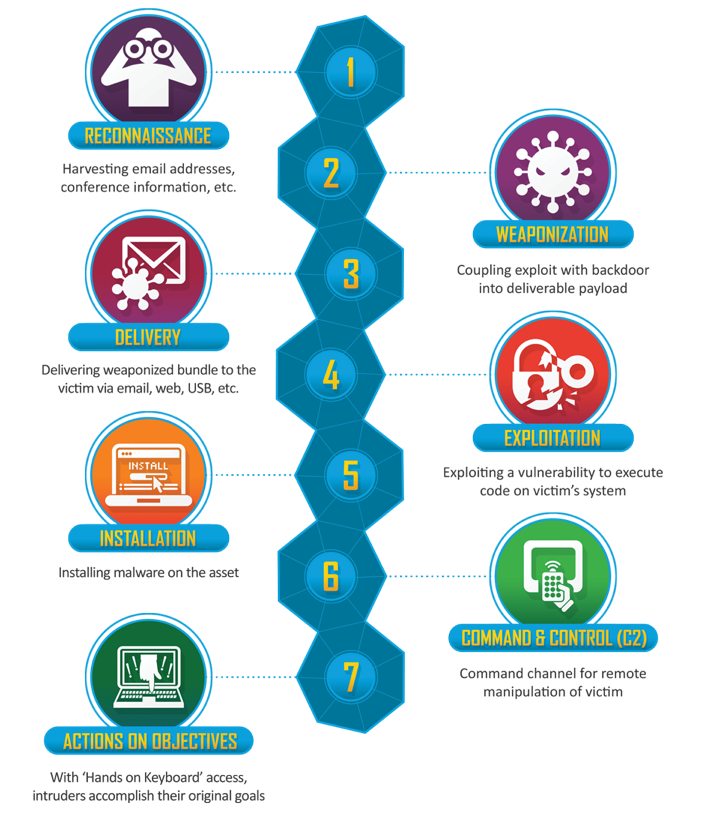
Source: Lockheed Martin
Incident responders are often tasked with containment, eradication, and recovery. They may find artifacts from that same hunt in the C2 phase extremely useful for tracking down the offending systems internally. With the information gathered in this particular hunt, informed decisions can be made around immediate eradication versus containment. By containing the threat, incident responders can then monitor and potentially prevent certain information from leaving but still collect intelligence on the adversary and so forth.
Since an incident can cycle back and forth between Detection & Analysis to Containment, Eradication & Recovery multiple times, it's essential that both groups (analysts and incident responders) have access to have these indicators and artifacts of the associated events promptly. For example, if we only establish a process to provide indicators to the analysts, we'll enable them to see egress traffic to the C2, but that doesn’t get our organization any closer to containing and eradicating the threat. If the incident responders are given the results of the investigation, they'll eradicate the threat, but that doesn't allow for analysts to loop the results back into defenses and detect the threat again in the future if the adversary uses the same tactics, techniques and procedures (TTPs) as the previous attack. In the case of advanced threats, that IP or domain might not be the only egress point, so orchestration between hunters, analysts and incident responders is key to responding.
Hunters need to work with the analysis and incident response teams to ensure that their knowledge is infused into the entire incident-handling process. The challenge is that when things go sideways, the process often gets thrown out the window.
I mentioned I make lists, but when I'm pressed for time, building and operating off the checklist often gets set aside, and I take actions based on what is top of mind or inbox. If we do that in security operations, we risk missing key steps, especially if there are different processes for different incidents. Applying automation and orchestration to security operations can mitigate this with tools like Splunk Phantom.
If we ignore processes when hunting, perhaps we find our prey, but that alone doesn’t make our organization’s security posture better. If we don’t get the information to the teams or systems where it can be used most effectively, we've failed. Hunting—just like incident handling—needs to have processes and they must be tested. We can introduce playbooks that assist in the automation of our hunting and then generate workflow directly to the incident responders and analysts with our findings; that way, when it hits the fan, the team has confidence that the processes work and can be acted against, not developed on the fly.
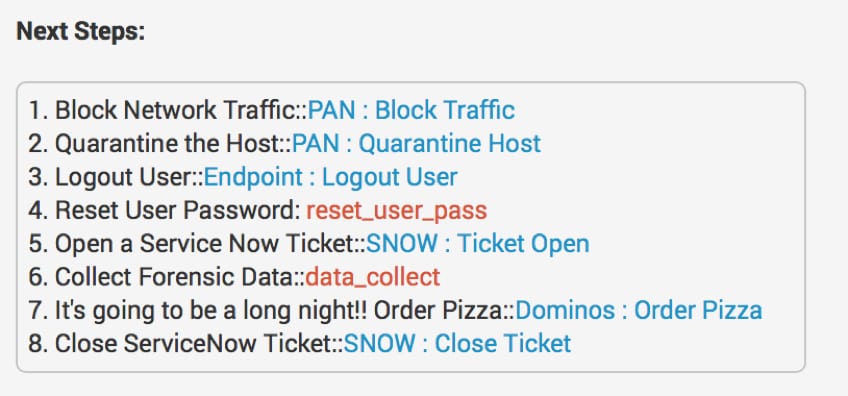
So, how does all of this apply to Splunk? If we're hunting with Splunk, we can use workflow actions to take indicators and events and pass them back to the analysts and incident responders. For a review of how workflow actions are set up, please check out Ryan’s earlier post in our series, "Work(flow)ing Your OSINT." This could be via a lookup table that can then be used for watchlists to correlate with new data; we could use an adaptive response action to send findings to a third-party tool to take action; or we could create an investigation or notable event in Splunk Enterprise Security to aggregate and track information for closure.
When we consider the capabilities that Splunk Phantom provides, we can also create an end-to-end playbook that automate and orchestrate aspects of our hunt and gathering of threat intelligence as well as decision making to hand off information to other teams. Additionally, we also add the ability to create cases and apply frameworks like NIST SP800-61 to the entire incident.
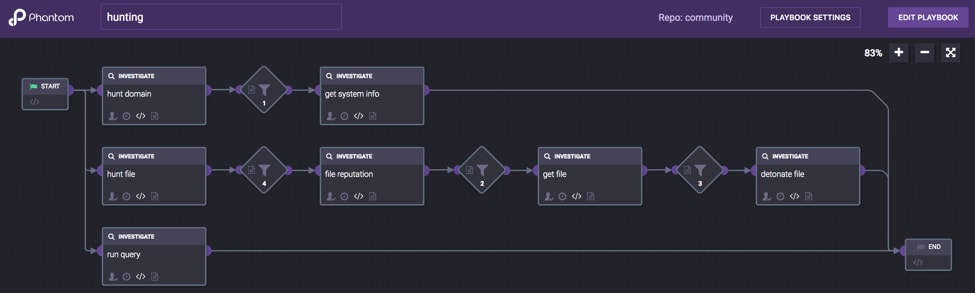
I hope this provides ideas on how to provide feedback from hunting into security operations. Hunting is a critical capability but being able to integrate and provide feedback to analysts and incident responders seamlessly is crucial.
Happy hunting!
----------------------------------------------------
Thanks!
John Stoner

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
