
Splunk ITSI for AIOps
Discover our industry-leading approach to AIOps & monitoring.

From "A Blueprint for Splunk ITSI Alerting - Step 1" in this blog series, we’re now producing notable events for degraded services, but we’ve also introduced a bit of an issue.
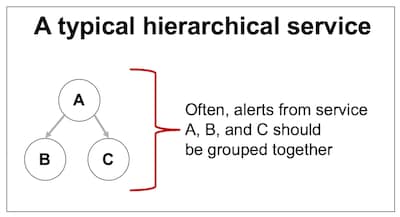 It’s highly likely that many of your Splunk IT Service Intelligence (ITSI) services are designed hierarchically with one or more sub-services. Regardless of which service or sub-service is degraded, we typically want to group notables from related services together so that we can reduce the overall alert volume and page out the right team exactly once. To solve this problem, we’ll create a new field for every notable called alert_group which we can use to group related notable events together.
It’s highly likely that many of your Splunk IT Service Intelligence (ITSI) services are designed hierarchically with one or more sub-services. Regardless of which service or sub-service is degraded, we typically want to group notables from related services together so that we can reduce the overall alert volume and page out the right team exactly once. To solve this problem, we’ll create a new field for every notable called alert_group which we can use to group related notable events together.
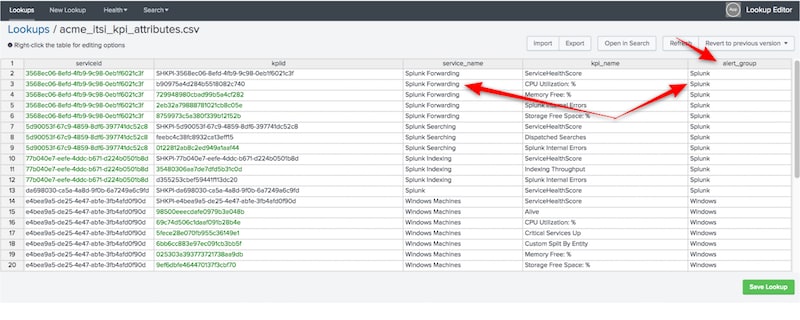
In my opinion, a lookup is the most effective way to create and maintain this alert_group attribute. We’ll create a new lookup for every service and KPI, assign appropriate alert_group values, and configure the lookup to run automatically. Also, if you haven’t seen or used the Lookup File Editor app yet to help you maintain lookups, it’s high time you check it out.
Here is some SPL to help you build your lookup initially. It uses a macro (be sure to run in the Splunk ITSI app) to list all the services and KPIs configured in Splunk ITSI and outputs them as a new lookup:
| `service_kpi_list` | eval alert_group=service_name | table serviceid kpiid service_name kpi_name alert_group | outputlookup acme_itsi_kpi_attributes.csv
The above SPL will, by default, assign the service_name to the alert_group field, but this is just to get you started. You’ll want to update the alert_group field to create appropriate groups for related services.
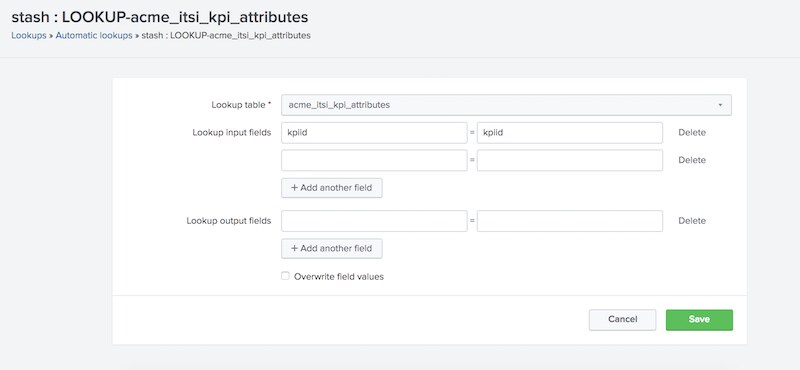
Finish off the lookup by updating the permissions to app or global, and configure the lookup to run automatically against the stash sourcetype. This ensures that every notable event created by our correlation searches going forward will always have the alert_group field applied as well.
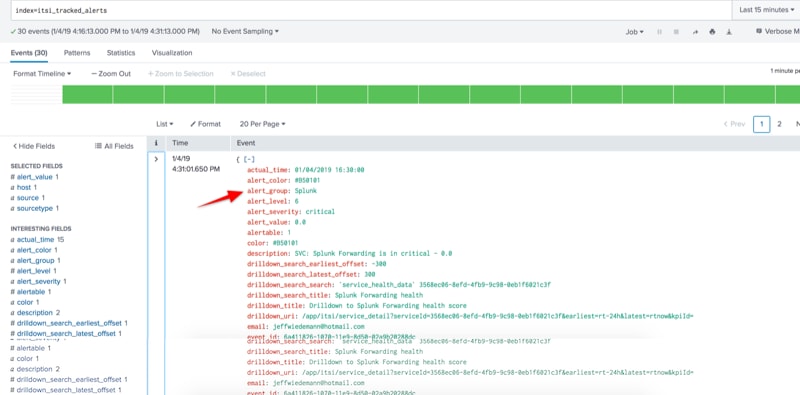
Validate that your alert_group field is now populating as expected in the itsi_tracked_alerts index for new notable events.
To take advantage of this design, we need to create a Notable Event Aggregation Policy (or NEAP as we call them). NEAPs are very powerful rules designed to group related notable events and take action. For some of you, this may be your first exposure to using NEAPs beyond the default policy. If so, take a moment to check out the Notable Event Aggregtion Policy documentation in Splunk Docs to learn more.
In our policy, we’ll focus initially on the following configurations:
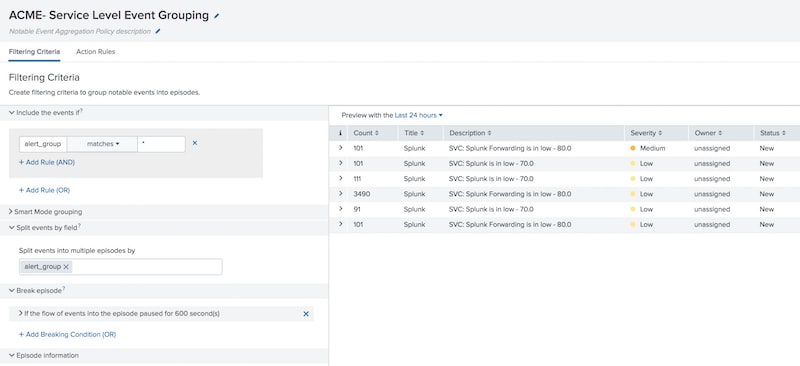
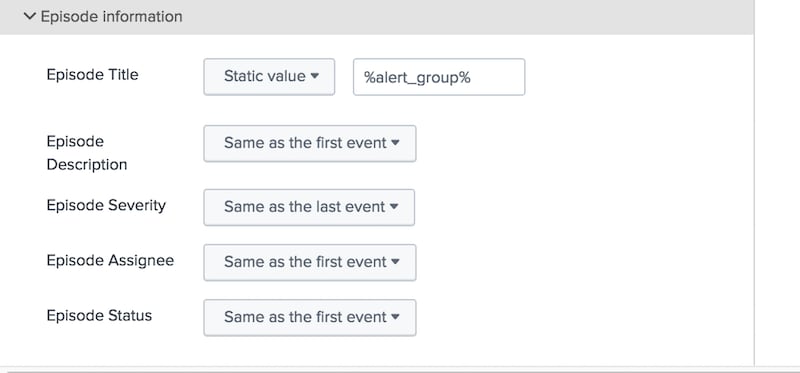
To sum up the policy behavior in plain old English: Any notable event that has an alert_group field will qualify for this policy (with the automatic lookup, every notable should have one). We’ll split and group notables that share the same alert_group field; this groups together all notables sharing the same alert_group field regardless of the originating service. We’ll end the episode if we don’t get any new notable events flowing in for at least 10 minutes. New notables would then create a new episode to be reviewed. And lastly, we’ll use the power of tokenization to give the episode title the same name as our alert group name.
Obviously all of these configurations are yours to alter as you see fit, but this should be a reasonably good starting point from which to alter and augment.
Save your NEAP and give it a meaningful name.
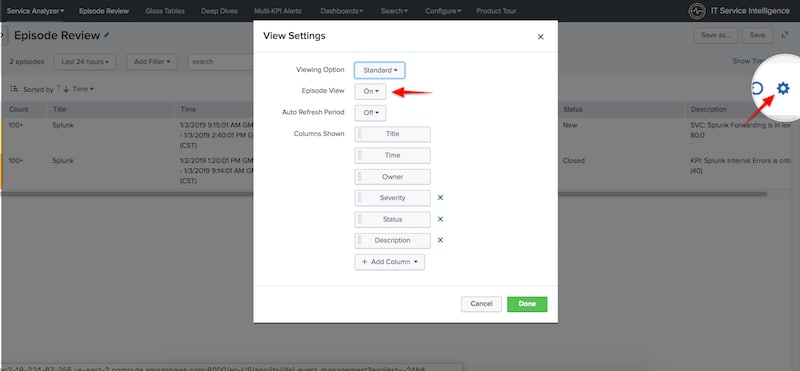
Once you save your NEAP, head over to the episode review screen. From the view setting gear icon, ensure you turn on episode view—this tells Splunk ITSI to render the notables grouped according to your aggregation policy rules as opposed to one line per notable event.
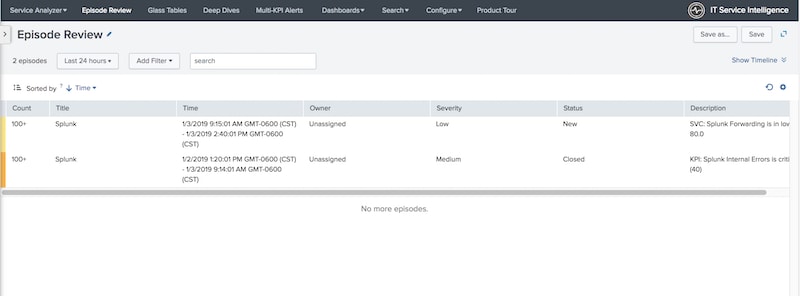
New notable events created after you’ve saved your policy should start being grouped together. To really test your NEAP, you should have multiple notable events from different services being grouped together based on sharing the same alert_group value.
Cool, right? Move on to Step 3...

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
