
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

Continuing on from "A Blueprint for Splunk ITSI Alerting – Step 2," in this third step, we’ll focus on several more correlation rules you may want to consider implementing to identify noteworthy issues in your environment. Again, not to sound like a broken record, but we’re not yet producing alerts based on these correlation rules; we’re simply providing ourselves additional health-related context—in the form of notable events—to use later in producing meaningful alerts.
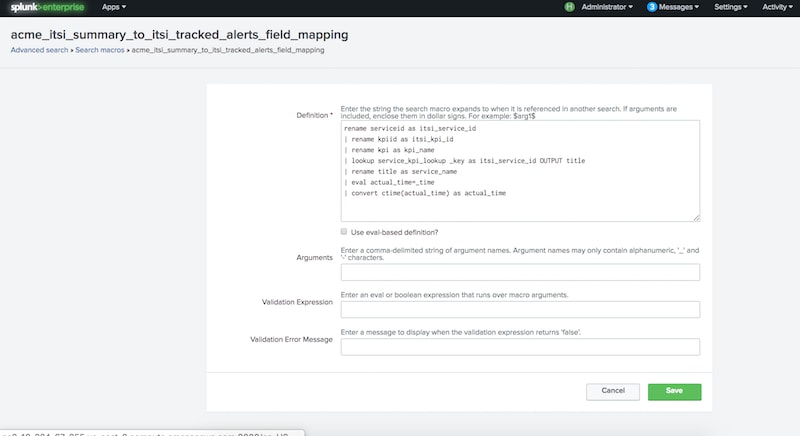
You may have noticed from the correlation rule in "A Blueprint for Splunk ITSI Alerting - Step 1" that we’ve injected some field mapping logic in the form of rename, lookup, and eval commands. Unfortunately, common fields like kpiid are stored differently on the itsi_summary vs itsi_tracked_alerts index, so a mapping is required to ensure ITSI has the right field values in the result to store on the itsi_tracked_alerts index.
We can add the mappings inline in our correlation searches, like we did in the "Step 1" blog. Alternatively, we can define a new macro which contains the mapping SPL and append the macro to all of our new correlation searches. Either way is fine, but I’ll go the macro route in this blog.
Most of the searches below are designed to look back at the recent results written to the itsi_summary index, however selecting the appropriate timerange isn't entirely obvious. The _time field on the itsi_summary index is (intentionally) lagged back in time based on the KPI frequency and monitoring lag. So, should you set a timeframe of 1m, 5m, 15m, 30m, or more? The short answer is that you should probably look back about 16 minutes and dedup results in your search by kpiid. Looking back 16 minutes ensures that the correlation search picks up KPIs scheduled to run only every 15 minutes. The additional 1 minute accounts for the default 30 second monitoring lag. Deduping by kpiid ensures that the most recent itsi_summary result for that KPI is looked at in the event that multiple are returned.
I encourage you to play around a little in the search screen to understand this, because setting too short of a lookback window will cause you to miss some results written to the itsi_summary index leading to missed notables. Failing to dedup will cause you to look at the same results too often, leading to duplicated notables.
Similar to creating notable events for degraded service health scores, we may want to create notable events when KPIs degrade. This correlation search will look across all KPIs and create a notable event for any KPI which is in a high or critical status.
index=itsi_summary is_service_aggregate=1 is_service_max_severity_event=0
| dedup serviceid, kpiid
| search alert_level > 4 | ` acme_itsi_summary_to_itsi_tracked_alerts_field_mapping`
Presuming you are using per-entity thresholds for some of your KPIs, you might want to create notable events if an entity within a KPI has begun to degrade. This correlation search will look across all per-entity KPI values and create a notable event for any entity in a high or critical status.
index=itsi_summary is_service_aggregate=0 is_service_max_severity_event=0
| dedup serviceid, kpiid, entity_key
| search alert_level > 4
| ` acme_itsi_summary_to_itsi_tracked_alerts_field_mapping`
From time to time, services may flap between healthy and unhealthy states. Maybe that flapping isn’t of sufficient importance to alert, but services experiencing long periods of unhealthy statuses should be alerted on. This correlation search will look across all services and create a notable event for any service which has 80% or more of its most recent results in an unhealthy status. Note that this correlation search can be configured to scan the last 5 minutes, the last 15 minutes, the last 60 minutes or any other range you desire. If uncertain, I’d recommend running over the last 15 minutes to start.
index=itsi_summary kpiid="SHKPI-*"
| eventstats count(eval(alert_level>2)) as unhealthy_count count as total_count by serviceid
| eval perc_unhealthy = unhealthy_count / total_count
| dedup serviceid
| search perc_unhealthy > 0.8
| ` acme_itsi_summary_to_itsi_tracked_alerts_field_mapping`
Similar to multi-KPI alerts, determining if a service has not just one, but several degraded KPIs is noteworthy. This correlation search will look across all KPIs and create a notable event for any service where three or more KPIs are reporting unhealthy statuses.
index=itsi_summary kpiid!="SHKPI-*" alert_level>2
| dedup serviceid, kpiid
| eventstats dc(kpiid) as num_degraded_kpis by serviceid
| dedup serviceid
| search num_degraded_kpis > 2
| ` acme_itsi_summary_to_itsi_tracked_alerts_field_mapping`
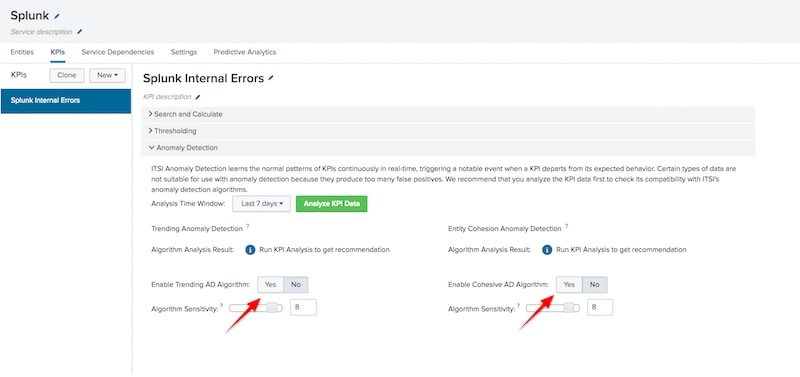
Well, this one is a bit of a layup because it’s existing functionality! If you have decided to use anomaly detection algorithms to help determine misbehaving KPIs, Splunk IT Service Intelligence will automatically create a notable event per detected anomaly for each KPI. Simply enable the anomaly detection algorithm you wish to use.
Hopefully, with the specific examples above, you get the idea of what types of detections are possible and what the correlation searches look like. And hopefully, you see that many more are possible as well.
But there are several things to keep in mind as you consider other possible searches. First, you’re not limited to looking only at the most recent results from itsi_summary; you may find value in evaluating historical results as well. The sustained service degradation search does exactly this. Second, you don’t need to look only at the itsi_summary index, perhaps you will find value in looking at unusual notable event activity from the itsi_tracked_alerts index. Below are a handful of other possible detections you might want to consider.
It quickly becomes obvious that the possibilities are vast and the power to detect sophisticated forms of service degradations exists. The goal isn’t to create an over-abundance of correlation rules and notable events, but rather consider how creating specific types of notable events can facilitate accurate and advanced detection of issues. We’re nearing the point where we turn all of these notable events into actionable alerts, and our next blog post will pick up there.
This is getting crazy! Let's go to Step 4...

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
