
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

Note: This blog is a recap of a presentation Arijit delivered at DockerCon 2019. If you prefer watching to reading, you can find the recording here.
It’s clear now that we’re in the age of microservices, with Docker and Kubernetes as the standard platforms for deploying them. Breaking down applications into a smaller collection of individual components increases complexity, and these complex systems require more sophisticated tools to operate.
Thankfully, Docker and Kubernetes exposes monitoring and observability data in standardized ways, and the ecosystem of open-source monitoring tools we have today is thriving as a result. But what’s not covered in the documentation? Let’s explore some of the challenges with scale, churn, and correlation that arise when running applications on Docker and Kubernetes, and strategies for overcoming them.
We have to deal with much greater scale in Kubernetes-based environments for a number of reasons:
A common approach to scaling up your monitoring system is to divide and conquer. For example, if you had multiple Kubernetes clusters, you could run a Prometheus server for every Kubernetes cluster in your environment.

However, this approach fragments your data collection – it’s not easy to look across different Prometheus servers when you need data from different places. Additionally, because data volume tends to vary across parts of our environment, each of those Prometheus servers might experience different degrees of load, which causes hotspots – the result is uneven performance and potentially wasted compute resources.

You could – if you can afford to do so – simply overprovision capacity or pay for the ability to keep recent data in memory. But while spending more on infrastructure might solve for hotspots in your monitoring system, it still doesn’t address fragmentation issues.
One solution is to use an aggregator of aggregators like Thanos, which aims to provide a global query view of existing Prometheus deployments in your environment. At Splunk, we use a single load-balanced scalable store to avoid the problem of fragmentation and hotspots entirely. Keeping monitoring data in a single place makes it easy to search for the right metric, while also ensuring more consistent performance and resource utilization.
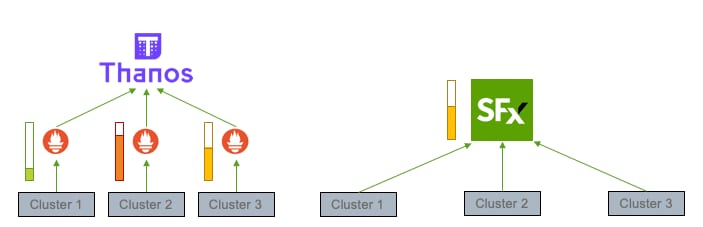
As your environment grows, so do your queries – long or broad queries (looking far back in time, or across a large group of components) will inevitably become slower, and in some cases fail.
For instance, 1 year of data across 1000 containers at 1-second resolution works out to roughly 31 billion datapoints. Basic computer science dictates that transferring and processing 31 billion datapoints doesn’t happen instantly, and for many enterprises and services, 1000 containers is no longer considered a large number. Slower query performance prevents you from easily seeing historical trends and alerting on regular patterns, or using long-term data for capacity planning. Even worse, problem detection and root-cause analysis during outages takes longer because ad-hoc queries may not run fast, prolonging incidents.
Again, it’s possible to address this by spending more money, and store your recent data and queries in memory (caching a week’s worth of the most recent data in Memcached will make the vast majority of queries run faster). A better way to make queries efficient is through pre-aggregation. You could aggregate data (computing things like the sum, average, minimum, maximum of a given metric) across a particular grouping, like application, cluster, or another hierarchy of your choosing – an example might be computing the average of a certain metric across 1000 containers and storing that as a time series for more efficient querying.
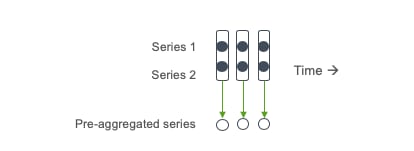
The Splunk approach is to pre-aggregate across time rather than across services, meaning that for every data stream, we compute mathematical rollups that summarize data across predetermined time windows (i.e. calculating the average CPU utilization of a host over 1-second, 1-minute, 5-minute, and 1-hour intervals).

Churn is probably the hardest and most underestimated problem with container monitoring, and occurs when a source of data (i.e. a metric time series) is replaced by a different, but equivalent one. For example, if you replace an AWS instance or restart a Docker container, you’ve created a new "instance_id" or "container_id" reporting metrics to your monitoring system. Lots of common operational tasks and features of today’s environments cause churn, including:
We use metadata in monitoring to make data easier to group, filter, and interpret (associating containers with a particular service, filtering hosts by cloud provider, tracking request latency per customer), but component churn also expands the volume of metadata our monitoring systems must handle.
Metadata can suddenly increase as a result of churn, and is challenging to process quickly. How do you efficiently process a system-wide change, such as during blue-green deployments where you stand up a replica of your entire production environment to receive traffic?
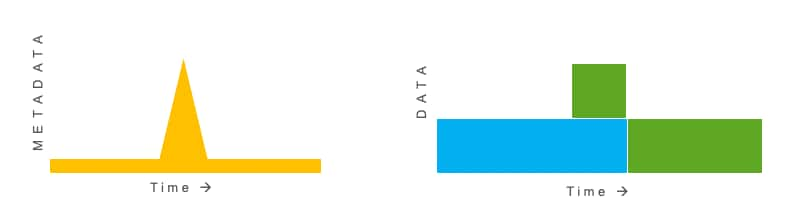
What about large-scale metadata tagging? Say for example you wanted to calculate the hourly cost of running your microservice on AWS EC2 instances. To properly work out the cost of each instance, you need to know the AWS instance type associated with each host, so you add an "instance_type" property to all of the hosts in your environment. The number of datapoints or events that your monitoring system is processing remains the same, but the amount of metadata has increased.
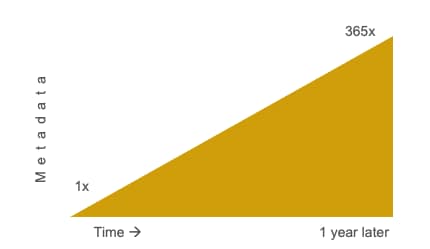
Churn also leads to metadata accumulation—you have 365 times more metadata per year if you push changes to your entire system daily—and is especially painful with containers. A 1-year chart has to stitch together 365 different segments together, severely limiting the usability of your system, and can slowly kill your metrics storage backend.
Pre-aggregation (e.g. by using recording rules in Prometheus) can help somewhat, but there is a tradeoff between latency and accuracy, and this is often expensive to do at scale. At Splunk, our approach is to put the metadata into its own independently scaled storage backend, which we refer to as the Metastore. Since the metastore only has to scale with metadata churn (when you push a new version of a service) and not with the volume of datapoints being received (the steady state when a microservice is running), it has a simpler problem to deal with, and this enables Splunk to support high-churn environments extremely well.
We’ve also built awareness of timing into our metrics pipeline that dynamically addresses the tradeoff between latency and accuracy when it comes to pre-aggregating data. Splunk Infrastructure Monitoring produces timely yet accurate results by individually analyzing and modeling the delay behavior and timing of each data stream. Based on this model, when an aggregation needs to be performed across a set of time series, Splunk Infrastructure Monitoring calculates the minimum amount of time to wait before computing an accurate aggregate value. This is a key component of our solution’s streaming analytics engine, and reduces alert noise generated by false alarms.
When you think about the monitoring and observability tools that people use today, we’re gathering and acting on data emitted by many different layers of the stack. It’s challenging to make sense of this data, correlating behavior across data sources, and keeping all of this actionable (for humans).
Observability data encompasses many different components and types, and distilling them into KPIs (alternatively, SLOs and SLIs) requires us to look across all of these different data sets:
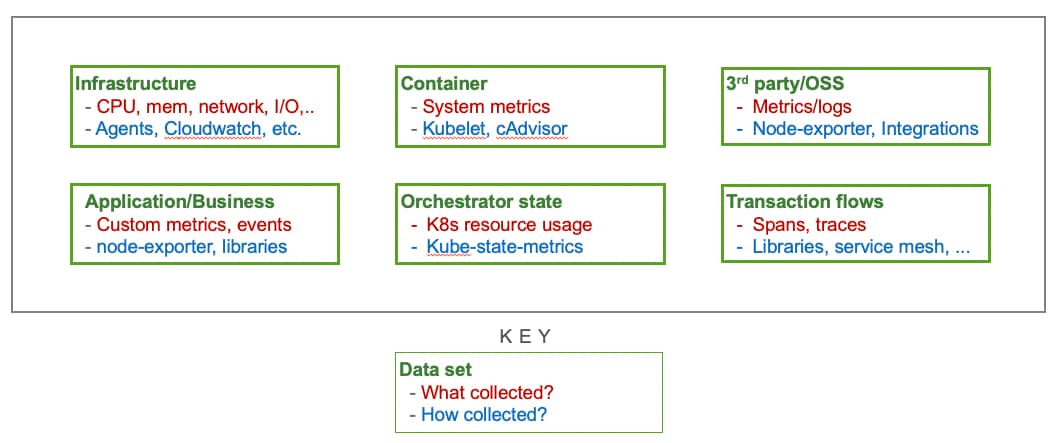
Being unable to do this handicaps your monitoring – an application might be affected by the container it runs in, or the host that container is running on – and being forced to look at each of these signals in isolation results in alert noise and fatigue.

Careful data modeling (for example, using tags and dimensions to group and filter metrics) can make correlation easier. Adopting schemas with ‘join’ dimensions ("instance_id", "container_id", and "app_id" on metrics) and importing additional metadata (such as from the underlying cloud provider) also helps.

At Splunk we do both, and use a multi-dimensional data model that makes it possible for users to filter through metrics on any combination of metadata tags and dimensions.
Monitoring data also comes in several formats. Typically metrics tell us whether we have a problem, traces help us figure out where that problem is occurring, and logs can provide additional context for understanding exactly what the problem is. The ability to correlate across these different tools during an incident is critical – imagine being forced to manually copy context from your metrics solution to search through your logs. This is even worse when naming conventions differ across each of these data types (e.g. using ‘host’ in your metrics system, ‘node’ in logs, and ‘instance’ in traces).

Standardizing schemas across types of telemetry data makes correlation easier. Ideally, you’ll also want to construct point-and-click integrations between tools (or look to solutions that have them) to enable preservation of context, because being able to do things like go from an alert to the corresponding time slice in your logging solution is incredibly powerful.
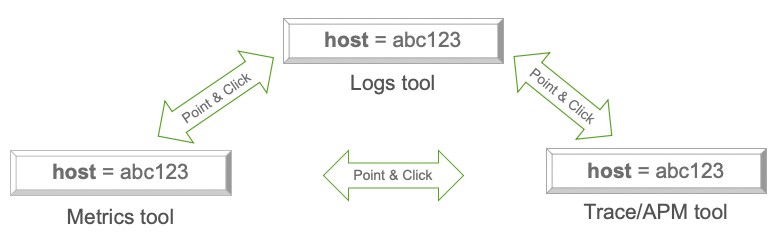
At Splunk we do both – our Splunk Application Performance Monitoring (APM) and Spunk Infrastructure Monitoring products share metadata and schema. This is because as our APM solution observes transactions and spans, it generates a set of metrics that share the same dimensions/metadata that would be applied to infrastructure or application metrics. These generated metrics are stored and viewable in the infrastructure monitoring product, meaning that users can shift from viewing metrics to traces seamlessly using shared metadata.
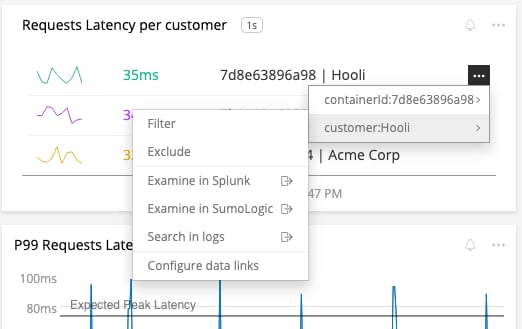
Splunk also provides options for users to link from Splunk to their logging solution or other external destinations without losing crucial context. For example, you can associate URLs with any value of a metric, or specific key-value pairs – allowing you to navigate through other parts of your workflow directly from a chart.
Monitoring is more critical than ever, and even though monitoring data is fairly standardized, you’re still going to face problems that require more effort than simply putting a new set of solutions into place. Smart tool selection, capacity planning, integrations, and engineering optimizations can all help overcome the challenges of scale, churn, and correlation, and let you run applications on Docker and Kubernetes with confidence.
Get visibility into your entire stack today with our free 14-day trial of Splunk Infrastructure Monitoring.

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
