
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.

We are excited to partner with AWS in launching Amazon EKS Distro (EKS-D), the official Amazon Kubernetes distribution, which includes the same secure, validated, and tested components that power Amazon EKS. Splunk Infrastructure Monitoring provides a turn-key, enterprise-grade Kubernetes monitoring solution for Amazon EKS. Additionally, Splunk Infrastructure Monitoring provides out-of-the-box monitoring of Kubernetes Control Plane. With Splunk’s support for EKS-D, our joint customers can confidently run Kubernetes in all environments – cloud-native with Amazon EKS, hybrid with Amazon Outposts and on-premises self-managed environments.
Kubernetes Navigator provides an easy and intuitive way to understand and manage the performance of Kubernetes worker nodes and deployed applications. In a previous blog, we covered how DevOps and SRE teams can detect, triage and resolve performance issues in Kubernetes environments faster than ever before by taking advantage of the following features:
Additionally, in a self-managed EKS-D environment, DevOps teams need real-time visibility and accurate alerting on key performance metrics of Kubernetes Control Plane.
In this blog, we will focus on monitoring Amazon EKS-D Control Plane with Splunk Infrastructure Monitoring.
Every Kubernetes cluster consists of one or more worker nodes where containerized applications get deployed, as well as the control plane, which is responsible for the management of the worker nodes. The control plane makes scheduling decisions such as which pod is deployed to which worker node, monitors the cluster and manages the desired state of the Kubernetes cluster.
Splunk provides out-of-the-box telemetry for Kubernetes internals, including components that make up the control plane, as well as those running on the worker nodes in addition to key add-ons. Monitoring these components enables rapid troubleshooting of issues related to scheduling, orchestration and networking of Kubernetes clusters:
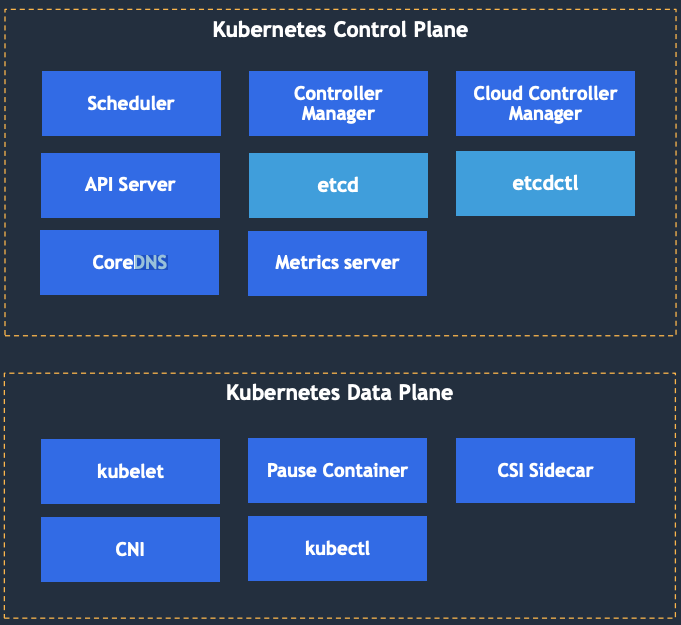
Fig: Amazon EKS Distro (EKS-D) components
Kubernetes is a distributed system, and all the components mentioned above communicate only with the API server which orchestrates various lifecycle events for deployed applications. Kubernetes consists of persistent entities called Kubernetes Objects which represent the state of Kubernetes clusters. These objects include:
The API server acts as a central hub for all Kubernetes components and clients, such as kubectl and automation tasks that interact with the cluster. The API server provides a CRUD (Create, Read, Update, Delete) interface for querying and modifying the cluster by implementing RESTful APIs over HTTP. API server stores the state of the cluster in etcd, a distributed storage system, after performing validation of CRUD requests so clients can’t store improperly configured objects. Along with validation, the API server also handles authentication, authorization and optimistic locking so allowed changes to an object don’t override other clients in the event of concurrent updates. The API server uses various plugins to accomplish these tasks.
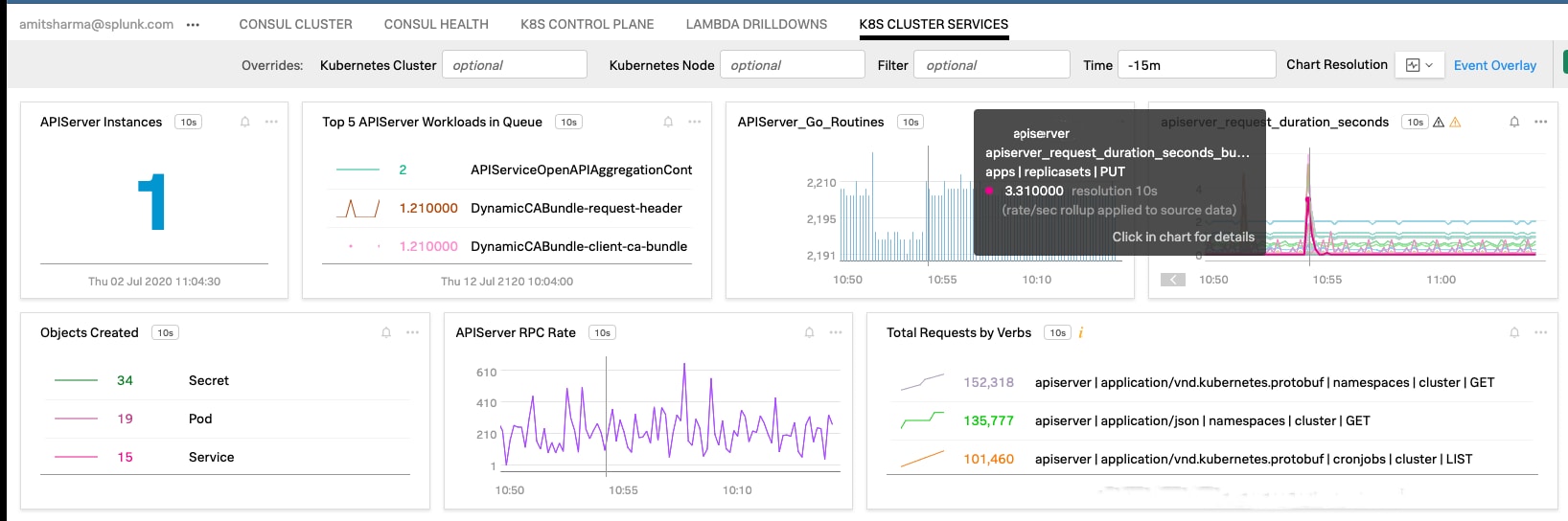
Fig: OOTB dashboard visualizing Kubernetes API Server health and performance
Since every interaction with the cluster goes through the API server, it’s especially important to monitor the API server’s health and performance characteristics. Splunk automatically collects metrics and provides out-of-the-box dashboards to visualize the internal state, such as the number of concurrent threads, goroutines, RPC rate, etc., as well as the depth of the registration queue, which tracks queued requests and can tell us if the API server is falling behind in fulfilling requests. We can take the four golden signals approach to monitor the Kubernetes API server health and performance:
The controller manager runs controllers to ensure the actual state of the cluster converges toward the desired state. The desired state is specified by the DevOps teams to the API server via various resource spec files. For example, the node controller manages node resources by monitoring the health of each node in the cluster and gracefully evicting pods from nodes that are unreachable. Similarly, the replication controller reconciles the difference between the actual number of pods running in the cluster with the desired count. The health of the controller manager indicates how the cluster is performing.
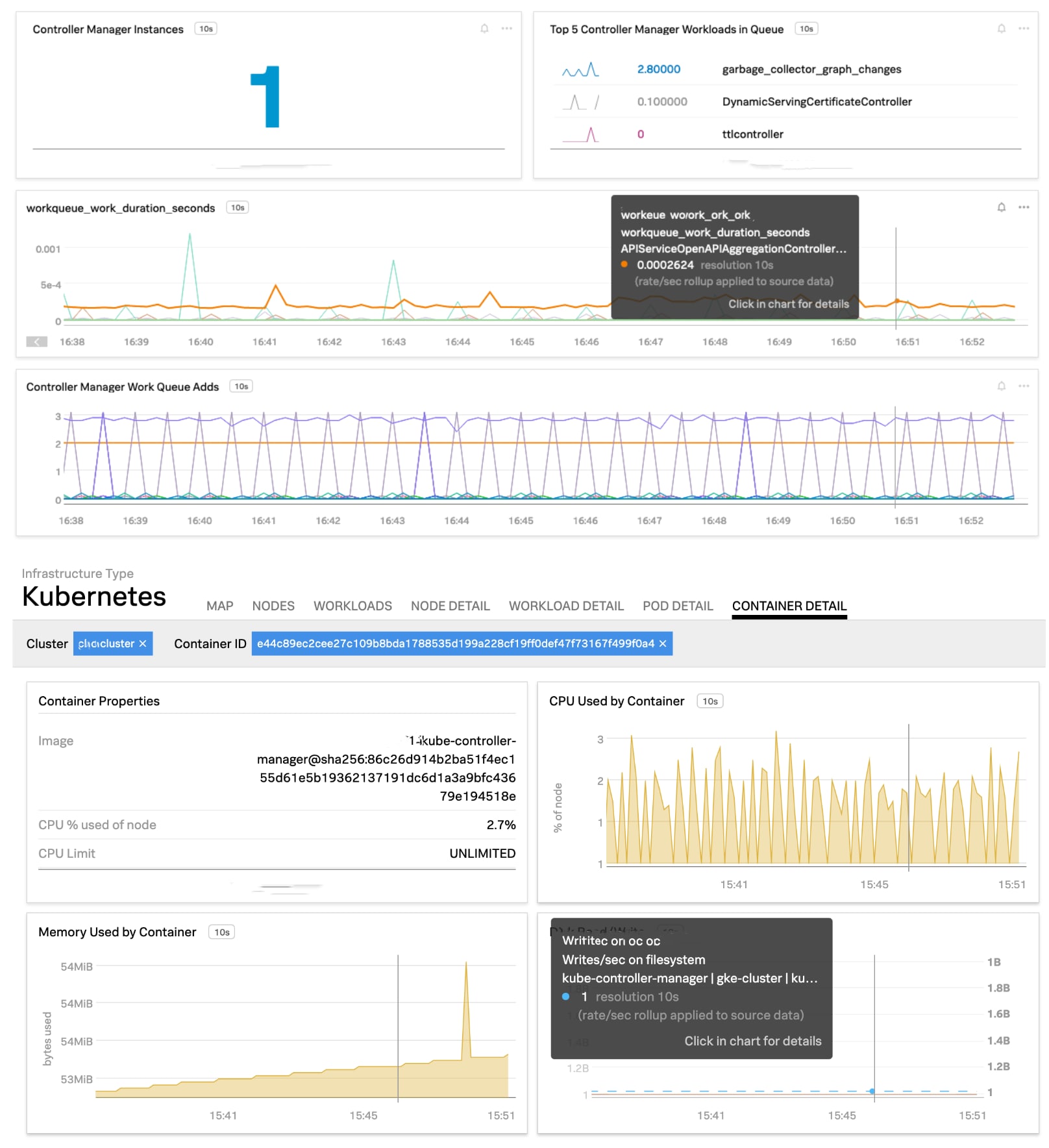
Fig: OOTB dashboard for Controller Manager performance
The controller manager dashboard gives visibility into the work queue where requests such as replication of a pod are placed before they’re worked on. You can also monitor the latency to process the requests, the number of HTTP requests from the manager to the API server to help ensure healthy communication between these two components. Additionally, it’s important to monitor the saturation of the container running controller manager to ensure that enough CPU, memory and disk resources are available. The entire list of performance metrics for the controller manager is available in the documentation.
Etcd is a distributed key-value store for persisting the state of the cluster. The service persists cluster state and provides information about running Kubernetes objects. Etcd uses Raft consensus algorithm. If this service becomes unavailable, existing pods will keep running but any change cannot be made to the state of the cluster. Further, inconsistencies will occur as Kubernetes API server reconnects with etcd.
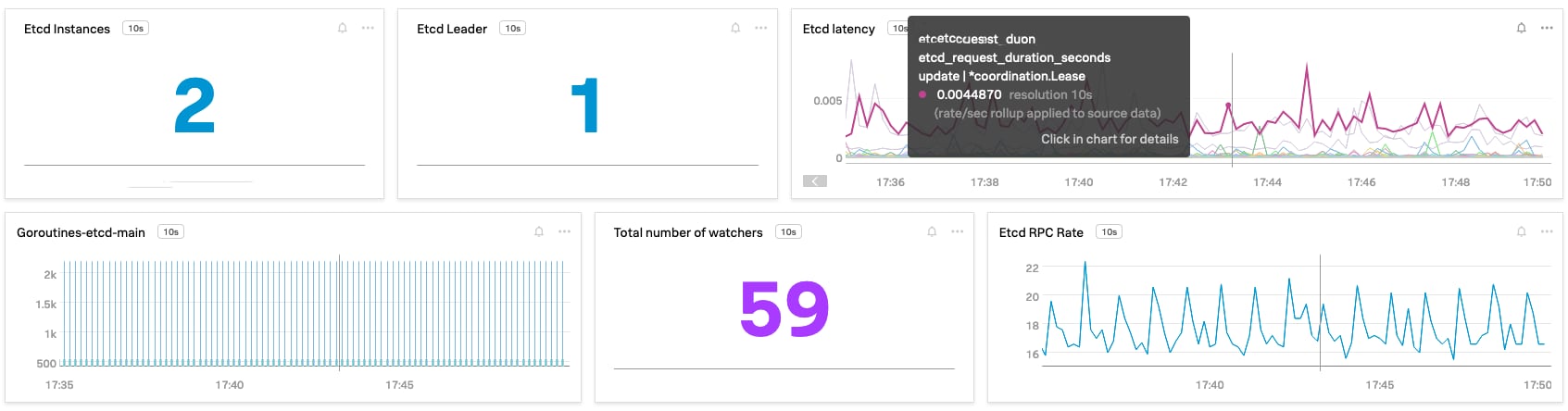
Fig: OOTB dashboard for etcd performance insights
It’s important to monitor for an etcd cluster leader In case the node on which the leader is running fails, Raft will negotiate a new one, and a leadership change event will occur. In general, frequent leadership changes can point to a systematic issue. You can also monitor latency for various proposals and alert on failed proposals (proposals_failed_total), indicating a cluster-wide issue. Monitor the number of watchers (etcd_debugging_mvcc_watcher_total) using which Kubernetes subscribes to changes within clusters and executes any state request coming from the API server.
DevOps teams usually don’t specify which node a pod should run on. This is delegated to the scheduler, which assigns a node to each new pod that doesn’t already have a node. On the surface, this functionality looks trivial. However, the scheduler isn’t making the decision randomly. The scheduler uses sophisticated algorithms to determine the best available node to run a particular pod and it maintains a list of all available nodes and performs various checks:
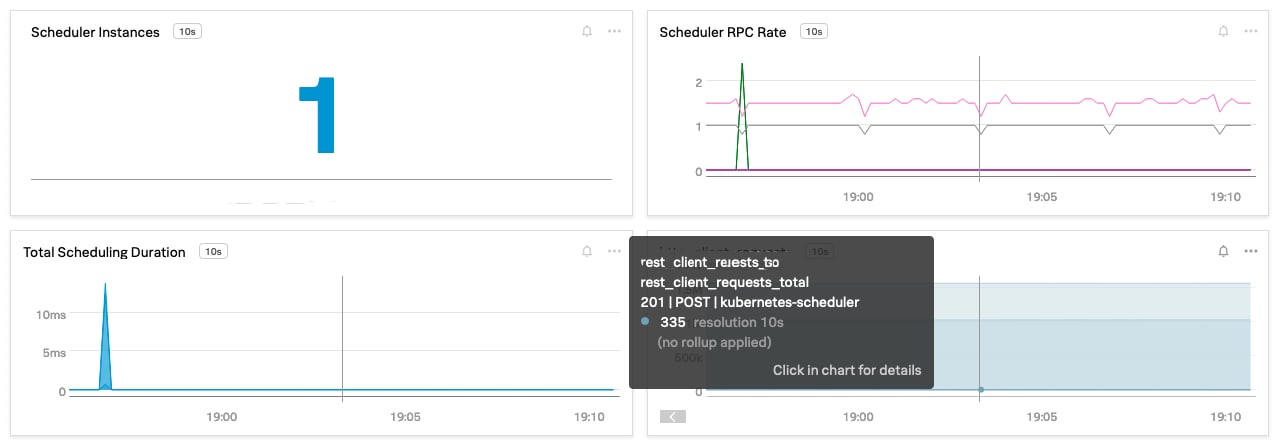
Fig: OOTB dashboard for Kubernetes Schedler performance insights
Pre-built Kubernetes Scheduler dashboard gives visibility into client requests made to the scheduler with types of operations (verbs) and status code. You can put an alert to non-200 HTTP response codes or high values compared to historical baselines on total scheduling duration (scheduler_binding_duration_seconds), indicating a performance issue with Kubernetes scheduler.
CoreDNS is a flexible, extensible DNS server that can also provide service discovery for microservices-based applications deployed in the Kubernetes cluster. CoreDNS chains plugins. Each plugin performs a DNS function such as Kubernetes service discovery, Prometheus metrics and more. Most of the plugins emit telemetry data via the Prometheus plugin. You can also write a custom plugin and enable monitoring as described in the example plugin. Splunk Smart Agent can transparently collect performance metrics by configuring CoreDNS monitor.
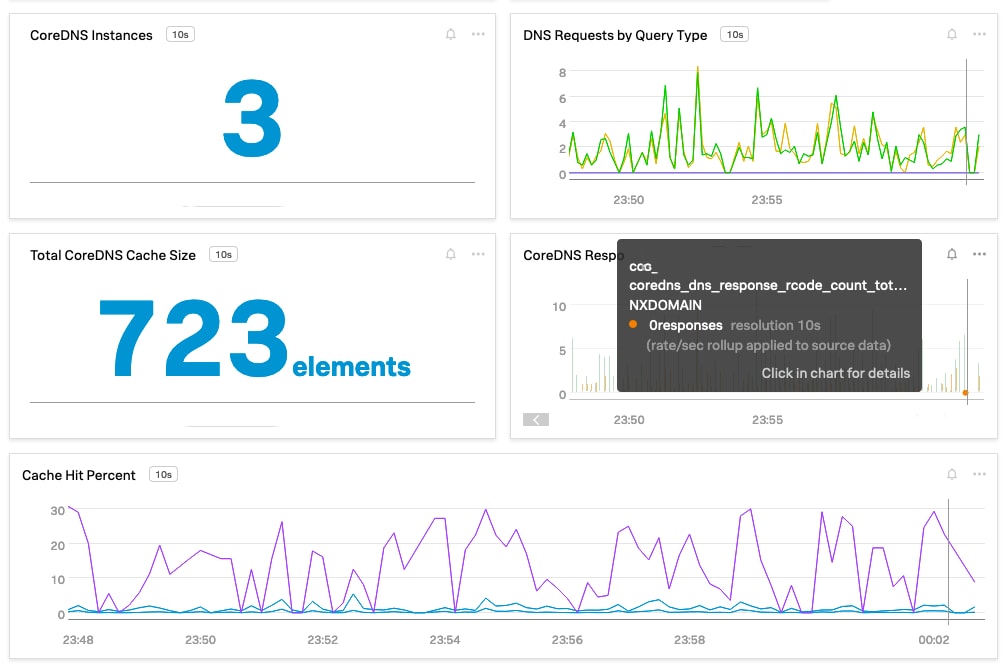
Fig: OOTB dashboard for CoreDNS performance metrics
A pre-built dashboard provides visibility into the health of CoreDNS infrastructure and its functionality. You can monitor DNS requests per record type (coredns_dns_request_type_count_total), indicating how busy CoreDNS is. You can monitor cache size and percentage hits from the cache, as shown above, and increase the time to live (TTL) value in ConfigMap via Corefile, allowing records to be kept in the cache for longer periods. Monitor errors by keeping track of return codes (rcodes). For example, NXDomain represents issues with the DNS request and results in the domain not found, while ServFail or Refused indicates issues with the DNS server – CoreDNS in this case.
Splunk Infrastructure Monitoring provides comprehensive Kubernetes monitoring in all environments including AWS managed Kubernetes – Amazon EKS as well as on-premises and hybrid self-managed EKS-D deployments.
Sign up for a free trial of Splunk Infrastructure Monitoring to get started with end-to-end Kubernetes monitoring.
----------------------------------------------------
Thanks!
Amit Sharma

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
