
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
Modern IT & DevOps teams face increasingly complex environments — making it harder to quickly detect and resolve critical issues in real-time. To overcome this challenge, Splunk users can take advantage of ML-powered IT monitoring and DevOps solutions available in a scalable platform with state-of-the-art data analytics and AI/ML capabilities. In this blog, we deploy Splunk’s built-in Streaming ML algorithms to detect anomalous patterns in error logs in real-time. Breaking it down into simple steps, we walk you through how to use out-of-the box Splunk capabilities to ingest logs, pre-process the data, apply real-time ML, and visualize results. Let’s dive in!
Anomaly detection allows organizations to identify patterns and detect unusual events in streams. Whether it’s detecting fraudulent logins, alerting on spikes in KPI metrics, or identifying unusual resource consumption, anomaly detection can be used to identify deviations from expected, normal patterns in data — providing IT and DevOps teams with early indication of potential operations issues.
Many industries are facing explosions in data volumes and complexity posing a big challenge to IT organizations. Consider the telco industry, which is projected to reach 77.5 exabytes of mobile data traffic a month worldwide. Managing these rapidly growing environments through a static, rules-based approach is insufficient. Modern DevOps teams increasingly rely on AI/ML based anomaly detection solutions when monitoring for unknown unknowns, reducing alert fatigue, or generating insights from application logs. Broadly speaking, these can be grouped into — predictive analytics, intelligent alerts, and troubleshooting / incident remediation. In this blog, we explore how the Splunk Machine Learning Environment (SMLE) can be used to more accurately identify anomalous error windows in application server logs to reduce the number of events that require manual review.
As you may know, Splunk’s Machine Learning Toolkit (MLTK) has enabled users to build anomaly detection solutions with a traditional approach of training models against historical data, or with statistical analysis methods. Splunk’s newest ML product, Splunk Machine Learning Environment (SMLE), offers a real-time anomaly detection solution with state-of-the-art AI/ML and streaming analytics capabilities that learn and predict on the stream.
With SMLE, a simple and intuitive workflow to build an anomaly detection solution includes four steps:
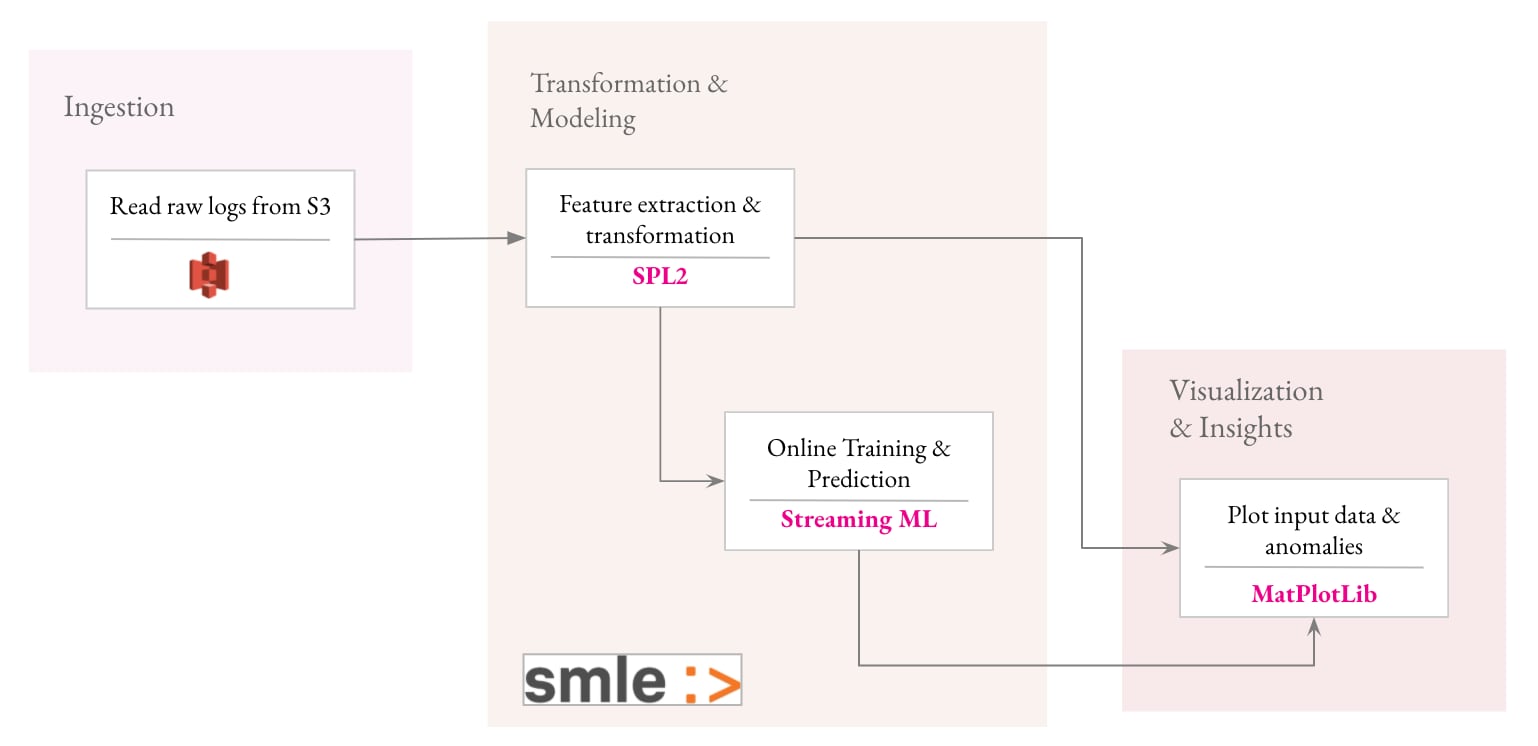 Step 1: Streaming Data From Server Logs Using SPL2
Step 1: Streaming Data From Server Logs Using SPL2
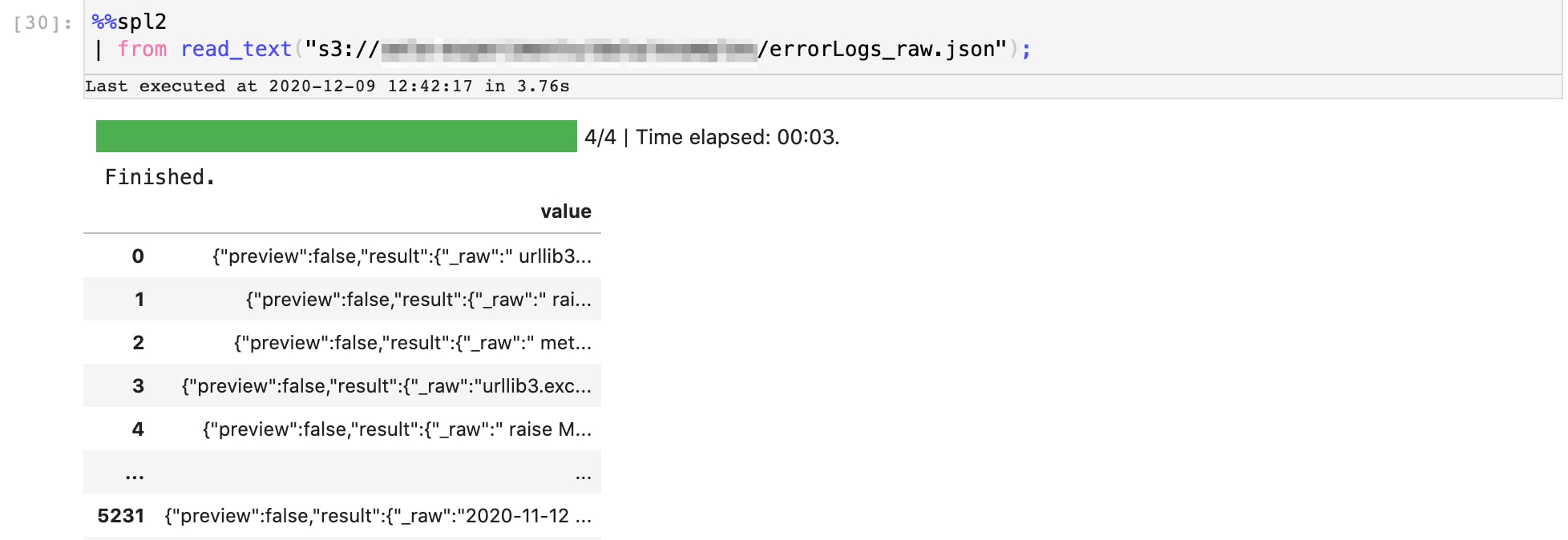
Let’s start with streaming the data into our pipeline. In our example, we pull data from an AWS S3 bucket where we’d uploaded a week’s worth of raw server logs. Here’s our SPL2 data pipeline that brings data in from the S3 bucket into our Jupyter notebook environment. The output is a series of raw logs.
Step 2: Extract features and transform data using SPL2 operators
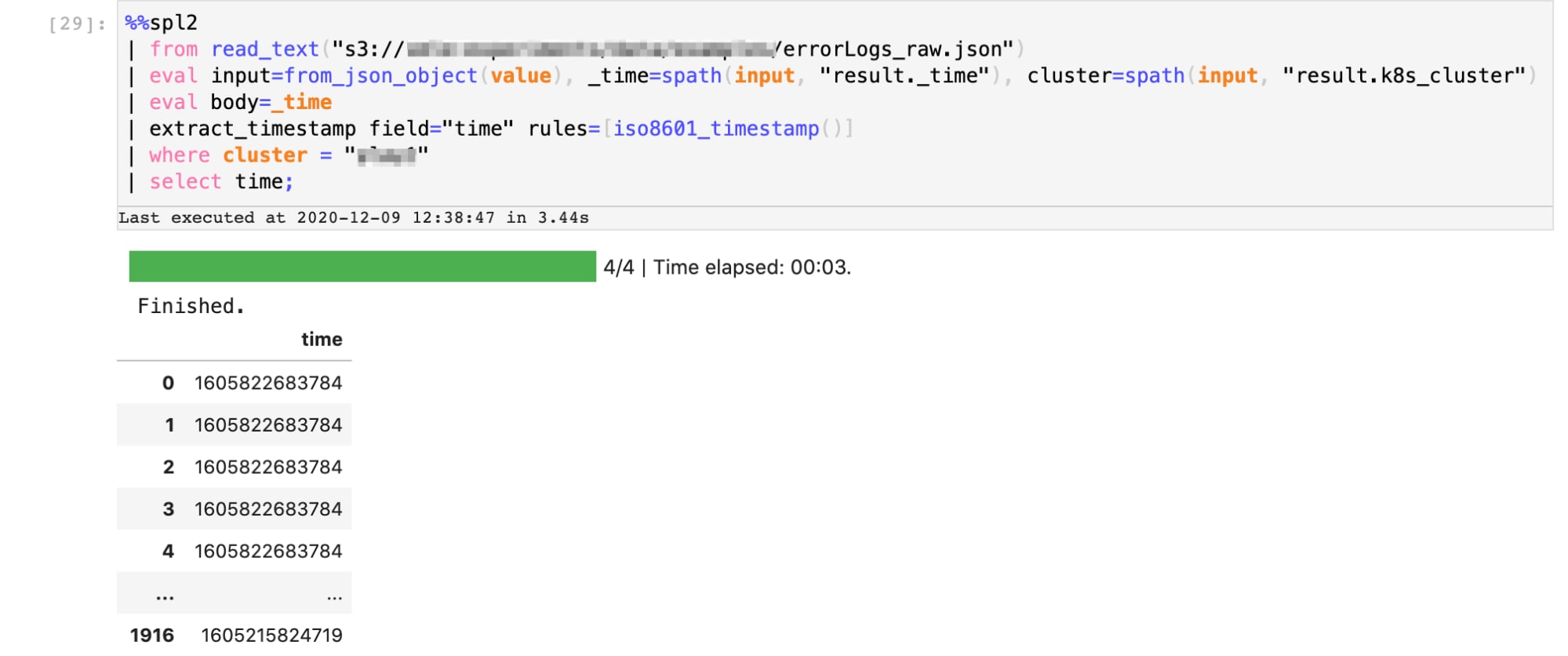
Once we have the raw data, we’ll use a series of simple SPL2 operations to extract the relevant features, and transform the data in order to identify anomalous patterns.
In this phase, we’ll perform 2 steps:
Here’s our SPL2 data pipeline that performs the first extraction sequence. The output is a series of timestamps at which errors were reported in the server logs.
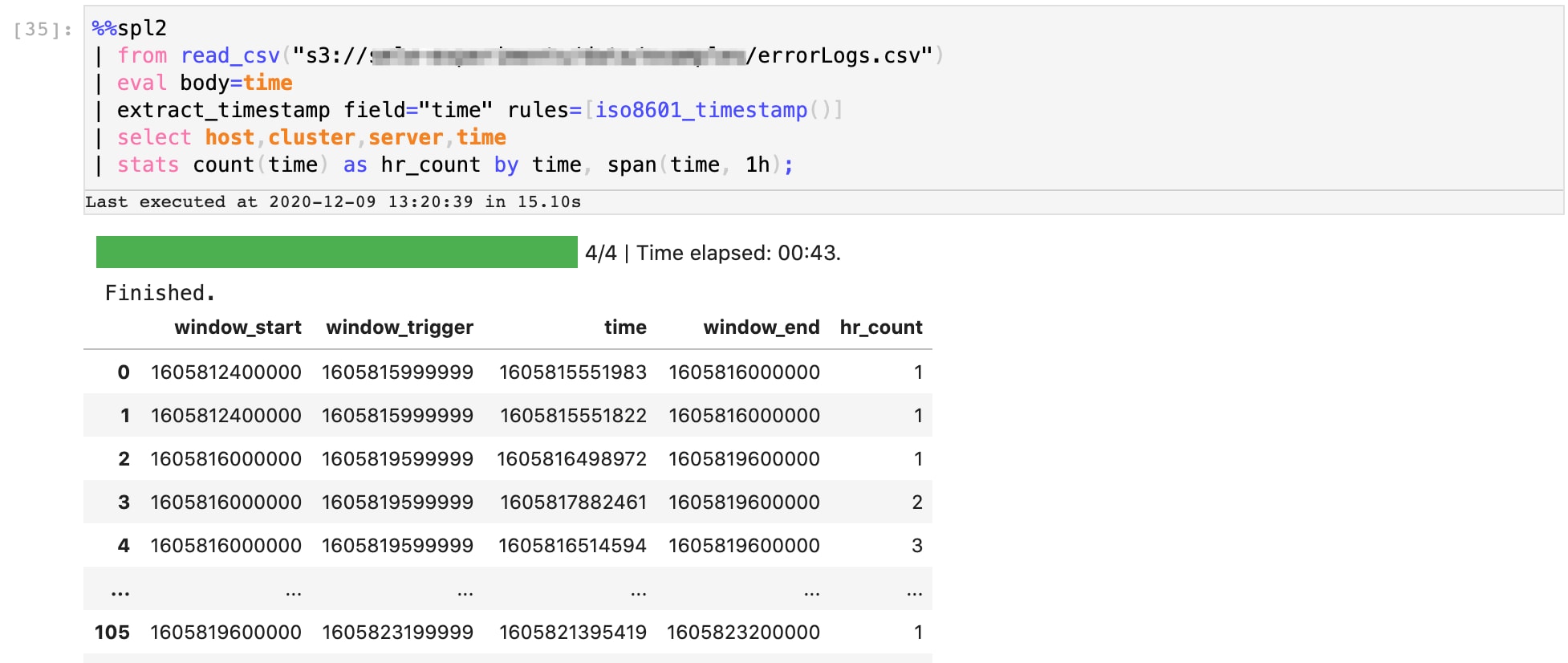
Next, we aggregate these timestamps by windows of 1 hour each. Here’s an extension of the SPL2 pipeline that performs this operation. The output includes a new column ‘hr_count’ which indicates how many errors occurred within that hour of day across the week.
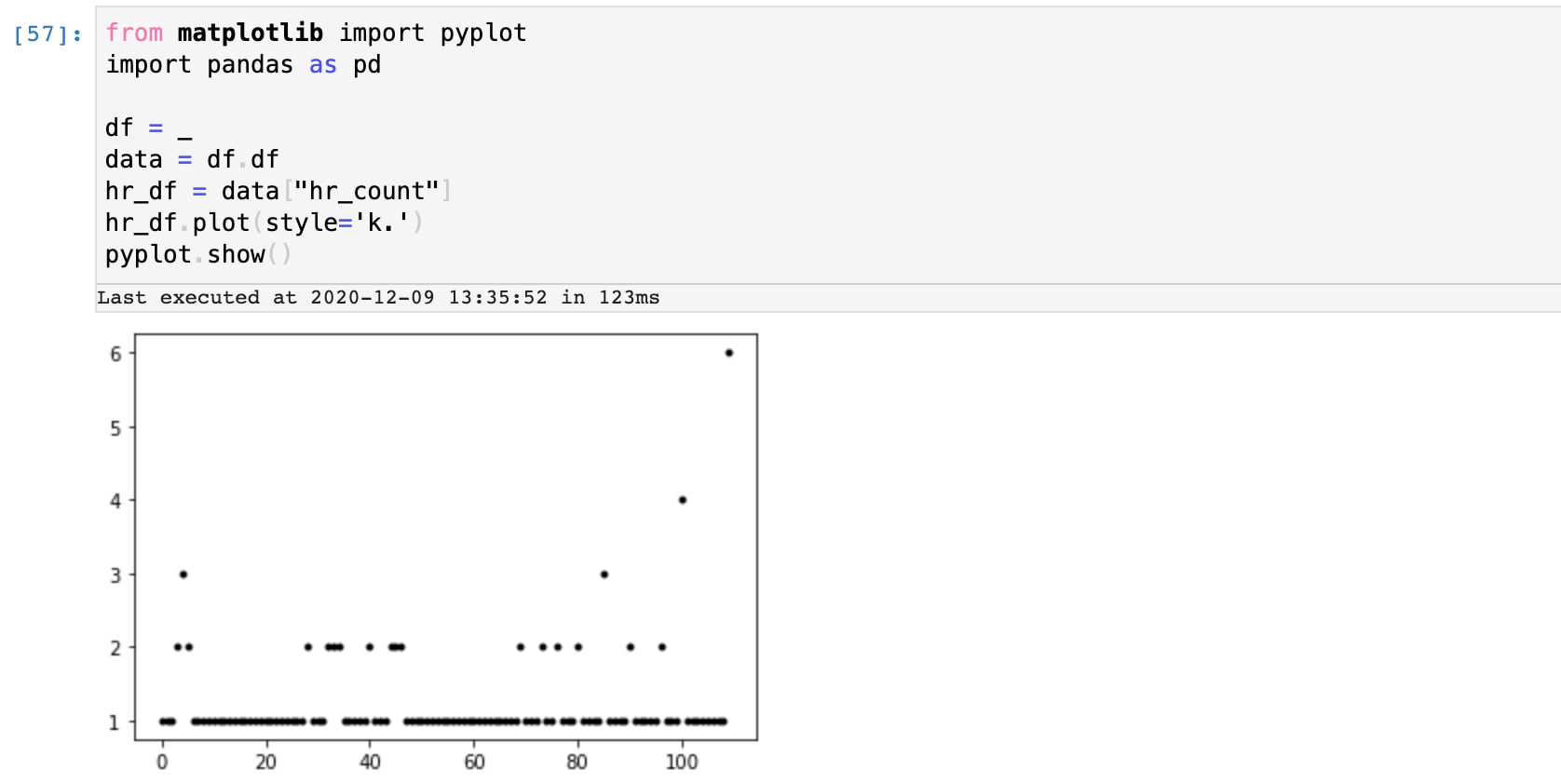
Let’s plot these counts to get a sense of what’s normal and what counts are potential outliers. Using a simple python script embedded into the SPL2 Jupyter notebook, we can sample the output to see that there are likely a few outliers at counts 3 and above.
Step 3: Use Streaming ML algorithms to apply adaptive thresholds in real-time
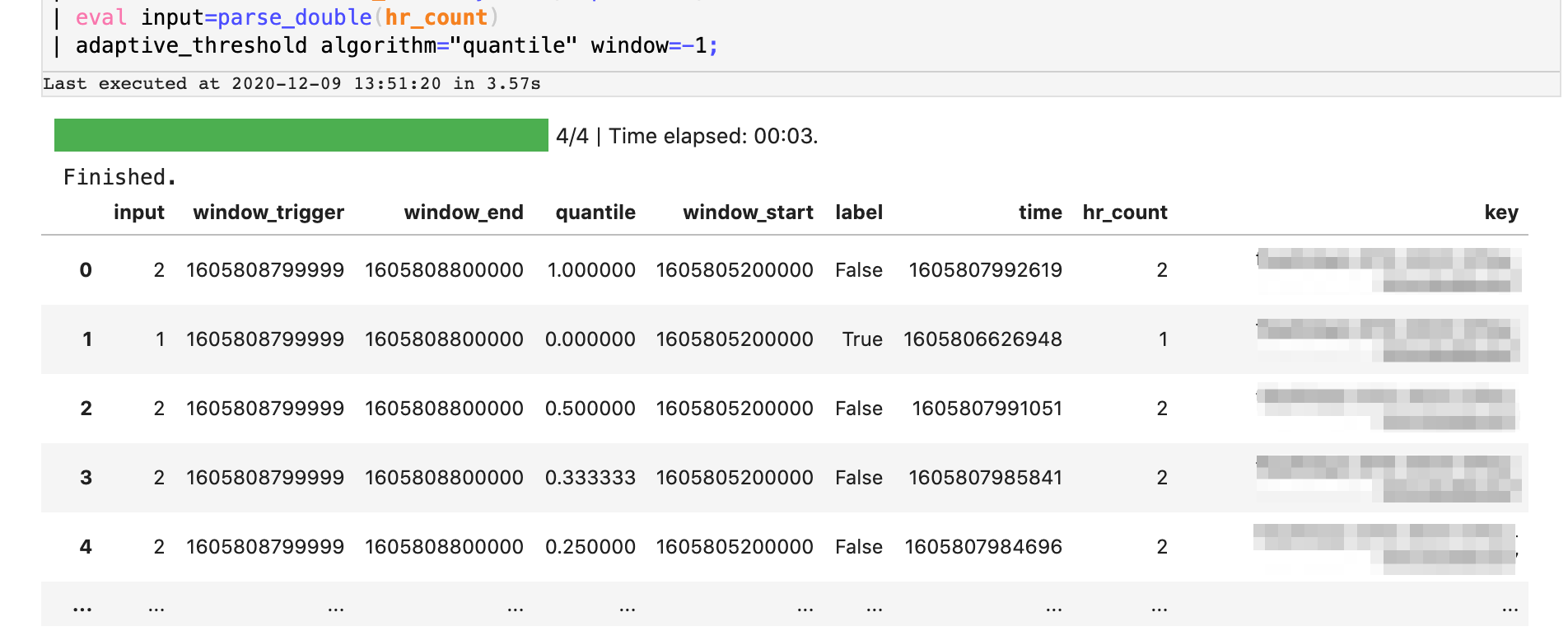
Next, we’ll use Splunk’s built-in algorithm to perform adaptive thresholding in real-time using the ‘quantiles’ method. This operation profiles the stream in real-time and assigns a rank order for each value in the distribution. In essence, the algorithm determines the likelihood of a particular value occurring in that stream and outliers correspond to observations that fall outside a threshold, for example the 99th percentile. We’ll use this quality to identify error counts that are unlikely, and thus are anomalous. Here’s an extension of the SPL2 data pipeline we’ve built so far. We’ll use the adaptive_threshold operator on the data pipeline to stream in the window counts which then emits a series of ‘quantile’ values for each record as it learns from the stream.
Step 4: Extract Insights
The threshold values emitted as the output of our data pipeline indicate the likelihood of finding another similar value in the stream. For the anomaly detection use case, we’ll apply a percentile threshold to filter out anomalous windows and use simple visualizations with Python to plot those anomalies.
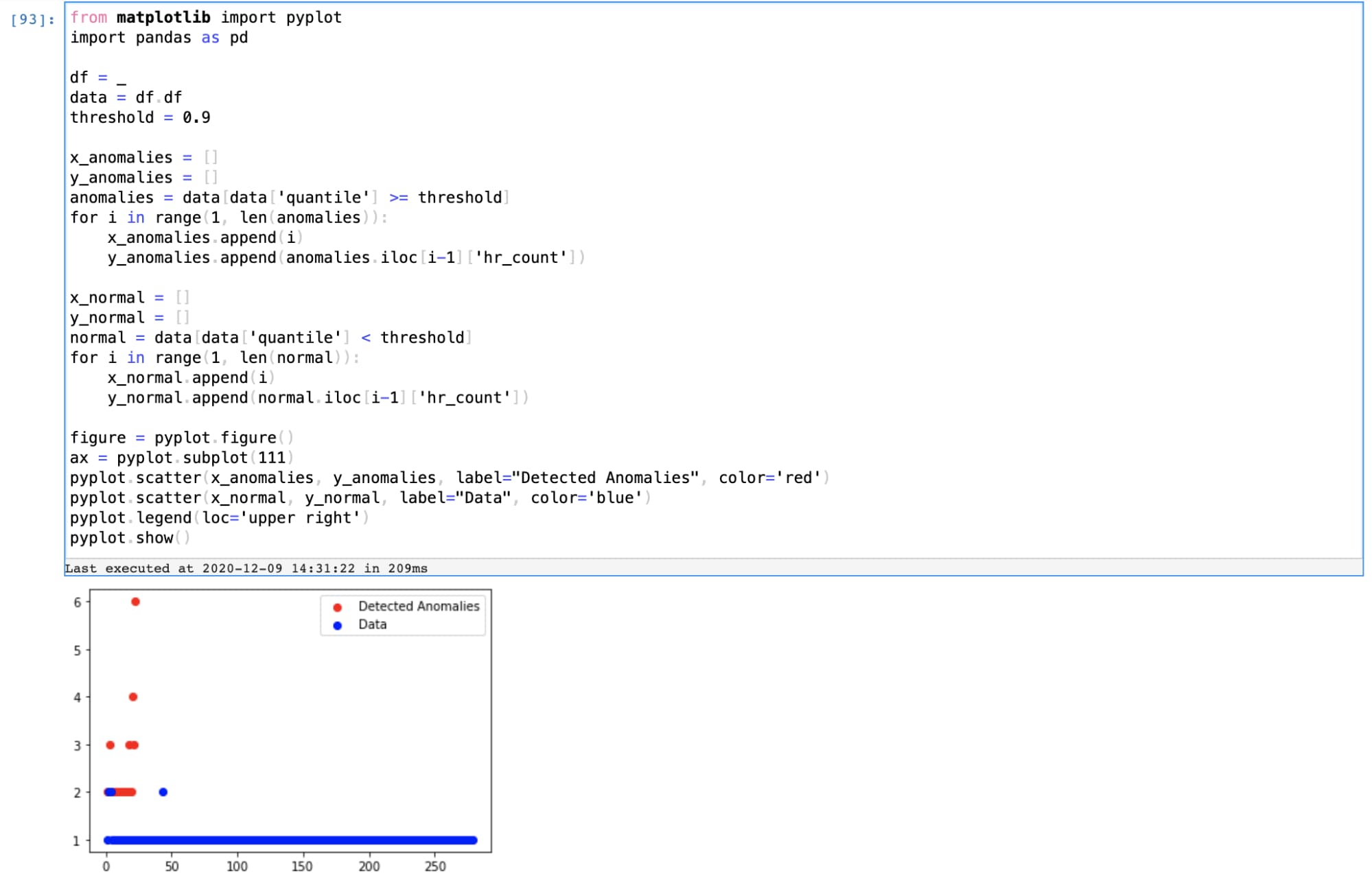
The insights identified are only as good as the business value they enable. To make insights actionable, Splunk’s AI/ML platform provides capabilities to build dashboards to detect these anomalies, create alerts, and workflow operations to respond to these alerts.
We demonstrated one solution for anomaly detection above using SMLE. SMLE (Splunk ML Environment) is a platform to build and deploy ML at scale from within the Splunk ecosystem. By extending the features of Splunk that customers love with a suite of data science and operations capabilities, SMLE allows Splunk users and data scientists to collaborate on building solutions that involve a combination of SPL and ML libraries. The beta version of the SMLE platform is available to interested users who can sign up here and read more about our offerings and announcements here.
Using Streaming ML on the SMLE platform, you got to see how to build a simple, real-time anomaly detection solution to overcome operations challenges for IT/DevOps users. With a combination of powerful and easy-to-use SPL2 operators and flexibility of popular programming languages like Python, SMLE allows users to construct entire workflows with a sequence of SPL2 and ML operations. Stay tuned for more use case driven examples with SMLE...
Interested in trying SMLE? Sign up for our beta program!
This Splunk Blogs post was co-authored by Vinay Sridhar, Senior Product Manager for Machine Learning, and Mohan Rajagopalan (main author), Senior Director of Product Management for Machine Learning.
----------------------------------------------------
Thanks!
Mohan Rajagopalan

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
