
Digital Resilience Pays Off
Download this e-book to learn about the role of Digital Resilience across enterprises.
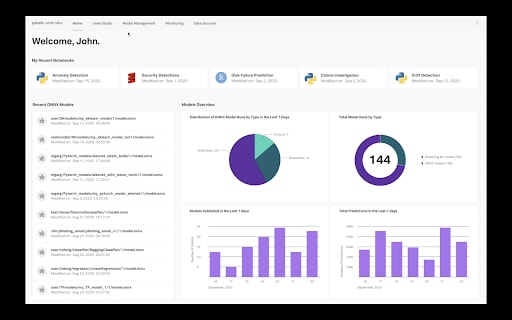
 The Machine Learning (ML) team at Splunk has been very busy in 2020. We’ve introduced new functionalities to apps like the Machine Learning Toolkit, showcased new domain-specific Smart Workflows, and brought our users ML-powered experiences to our IT and security products.
The Machine Learning (ML) team at Splunk has been very busy in 2020. We’ve introduced new functionalities to apps like the Machine Learning Toolkit, showcased new domain-specific Smart Workflows, and brought our users ML-powered experiences to our IT and security products.
These features and tools work great for users looking for some assistance with their ML journey, whether they want to take advantage of step-by-step guidance for building models or are looking for out-of-the-box automated solutions. However, we’ve also heard the feedback that many NOC and SOC use cases require even more advanced support. With the volume of data ever increasing, customers are looking for new ways to experiment, yet data egress is complex and operationalizing ML models can be challenging to say the least.
We take customer input seriously and today, we are very excited to introduce a beta of our new Splunk Machine Learning Environment (SMLE). Pronounced “smile,” this environment was purpose-built to fill a gap when it comes to building and operationalizing machine learning models at scale and we hope it will bring joy to our users, both old and new.
The first benefit of the SMLE platform is that it will bring Jupyter notebooks into the Splunk platform. This will allow users such as Splunk admins to combine SPL with ML models developed in commonly used data science languages such as R, Python, and Scala, opening up the world of Splunk to data scientists who may be unfamiliar with SPL and bringing even more advanced data capabilities to core Splunk users and admins. Not only will this integration make available multiple programming languages to our users, but it will also enable and facilitate collaboration between teams. With tools, algorithms, and runtimes like PyTorch, TensorFlow, Rapids, and others baked in to the platform, we’ve married two worlds — one familiar to the SPL ecosystem and one familiar to the data science community — in a way that prioritizes ease of use. SOC and NOC teams will now be able to share data, code, algorithms, and models with their data science and ML engineering teams and vice versa, opening up new possibilities to leverage intelligence in operations.
SMLE Labs, our beta environment, is now available for customers looking to experiment.
After teams experiment and create new models, they will be able to operationalize in SMLE with just one click. SMLE also allows users to deploy, manage and monitor models from a single environment. Furthermore, automated monitoring and management of models frees up time for ML engineers to focus on higher priority tasks. 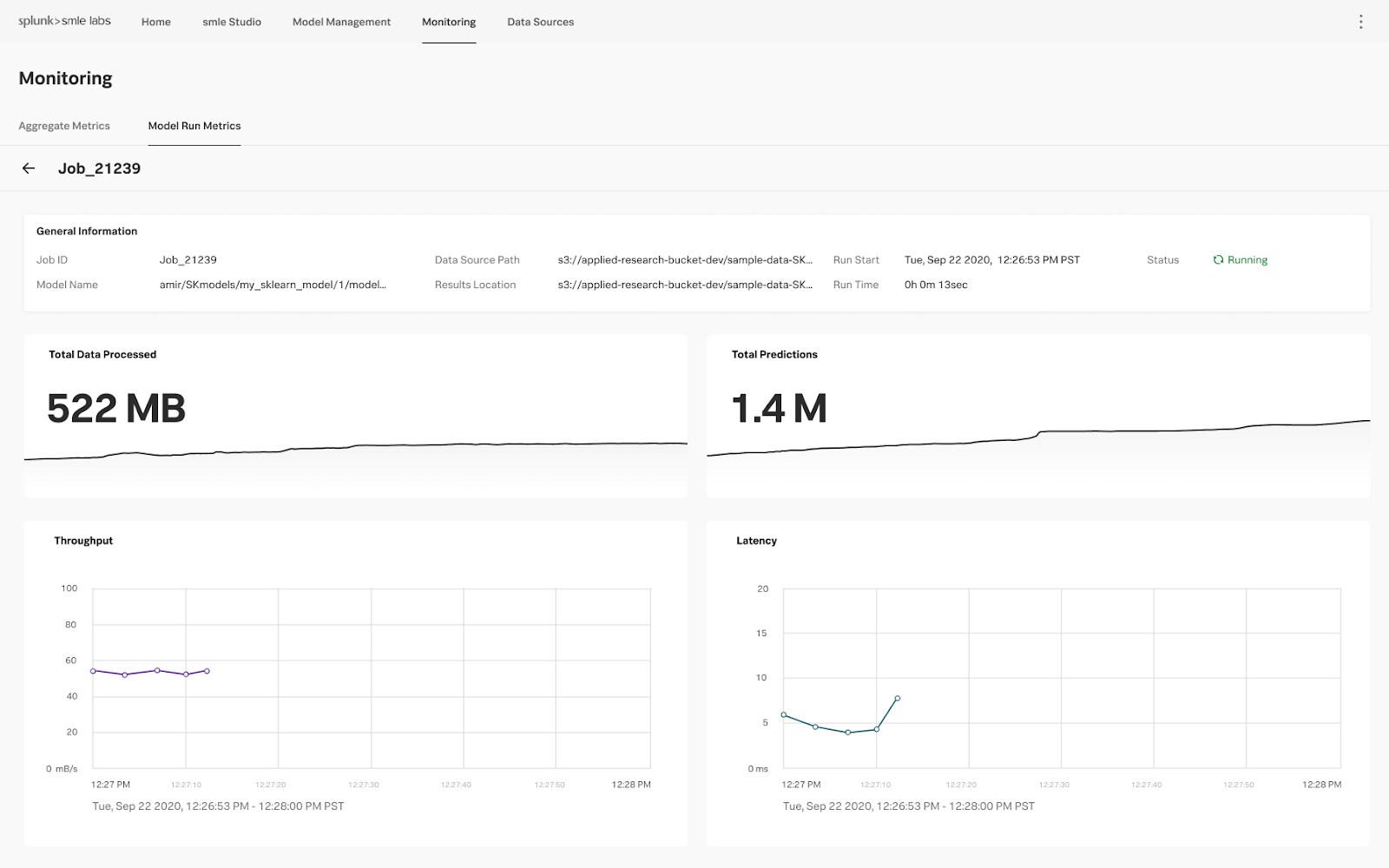
SMLE will afford users the ability to bring the power of compute directly to their data, eliminating the need to egress data and, ultimately, resulting in faster time to insight. SMLE will also include the latest innovations in Streaming ML. Rather than exporting your data to perform offline batch model development and training, Streaming ML was built and optimized for online streaming data analytics, enabling you to uncover insights faster than ever.
For those interested in giving SMLE a try, SMLE Labs, our trial environment, is now seeking participants for the closed beta. Please visit the Splunk ML Environment (SMLE) Labs Beta page to sign up!
Follow all the conversations coming out of #splunkconf20!
----------------------------------------------------
Thanks!
Mohan Rajagopalan

The Splunk platform removes the barriers between data and action, empowering observability, IT and security teams to ensure their organizations are secure, resilient and innovative.
Founded in 2003, Splunk is a global company — with over 7,500 employees, Splunkers have received over 1,020 patents to date and availability in 21 regions around the world — and offers an open, extensible data platform that supports shared data across any environment so that all teams in an organization can get end-to-end visibility, with context, for every interaction and business process. Build a strong data foundation with Splunk.

Get the latest articles from Splunk straight to your inbox.
© 2005 - 2024 Splunk Inc. All rights reserved.
